CoT推理的天花板在哪?港大ICML 2026论文证明:超过20步,LLM就该放弃思考、改用工具
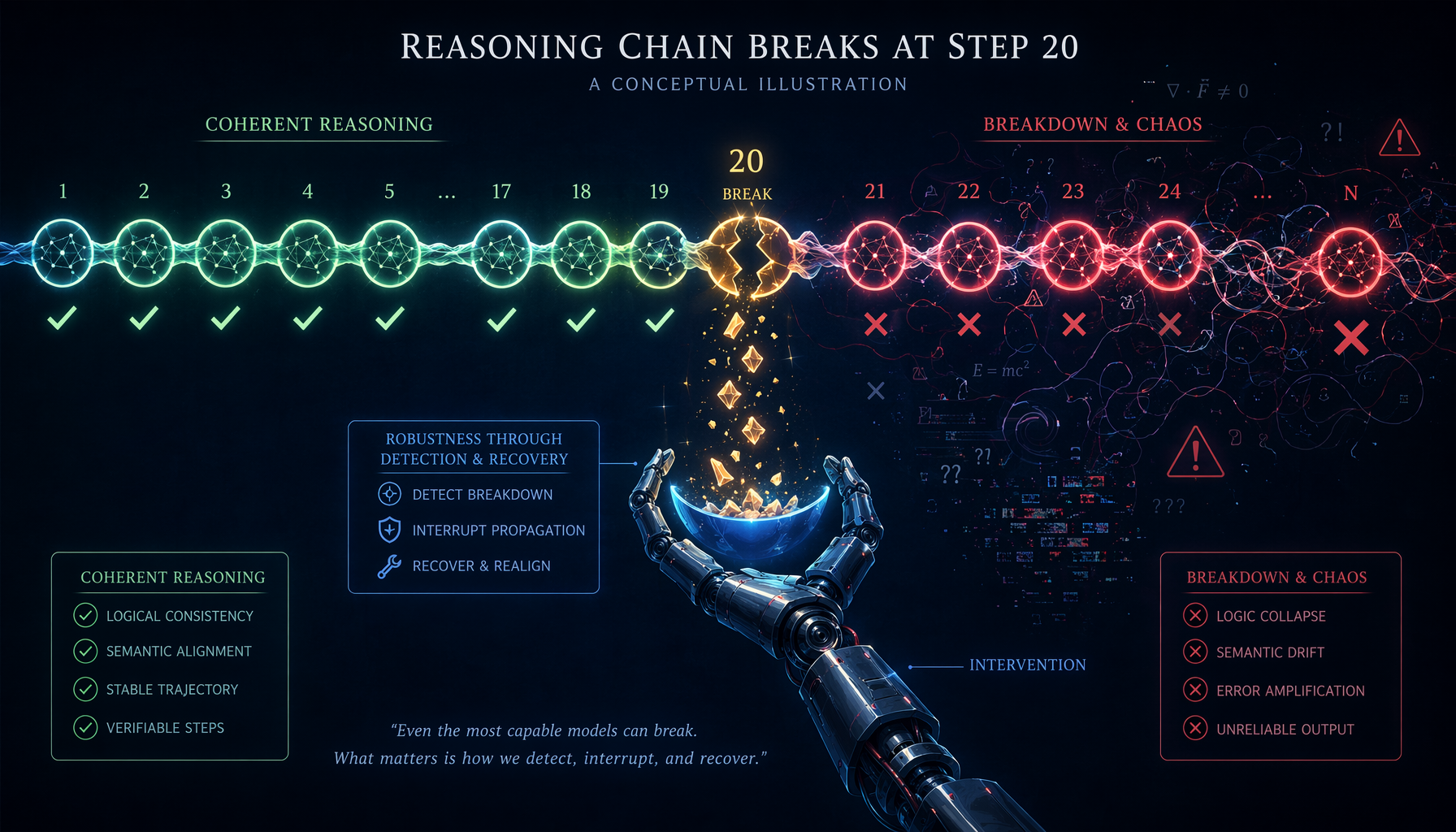
最近翻到一篇港大的论文,标题是"The Deterministic Horizon: When Extended Reasoning Fails and Tool Delegation Becomes Necessary",ICML 2026的。说实话,这标题挺唬人的——“确定性地平线”,听着像物理学概念。
但读完全文之后我觉得这可能是今年对Agent开发者最有实操指导价值的一篇理论论文。核心结论一句话:
LLM的链式推理存在一个硬性上限,大约20-31步。超过这个深度,不管你用o3还是DeepSeek-R1,不管你怎么prompt、怎么微调,准确率都会崩盘。唯一的出路是把计算委托给外部工具。
这个结论直接影响了我对Agent系统的设计思路。下面详细说说这篇论文到底做了什么。
起因:思考越多,反而越错?
我们现在的主流范式是——想让LLM干难事,就让它多想想。o1/o3系列靠长CoT取得了巨大进步,DeepSeek-R1也是走这条路。
但作者发现了一个违反直觉的现象:在确定性状态跟踪任务上(比如汉诺塔、滑块谜题、程序状态追踪),延长推理链非但不能帮忙,反而会让结果更差。
具体的数字长这样:
| 推理深度 | 准确率(平均) |
|---|---|
| 10步 | 78% |
| 30步 | 34% |
| 50步以上 | 接近随机猜 |
你可能觉得——那是模型太弱了吧?换o3试试?
换了。o3-mini在汉诺塔31步问题上的准确率是22.4%,加上extended reasoning烧了平均18000个token,还是只有22.4%。同一个问题让BFS搜索做,0.1秒搞定,100%准确。
这不是模型弱的问题。这是架构的硬伤。
为什么会这样?信息论给出了答案
论文的核心理论贡献是证明了Decoder-only Transformer的注意力机制存在一个信息瓶颈。
这东西的直觉是这样的:假设你在做一个25步的汉诺塔问题。每一步你都需要准确记住当前三根柱子上所有圆盘的位置。到了第20步的时候,前面19步的中间状态都还在context里——但注意力的softmax在一个很长的序列上分布后,留给每个历史token的权重已经非常稀薄了。
更要命的是,这个稀薄是随深度递增的。论文把每一步的错误率建模成:
$$\epsilon(d) = \epsilon_0 + \frac{\gamma \cdot d}{L_{eff}}$$
ε₀是基础错误率,γ是衰减系数,L_eff是"有效退相干长度"。注意这里的L_eff远小于context window长度——GPT-4o有128K的context,但它的L_eff大约只有150步。
这意味着错误率不是恒定的,而是随着推理深度线性增长。
那么d步全对的概率呢?
$$P(\text{d步全对}) \leq \exp\left(-d\epsilon_0 - \frac{\gamma d(d+1)}{2L_{eff}}\right)$$
关键在那个d²项——这是个二次衰减,导致成功概率是超指数衰减的。不是指数衰减,是比指数衰减还快。
打个比方:如果每一步的错误率是恒定的2%,那100步全对的概率是0.98^100 ≈ 13%,还凑合。但如果错误率从2%线性增长到10%,100步全对的概率会降到接近0。这就是"超指数"的含义。
“确定性地平线"d*到底是多少
把上面那个公式设成50%的成功概率,解出来的深度就是"确定性地平线"d*。
论文在12个模型上实测了d*:
| 模型 | d*(汉诺塔) | d*(Blocksworld) |
|---|---|---|
| Llama-3.1-8B | 6 | 7 |
| Llama-3.3-70B | 9 | 12 |
| GPT-4o | 12 | 16 |
| o3-mini | 20 | 22 |
| DeepSeek-R1 | ~18 | ~20 |
几个关键观察:
第一,d*跟模型大小的关系是亚线性的。 参数量涨100倍,d才涨2-3倍。按这个趋势外推,10万亿参数的模型d也就到30左右。这说明你不能靠堆参数来解决这个问题。
第二,d*跟context window长度几乎无关。 Gemini 1.5 Pro有100万的context,但d*并没有比GPT-4o高多少。这点很反直觉——你可能以为"context够长就能记住所有中间状态”,但问题不在能不能记,而在注意力能不能有效地从长context中提取正确信息。
第三,d的公式里包含一个跟架构相关的项:d ∝ √(d_h · H),其中d_h是每个头的维度,H是头的数量。这意味着注意力头越多、维度越大,d*越高。o3比GPT-4o高是因为extended reasoning实际上增加了有效的L_eff(通过内部验证循环)。
微调能救吗?——不能
最刺激的实验之一:他们在最优解traces上微调了Llama-3.1-8B,看能不能学会更深层的推理。
结果是:d以下的深度有所提升(+4-6%),但d以上的提升微乎其微(+0.2-0.5%)。论文给出了理论上界证明:
$$Acc_{微调后} \leq Acc_{基线} + O\left(\frac{d^*}{d}\right)$$
啥意思?如果d*=20但你想在d=40的问题上提升,上界大约是O(20/40)=50%的相对提升。但实际基线准确率在d=40时已经只有0.2%了,所以50%的提升也只是从0.2%到0.3%。没用。
这个结论是架构性的——不是训练数据不够、不是方法不对,是Transformer这个架构在这类任务上做不到。
State-Space Jaccard:区分"不想做"和"做不到"
之前Wu et al.的论文说LLM推理存在"Simplicity Bias"——模型倾向于偏好短推理路径。那到底模型是"能做但不想做"还是"真的做不到"?
论文设计了SSJ指标来回答这个问题。核心思路是把模型推理过程中经过的状态跟ground truth状态做一个Jaccard相似度计算:
$$SSJ(d) = \frac{|\text{模型经过的状态} \cap \text{正确状态}|}{|\text{模型经过的状态} \cup \text{正确状态}|}$$
如果模型是"能做但偷懒"(偏好问题),SSJ应该保持较高——说明模型知道正确状态是什么,只是选择不走完。
但实测结果呢?o3-mini在d=31时,SSJ从0.85跌到了0.15。更有意思的是Recall比Precision掉得更快——意思是模型生成的状态看起来是合理的(precision还行),但已经完全偏离了正确路径(recall崩了)。
这就是论文所说的**“State-Space Decoherence”(状态空间退相干)**——模型不是在偷懒,是真的迷路了。它产生的中间状态在局部看是自洽的,但全局来看已经跑到了一个虚构的状态空间里。
这对Agent系统设计意味着什么
这篇论文对我做Agent开发的直接影响:
1. 不要让LLM做超过20步的确定性推理
这个结论非常明确。如果你的Agent任务链超过20步,而且每一步都需要精确的状态跟踪(比如代码执行、数据库操作序列、复杂的工作流编排),你就不能依赖LLM的内部推理来保证正确性。
实操建议:把长链任务拆成<15步的子任务,每个子任务的结果由外部程序验证,然后再作为事实输入下一段推理。
2. 工具委托不是可选项,是必须的
论文最漂亮的数据:工具增强的系统在d=255的问题上仍然97%+的准确率,而纯推理早在d=30就归零了。而且工具增强不但准确率高,延迟还更低——因为省掉了几千token的CoT生成。
这给了一个很强的设计原则:当你能写程序解决的事,就别让LLM想。 Agent的价值不在于它"什么都能想",而在于它知道什么时候该想、什么时候该委托。
3. 跨模型相关性极高说明这是通病
论文测到的跨模型相关系数r=0.81-0.91。这意味着:一个模型做不到的深度推理,换另一个模型大概率也做不到。这不是某家模型的Bug,是所有Decoder-only Transformer的共同架构限制。
所以在设计Agent的时候,不要想着"等下一代模型就好了"。按现有的scaling趋势,d的增长速度是log(参数量)^0.6——换句话说参数量翻100倍,d也就涨那么几步。这条路走不通。
4. 一个有趣的推论:Encoder-Decoder可能更适合长推理
论文的预测中有一条:“Enc-dec advantage: 2-3×",实测结果是2.8×。也就是说带Encoder的架构(可以做双向注意力)在状态跟踪上比纯Decoder有2-3倍的优势。
这可能解释了为什么Google的某些模型在特定任务上表现异常好——如果它们内部有类似Encoder的组件的话。
实验里几个让我印象深刻的细节
失败模式分析
他们把2847条失败的reasoning trace做了归因分析:
- 状态漂移(47%):模型在某一步丢了当前状态,后面基于一个错误的状态继续推理
- 操作误用(31%):正确的操作施加在了错误的对象上
- 循环/重复(22%):模型重访了之前已经探索过的状态,但没有意识到
47%的失败来自"状态漂移”——这完美印证了注意力瓶颈理论。模型不是不知道该干什么,是不记得现在在哪了。
Token效率的崩溃
o3-mini在d=31的汉诺塔问题上平均消耗18400个token,但准确率只有22.4%。算下来每个正确解需要消耗18400/0.224 ≈ 82000 token。
而同一个问题用BFS工具解决,需要0.4秒、几十个token的工具调用描述。
差距是3-4个数量级。这不是优化问题,这是方法论错误。
Prompt engineering只是常数因子
他们测了5种不同的prompt策略,最好的比最差的能提升约15%(绝对值),但衰减的指数形状完全不变。也就是说prompt能帮你在d附近多答对几道题,但改变不了d本身的位置。
回到实际:什么任务受影响,什么不受
论文特别强调了适用范围:
受影响的任务(确定性状态跟踪):
- 追踪程序变量在多步执行后的值
- 多跳SQL查询的中间表状态
- 复杂的API调用链(每步有精确的状态变化)
- 数学证明中的等式推导(>20步)
- 棋类/谜题的搜索(>20步最优解)
不受影响的任务:
- 开放式文本生成(摘要、对话、创意写作)
- GSM8K类的数学题(大部分<15步)
- 近似推理、模糊匹配类任务
- 需要判断但不需要精确状态跟踪的决策
所以结论不是"CoT没用"——CoT在d<d*的范围内仍然是有效的。结论是CoT有一个明确的有效半径,超出半径后必须切换策略。
我的一些额外思考
这篇论文让我想起之前JIT编译那篇(Agent JIT Compilation),两者有一个共通的洞察:Agent的价值在于知道什么时候该思考、什么时候该执行。
JIT那篇的做法是把确定性的部分编译成代码直接跑,只在需要语义判断的点调用LLM。这篇论文从理论角度解释了为什么这么做是对的——确定性部分本来就不应该用LLM来做,因为LLM在这上面有架构层面的天花板。
这两篇放在一起,给出了一个很清晰的Agent设计哲学:
让LLM做判断,让工具做计算。LLM是决策者和规划者,不是执行者。
具体到我在做的Agent系统里,有几个立刻能用的优化点:
- 任何超过15步的线性工作流,中间必须有checkpoint——不能指望LLM一口气推理20+步都不出错
- 状态跟踪用外部存储——把当前状态写到文件/数据库里,每步从外部读取,不要指望LLM在context里自己track
- 错误检测前置——每步执行完做一次状态验证(类似JIT那篇的前置/后置条件),发现偏离立刻纠正
说白了就一个道理:别让LLM干它不擅长的事。思考20步以上的确定性问题,它真做不到。
论文信息
- 标题:The Deterministic Horizon: When Extended Reasoning Fails and Tool Delegation Becomes Necessary
- 作者:Dongxin Guo, Jikun Wu, Siu Ming Yiu
- 机构:The University of Hong Kong / Brain Investing Limited / Stellaris AI Limited
- 会议:ICML 2026
- 链接:https://arxiv.org/abs/2606.00376