TableMind:让小模型学会像人一样查表——一个自主编程 Agent 的 RL 进化之路

表格推理这件事,说起来简单,做起来真的让人头疼。
你去问 ChatGPT 一个需要从表格里找数据、做计算的问题——比如"去年Q3哪个城市的销售额环比增长最快"——它有时候回答得挺自信,但仔细一验算,数字就是对不上。为什么?因为 LLM 天生就不擅长精确的数值操作。它能"理解"你的问题,能"看懂"表格的结构,但让它算个百分比变化,总有翻车的可能。
中科大的团队在 WSDM 2026 上发表了 TableMind,一个很有意思的思路:不要让 LLM 硬算,让它学会像人一样——想清楚要做什么,写代码去操作数据,看看结果对不对,不对就修正。
整个系统只有 8B 参数(Qwen3-8B),却在五个 benchmark 上打败了 72B 的 Qwen2.5 和 DeepSeek-R1。
怎么做到的?往下看。
问题到底出在哪
先聊聊现有方法的痛点,我归纳了三个核心问题:
上下文塞不下。 很多方法的做法是把整张表格"铺平"成文本丢进去,一个几百行的销售报表,token 直接爆炸。你上下文窗口再大,也架不住企业级表格动辄几千个单元格。
算数不行。 LLM 本质上是在做 next token prediction,你让它算 2:17:27 - 2:14:15 = ? 秒,它需要把时间转秒、做减法——这种多步精确运算不是它的强项。Chain-of-Thought 能帮一些忙,但复杂情况下错误率还是很高。
没有"检查答案"的习惯。 人在做数据分析的时候会回头看看——“这个数对吗?逻辑通吗?"——但大多数 LLM 方法是一次性输出答案,错了就错了,没有反思和修正的机制。
TableMind 的核心观察是:人类做表格推理本来就不是一步到位的。你会先分析问题(哪些列相关?需要什么计算?),然后动手操作(写个公式或脚本),接着检查结果(这个数看起来合理吗?),不对就回去改。这是一个 Plan → Action → Reflect 的循环。
TableMind 的整体设计
整体思路用一句话总结:训练一个轻量级 LLM,让它内化"规划-执行-反思"的循环,用代码工具做精确计算,而不是靠脑补。
具体来说,它的推理流程是这样的:
- 模型读入表格和用户问题
<think>阶段:分析问题,制定策略(“我需要先找到最高和最低排名对应的时间”)<tool>阶段:生成 Python 代码去操作表格数据- 代码执行,得到
<response>(执行结果或报错信息) - 模型反思结果,决定是继续下一步操作还是输出最终
<answer>
这个循环最多跑 3 轮。每一轮都是模型自主决策的:它决定要做什么、写什么代码、结果对不对、要不要继续。
但你可能会问——这不就是 ReAct 吗?确实像。但关键区别在于:TableMind 不是靠 prompt engineering 让大模型做这件事,而是用 SFT + RL 训练一个 8B 的小模型去内化这种行为。
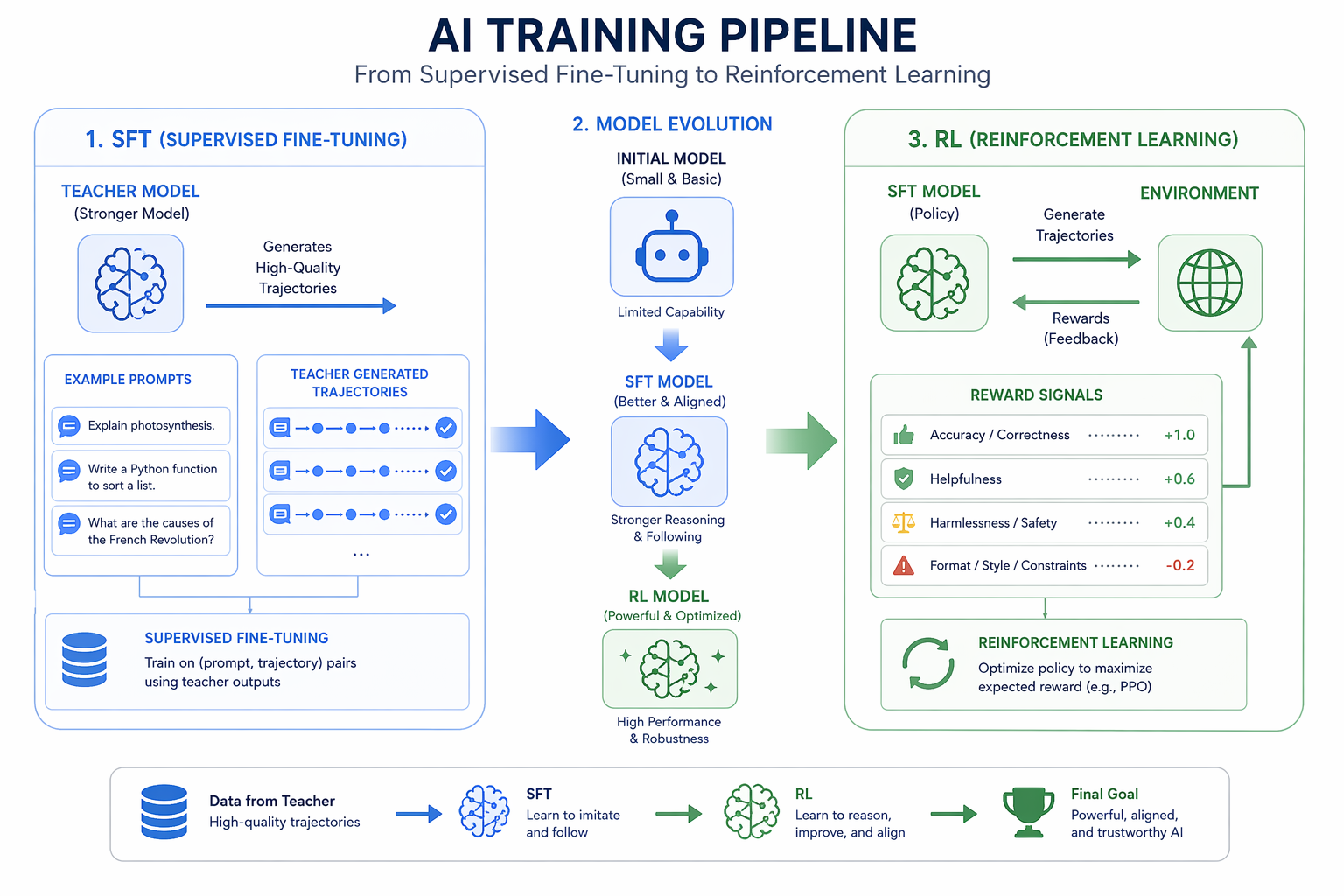
两阶段训练:SFT 打基础,RL 上强度
第一阶段:SFT 预热
说白了就是先"教会基本套路”。
数据怎么来的?用强大的教师模型(比如 GPT-4 级别)对表格问题生成推理轨迹——每一步的思考过程、代码、执行结果都记录下来。然后严格筛选:只保留最终答案正确的轨迹。
有个很有意思的发现:只需要 200 个样本训练 1 个 epoch,效果就达到最优了。
为什么这么少就够?因为 SFT 阶段的目标不是让模型"精通"所有类型的表格问题,而是让它:
- 学会输出格式(
<think>→<tool>→<response>→ 循环或<answer>) - 理解"用代码操作数据"这个概念
- 掌握基本的规划和反思模式
但 SFT 的局限也很明显——模型学到的更多是"模式记忆",遇到训练数据里没见过的问题类型,就不太行了。这就需要第二阶段来补。
第二阶段:RL 强化
RL 阶段才是 TableMind 真正变强的地方。
这里用了一个叫 RAPO(Rank-Aware Policy Optimization) 的算法,基于 GRPO 框架改进。核心改动有三个:
第一,去掉 KL 散度约束。 传统 PPO/GRPO 会用 KL 惩罚防止模型跑太远,但这里发现放开约束反而让模型探索得更好。
第二,token 级梯度。 不是按整个回答算损失,而是按每个 token 算。这样长答案和短答案对梯度的贡献是均匀的,不会因为某个回答特别长就主导训练。
第三,排序感知的优势估计。 这个比较巧妙——如果模型对一个低奖励的轨迹反而比高奖励的更"自信"(概率更高),说明模型的内部排序出了问题。RAPO 会对这种"错位"施加额外的学习压力。
奖励设计的巧思
RL 的核心是奖励函数。TableMind 设计了三个维度:
格式奖励:输出格式对不对?(是/否,0 或 1)
准确度奖励:答案对不对?(精确匹配,0 或 1)
工具奖励(最有意思的部分):
R_tool = e^(-ρs) × [β × I(成功执行) - C × (调用轮数)²]
几个细节值得说道说道:
e^(-ρs)是个衰减因子——训练早期工具奖励权重大,鼓励模型积极使用工具;训练后期权重减小,让模型不再依赖工具奖励而是追求最终准确度。这其实是一个隐式课程学习。- 调用轮数的平方惩罚意味着:用工具可以,但别用太多轮。用 1 轮惩罚很小,用 3 轮惩罚 9 倍。这逼迫模型学会高效推理。
- 只要有一次成功执行就给正向激励,降低了冷启动难度。
实验:8B 打 72B 是怎么做到的
主结果表格很说明问题:
| 模型 | WikiTQ | TabMWP | TabFact | HiTab | FinQA |
|---|---|---|---|---|---|
| Qwen2.5-72B-Instruct | 68.56 | 97.45 | 87.34 | 68.02 | 35.83 |
| DeepSeek-R1 | 74.63 | 98.03 | 86.25 | 70.37 | 37.42 |
| Table-R1 (8B) | 74.86 | 96.02 | 87.17 | 69.24 | 41.27 |
| TableMind (8B) | 76.82 | 99.27 | 91.85 | 71.95 | 42.02 |
几个值得关注的点:
WikiTQ 上超过 DeepSeek-R1 两个点。 WikiTQ 是开放域的表格问答,需要理解复杂问题并从 Wikipedia 表格中提取答案。8B 模型能赢 R1 级别的推理模型,说明"会用工具"确实能弥补模型能力的不足。
TabMWP 达到 99.27%。 这是多步数学推理任务,接近完美。对于需要精确计算的场景,代码执行的可靠性远超 LLM 的"心算"。
TabFact 提升最大(+3.28pp)。 事实验证任务需要判断一个陈述是否被表格支持,往往涉及数值比较和逻辑推断。模型通过代码验证比"感觉"靠谱多了。
FinQA 打败了所有对手。 这是专家级金融推理——多步数值计算加上表格和文本混合理解。作为 out-of-domain 的数据集(训练时没见过),TableMind 的泛化能力很突出。
Training-free 方法为什么不够
一个有趣的对比:PoTable 和 Chain-of-Table 这些不需要训练的方法(靠 prompt 让 GPT-4 做多步推理),在大部分任务上都不如 TableMind。
这说明什么?工作流编排(prompt engineering 层面的规划-执行-反思)在这类任务上是有天花板的。 即使你的 prompt 设计得再精巧,最终执行推理的还是那个模型——它的数值运算能力、格式遵循能力、多轮一致性能力都有上限。
把这些能力通过 SFT + RL “烧"进 8B 模型里,反而能突破 prompt engineering 的天花板。
消融实验告诉我们什么
作者做了四组消融,每组都有明确的启示:
去掉 SFT(直接 RL):WikiTQ 从 76.82 降到 73.76,TabFact 从 91.85 降到 88.32。说明 SFT 提供的"热身"很重要——没有基本的格式和逻辑铺垫,RL 的探索效率会大打折扣。
去掉 RL(只用 SFT):WikiTQ 暴降到 55.40,TabFact 降到 77.15。这个差距是毁灭性的。SFT 只是"教会了套路”,RL 才是"教会了灵活应变"。
去掉工具奖励 R_tool:WikiTQ 降到 75.63。模型不再被激励高效使用工具,生成了更长更冗余的推理链,错误率上升。
RAPO 换成 GRPO:WikiTQ 降到 74.48。RAPO 的排序感知机制确实在帮助模型更快地学习正确的策略优先级。
工具使用的"觉醒"过程
论文里有一张很有意思的图,展示了 RL 训练过程中工具使用率的变化:
- 前 40 步(探索期):模型犹犹豫豫,工具使用率在 70% 左右波动,有时候还会退回纯文本输出。
- 第 41-70 步(顿悟期):突然拐点出现,工具使用率急剧上升。模型"悟了"——用工具比硬算靠谱。
- 第 71-120 步(收敛期):稳定在接近 100%。
与此同时,代码执行通过率从 60% 稳步爬到 90%。模型不光学会了"该用工具",还学会了"怎么写对代码"。
这个过程挺像人类学编程的体验——一开始觉得手算也行,后来发现写脚本效率高十倍,再后来代码越写越溜。
超参数的微妙平衡
两个关键超参数的消融也值得说:
最大工具调用轮数:1 轮 → 3 轮,性能大幅提升(WikiTQ 74.35 → 76.82)。但 3 轮 → 5 轮反而略降。为什么?多了容易累积错误、引入冗余操作。3 轮是个甜点——大部分问题 2-3 步就能搞定。
采样温度:在 0.6 到 1.0 的范围内,温度越高性能越好。这说明在 RL 训练中,更高的多样性帮助模型探索更好的策略。
一个具体例子
论文给了个 WikiTQ 上的案例,问的是:“这个运动员在奥运会最好名次和最差名次的完赛时间差几秒?”
第一轮:
- 思考:需要找到最好和最差名次对应的两个时间
- 代码:从表格中提取第 1 名的时间(2:14:15)和第 20 名的时间(2:17:27)
- 反思:拿到时间了,但格式是字符串,还需要转成秒来做减法
第二轮:
- 思考:用 datetime 模块来解析时间字符串
- 代码:
datetime.strptime解析后相减,取秒数 - 结果:192 秒
- 输出答案:192
看起来很自然对吧?但要注意,这不是 prompt 引导出来的——是模型自主决策的。它自己判断第一轮的结果还不够(字符串不能直接算差值),需要第二轮来做类型转换和计算。这种"判断何时继续、何时结束"的能力,是 RL 训练出来的。
模型缩放效果
作者还测了 1.7B、4B、8B 三个规模的 Qwen3。结论很直接——越大越好,而且大模型从训练一开始就保持领先,不存在"小模型训练够了能追上来"的情况。
这意味着如果你有更多算力预算,用更大的基座模型走同样的 SFT + RL 流程,还有很大的提升空间。
对我们的启示
说几点我觉得比较有价值的 takeaway:
“该用工具就用工具"这件事,可以通过 RL 让模型自己悟出来。 不需要在 prompt 里反复强调"请使用代码执行”,RL 的奖励信号自然会把模型引向正确的策略。
SFT 数据不需要多,200 条就够。 但质量要高——必须是完整、正确、有教育价值的推理轨迹。
工具奖励的课程学习设计很巧。 早期鼓励尝试、后期鼓励高效——这个策略对任何需要工具使用的 Agent 训练都有参考价值。
Training-free 方法有天花板。 在需要精确数值推理的场景,与其花大力气设计 prompt workflow,不如直接训练一个小模型。8B 就能打败 72B,性价比很高。
RAPO 的"错位检测"思想有普适性。 任何时候你发现模型对错误输出更"自信",都应该给它更大的修正压力。这个思路可以迁移到其他 Agent 场景。
局限和未来
论文也坦承了一些限制:
- 目前只处理单表格,多表联合推理还没涉及
- 工具只有 Python 执行器,更丰富的工具(SQL、可视化等)可能带来更多可能性
- RL 训练效率还有提升空间,特别是对于更大模型
我个人觉得最有前景的方向是把 TableMind 的思路推广到通用 Agent 训练——用少量高质量轨迹做 SFT 热身,然后用带课程的 RL 让模型学会何时用什么工具、用几步搞定。这不光适用于表格推理,任何多步骤工具使用的场景都能借鉴。