把Web Agent当编译器来优化:斯坦福ICML 2026最新工作,延迟降10倍准确率涨28%
最近刷ArXiv的时候看到一篇斯坦福的论文,标题叫"Agent JIT Compilation for Latency-Optimizing Web Agent Planning and Scheduling",被ICML 2026接收了。说实话,刚看到标题的时候我愣了一下——JIT编译?这不是Java虚拟机和V8引擎里的概念吗,怎么跑到Agent领域来了?
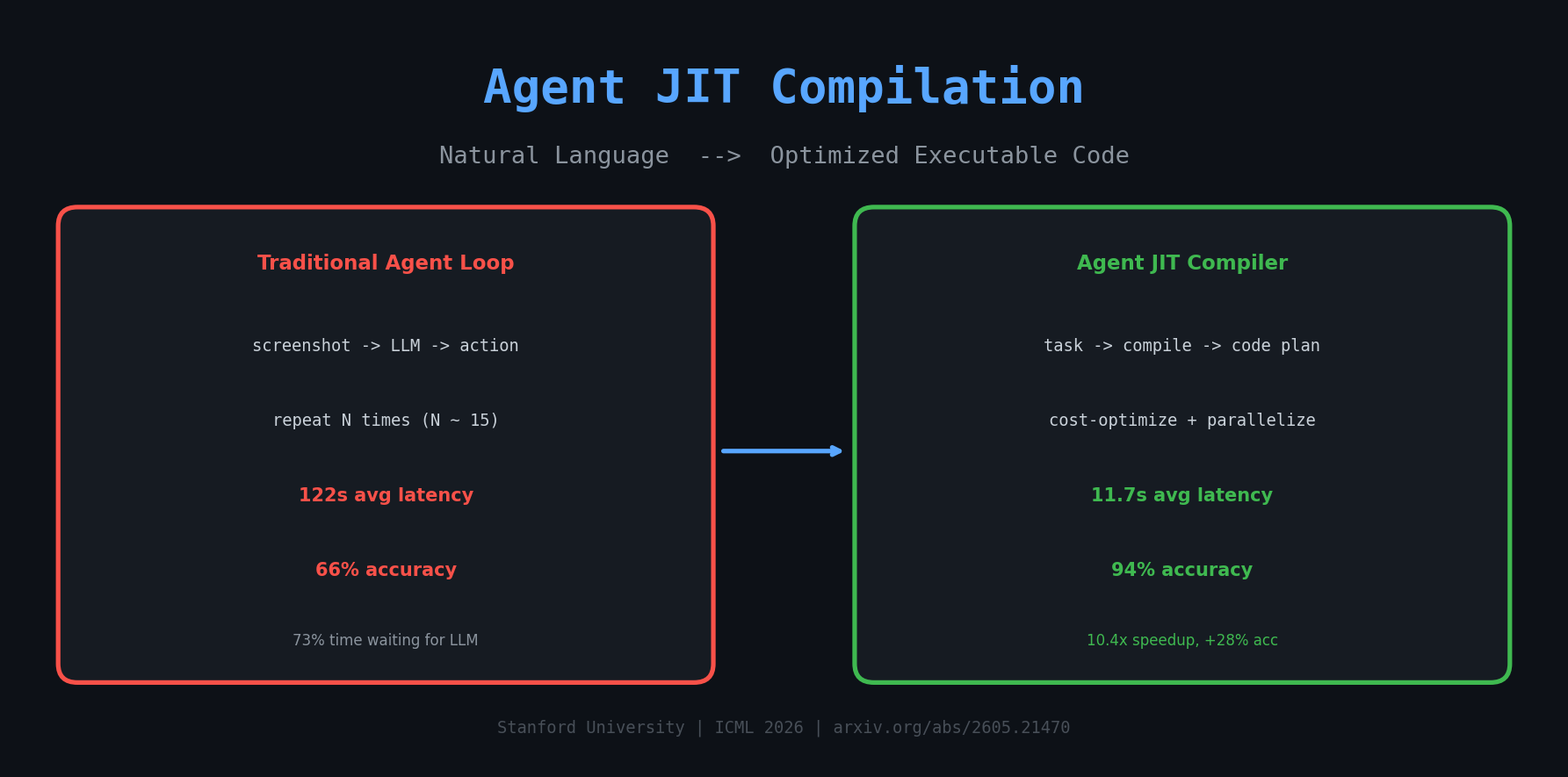
读完之后发现,这帮人的思路确实够野:他们把"给Agent一个任务让它去网页上操作"这件事,类比成了编译器把高级语言翻译成机器码的过程。而且不是随便翻译,是要找到成本最低的那种翻译方式。结果也确实惊人——比当前最好的Web Agent快了10倍,准确率还高了28个百分点。
这篇文章我打算按照论文的思路完整过一遍,把核心方法和实验都讲清楚。内容比较硬核,适合在做Agent开发或者对Web自动化感兴趣的读者。
现有Web Agent到底慢在哪
先说背景。现在主流的Web Agent(比如Browser-Use、OpenAI CUA)干活的方式是这样的:
截一张网页截图 → 发给LLM看 → LLM告诉你"点击这个按钮" → 执行 → 再截图 → 再问LLM...
每一步都要等LLM返回,一个简单的"在Taco Bell点最便宜的餐"可能要跑十几个循环。论文里实测Browser-Use跑一个任务平均要122秒,其中73%的时间花在等LLM推理上。
这个范式有三个根本问题:
问题一:工具集太原始。 Agent能用的工具就是click、type、scroll这种最底层的操作,相当于每次都在用汇编语言写程序。你想想,让一个人去"订最便宜的外卖",正常人不会一步步想"先把鼠标移到搜索框,然后点一下,然后输入T-a-c-o…"——而是直接想"打开外卖app,搜restaurant,选最便宜的"。
问题二:完全串行。 就算任务里有明显可以并行的部分(比如"查三家店的价格"),现有Agent也是老老实实一个一个查。你有4个vCPU闲着也没用。
问题三:该确定的地方不确定。 比如一个工具返回了一个列表,下一步显然是从列表里选最便宜的,这中间根本不需要再问一次LLM。但标准的agent loop会无脑在每一步都塞一个LLM调用,增加了不必要的延迟和出错机会。
JIT编译的类比
论文的核心想法是这样的:
传统JIT编译器做的事情是——把高级语言(比如Java字节码)在运行时翻译成底层机器码,而且会尝试多种翻译策略,选效率最高的那个。
Agent JIT编译器做的事情是——把自然语言指令(比如"帮我在Taco Bell点最便宜的套餐")在规划时翻译成可执行代码,代码里可以包含工具调用、LLM调用、并行化逻辑,然后从多个候选方案中选成本最低的那个。
翻译出来的代码不是用click/type这种原语,而是用预先缓存的高级工具(比如list_restaurants()、add_to_cart(item_id)),所以大部分步骤不需要LLM参与。
整个系统分三个组件,我一个一个说。
组件一:不变量强制工具协议
这是整个系统的基础设施层。
现有的工具协议(比如大家熟悉的MCP)做的是类型检查——输入是什么类型、输出是什么类型。但Agent JIT把这个概念扩展了,加入了**前置条件(precondition)和后置条件(postcondition)**的状态不变量。
举个例子,一个"导航到餐厅详情页"的工具,它的协议长这样:
{
"input_schema": {"rId": "string"},
"output_schema": {},
"pre": {"page": "*"},
"post": {"page": "detail", "selectedRestaurant": "$rId"},
"pre_check": "document.getElementById('r-list') != null",
"post_check": "document.getElementById('r-detail') != null"
}
pre说的是"执行这个工具之前,系统状态必须满足什么条件",post说的是"执行完之后,系统状态保证变成什么样"。这样一来,多个工具的组合就可以在编译时做静态检查——只要上一个工具的post是下一个工具的pre的子集,这个组合就是安全的。
为什么这个设计这么重要?论文里有一个数据让我印象很深:Web Agent 45-50%的错误来自工具调用顺序错误——点错了元素、在错误的字段里打字之类的。通过在编译时强制状态流正确性,这一大类错误直接被消灭了。
实验数据也验证了这点:
| 模型 | 无协议的有效Plan率 | 有协议的有效Plan率 |
|---|---|---|
| GPT-4.1 | 78% | 91% |
| Gemini-2.5-Pro | 79% | 96% |
| Gemini-2.5-Flash | 74% | 85% |
总体失败率从80%降到43%,其中"工具顺序错误"这类失败从占比59%降到25%。
组件二:成本优化规划器
有了协议保证正确性,下一个问题就是:对于同一个任务,可能存在很多种正确的Plan,它们的执行成本差异巨大。
论文测出来的数字是:最好的Plan和最差的Plan之间,延迟差5.3倍。也就是说如果你随便选一个能跑的Plan,很可能比最优方案慢5倍多。
成本优化规划器的做法分四步:
第一步,并行候选生成。 用n个worker同时让LLM生成代码Plan,直到收集到k个有效候选。每个worker独立工作,一个成功了其他的也不用等,直接early termination。
第二步,CFG构建与验证。 对每个候选Plan构建控制流图(CFG),遍历图的每个节点做状态流检查——验证每个工具调用的前置条件是否被之前的后置条件满足。不满足就直接拒绝这个Plan。
第三步,成本估算。 在遍历CFG的同时估算成本。每个工具调用的成本是 $C_{tool} \cdot \gamma^d$,每个LLM调用的成本是 $C_{eval} \cdot \gamma^d$,其中d是嵌套深度。那个 $\gamma = 10$ 的嵌套惩罚系数是个很妙的设计——如果你的Plan在循环里面套了LLM调用,成本会指数级膨胀,逼着模型生成把LLM调用放在循环外面的方案。
第四步,选最优。 从所有有效候选中选成本最低的那个执行。
我觉得这里面最有意思的insight是验证和成本估算是同时做的——你不需要先验证完所有Plan再一个个算成本,而是在验证的过程中就把成本算出来了,不合法的Plan可以提前终止,节省了大量计算。
论文还对比了"并行hedging"和"串行重试"两种生成策略。在一个19步的GitLab长任务上:
- 并行hedging(8个worker)在8秒内达到100%有效率
- 串行重试(最多3次,带反馈)需要23秒才达到95%
快了近3倍。这说明对于复杂任务,与其让模型"从错误中学习",不如直接多采样几个方案然后挑好的。
组件三:成本感知调度器
规划器解决了"怎么把任务翻译成代码"的问题,调度器解决的是"代码生成后怎么分配计算资源"的问题。
给你4个vCPU,一个任务有几种执行方式:
- 串行(Serial):一步步按顺序来
- 并行(Parallel):把任务拆成子任务分配给多个worker
- 对冲(Hedge):同一个任务让多个worker同时跑,谁先跑完用谁的结果
哪种最好?答案是:没有普适最优,取决于具体任务。
论文举了几个例子:
- “查三家店各自的前三条评价” → 适合并行,因为子任务独立
- “查抹茶可颂和冰抹茶拿铁的价格” → 适合串行,因为都在同一页上,两步就完事
- “转发前两封邮件并删除原件” → 适合对冲,因为这种操作容易在某个UI元素上卡住
调度器的做法是用蒙特卡洛成本估计。它先从历史执行中学习每个DOM元素的交互延迟分布,然后:
- 让LLM预测当前任务在每种策略下会和哪些元素交互、交互几次
- 从学到的延迟分布中采样,模拟N次执行
- 算出每种策略的期望延迟
- 选延迟最低的那个
这个设计的优雅之处在于它不需要实际执行就能估计延迟——纯粹基于历史数据和元素级别的延迟模型做预测。
实验结果:大幅碾压
说了这么多方法,结果到底怎么样?直接看数字。
JIT-Planner vs 基线
在5个Web应用、37个任务上的汇总结果:
| 方法 | 平均延迟 | 准确率 |
|---|---|---|
| Browser-Use | 122.1s | 66% |
| Browser-Use +cache | 80.1s | 85% |
| JIT-Planner | 11.7s | 94% |
10.4倍的加速,28个百分点的准确率提升。这个差距大到不像是同一类方法之间的比较。
分模型看:
| 模型 | Browser-Use延迟 | JIT-Planner延迟 | 加速比 | 准确率提升 |
|---|---|---|---|---|
| GPT-4.1 | 150.1s | 15.4s | 9.7× | +29% |
| Gemini-2.5-Flash | 100.3s | 7.2s | 14.0× | +35% |
| Gemini-2.5-Pro | 115.9s | 12.6s | 9.2× | +20% |
Gemini-2.5-Flash的加速比最夸张,到了14倍。原因是这个模型生成Plan很快(Planning开销小),而且生成的代码质量不差。
分应用看最有意思:
| 应用 | 加速比 | 准确率提升 |
|---|---|---|
| 18.9× | +21% | |
| GitLab | 14.6× | +38% |
| Gomail | 12.9× | +33% |
| Dashdish | 8.2× | +35% |
| Omnizon | 7.4× | +13% |
Reddit之所以加速最猛(近19倍),是因为它的任务大多能编译成纯确定性的工具调用序列,中间完全不需要LLM参与。而Omnizon加速最小,因为购物任务经常需要LLM做语义判断(比如"这个商品符合要求吗"),Plan里不得不保留ai_eval调用。
一个关键对照:给GPT-5.4同样的工具
有人可能会问:JIT-Planner的提升是来自"有更好的工具"还是"规划方法本身更好"?
论文做了一个很漂亮的对照实验:把JIT-Planner用的那些缓存工具也给GPT-5.4(OpenAI CUA),让它用标准的agent loop来调用这些工具。结果呢?
即使给了同样的工具,GPT-5.4(CUA +cache)在所有任务复杂度维度上仍然比JIT-Planner慢1.5-2.4倍,准确率也没有优势。
这说明成本优化规划本身就有独立的贡献——不是说你有好工具就够了,你还需要一个聪明的方式来组合它们。
JIT-Scheduler vs 基线CUA
调度器的实验在4个vCPU预算下跑:
| 方法 | 延迟 | 准确率 |
|---|---|---|
| OpenAI CUA | 258.7s | 77.8% |
| Anthropic CUA | 141.7s | 79.0% |
| JIT-Scheduler (Gemini-2.5-Pro) | 109.9s | 86.4% |
相比OpenAI CUA,2.4倍加速 + 9%准确率提升。相比Anthropic CUA,1.3倍加速 + 7%准确率提升。
准确率为什么也高了?因为调度器会在合适的时候选并行策略,把大任务拆成小子任务,每个子任务更简单、更不容易出错。
一些有意思的细节
成本估算的准确性
论文测了最差Plan和最优Plan的延迟比。汇总级别是5.3倍,但逐任务配对来看是1.8倍。为什么差这么多?因为有些任务只有一种合理的Plan(差异小),而有些任务有很多种Plan(差异大),汇总被极端案例拉高了。
但即使是1.8倍(95% CI: [1.6, 2.1]),也意味着如果你不做成本优化,平均要多花80%的时间。这个数字够大了。
失败模式分析
没有协议时,失败原因的分布是:
- 工具顺序错误:59%
- 超时:15%
- 语法错误:12%
- 类型错误:8%
- 状态变异:6%
有协议后:
- 工具顺序错误:25%(大幅下降)
- 超时:30%(占比升高,因为其他错误减少了)
- 语法错误:20%
- 类型错误:15%
- 状态变异:10%
工具顺序错误被协议干掉了大部分,剩下的主要瓶颈变成了超时和语法错误——这些是模型能力层面的问题,不是系统设计能解决的。
离线缓存的成本
这个方案不是零成本的。每个新应用需要:
- 工具合成:25-90分钟(从执行trace中提取高级工具)
- 延迟分布学习:25-45分钟
不过这些都是一次性成本,用并行worker可以压到20-30分钟。适合Agent要反复处理的应用场景。
UI变化怎么办
缓存的工具编码了DOM结构的假设,如果网页改版了怎么办?
论文的方案是靠协议本身来检测:运行时如果前置/后置条件检查失败了,就知道这个工具失效了,系统自动fallback到重新规划(不用这个工具)。也可以设TTL定期重新验证。
我的一些思考
读完这篇论文,有几个点让我印象特别深:
第一,“Agent是编译器而非解释器"这个范式转换很有力。 现有的Agent范式本质上是解释执行——一步步翻译一步步执行,每步都有完整的"感知-推理-执行"循环。而编译范式是先一次性生成完整的执行计划(代码),然后高效执行。这意味着Planning的开销被摊销了,执行时不需要反复调用LLM。
第二,前置/后置条件这个设计可以推广到很多场景。 不只是Web自动化,任何涉及工具组合的Agent都可以用这个思路。比如我们跑的论文摘要pipeline(搜索→下载→提取→生成→发布),每个工具都可以声明自己的前置/后置条件,然后在执行前做静态验证。
第三,成本优化的空间远比想象的大。 5.3倍的最优/最差Plan延迟差距说明,随机选Plan的期望性能是很差的。这意味着在任何Agent系统中,如果你不做planning层面的优化,你可能在浪费大量的算力和时间。
第四,并行hedging > 串行重试。 对于复杂任务,与其让模型"从第一次错误中学习”(串行重试),不如直接多采样几个方案然后挑好的(并行hedging)。这可能也适用于其他需要多次尝试的Agent场景。
不过这个方案也有明显的局限——它需要对每个目标应用做离线工具合成,不适合完全未知的网站。而且对于那些需要大量实时语义判断的任务(比如"找一个看起来好吃的餐厅"),编译出来的代码里还是得塞LLM调用,加速就有限了。
论文信息
- 标题:Agent JIT Compilation for Latency-Optimizing Web Agent Planning and Scheduling
- 作者:Caleb Winston, Ron Yifeng Wang, Azalia Mirhoseini, Christos Kozyrakis
- 机构:Stanford University
- 会议:ICML 2026
- 链接:https://arxiv.org/abs/2605.21470