Multi-Agent 选型指南:从「能跑」到「能活」的工程决策
当一个 Agent 开始同时承担调研、写作和事实核查三重角色时,它并不是在变强——它是在慢性崩溃。这不是 Prompt Engineering 能解决的问题,而是单体架构的结构性极限。
本文拆解 Multi-Agent 的四种主流协作拓扑,帮你在工程实践中做出正确的架构决策。
单体 Agent 的三种死亡方式
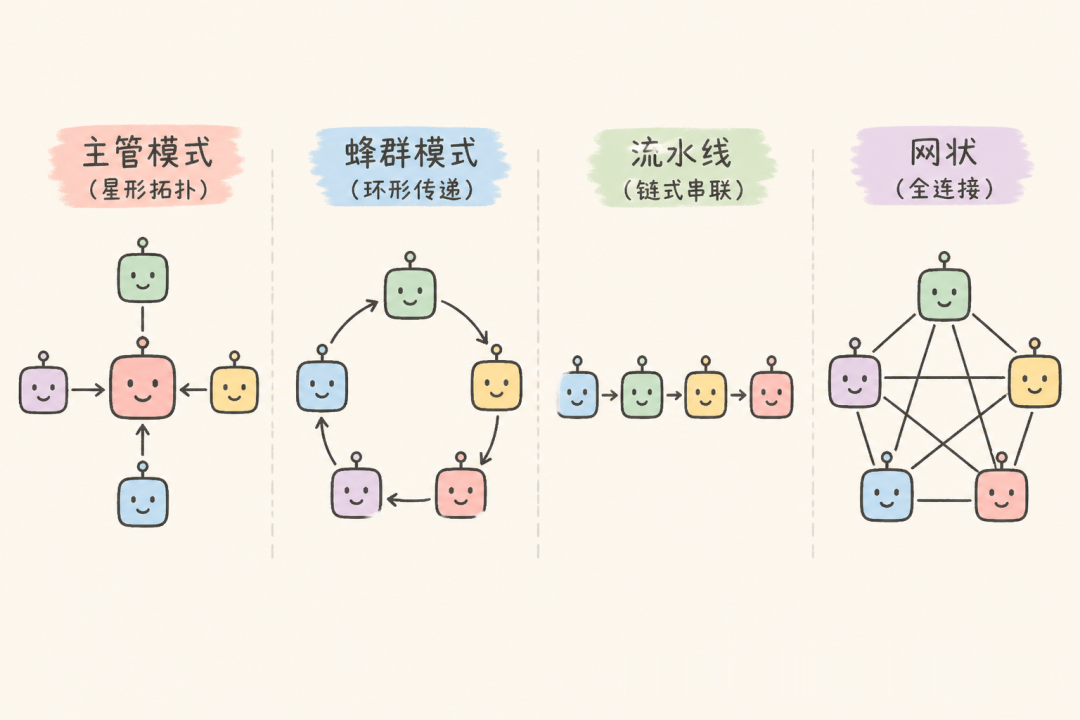
在讨论协作架构之前,得先理解为什么单体 Agent 会走向失败。三种典型崩塌路径:
死法一:上下文窗口的熵增
12 个工具的描述占满了 token 预算。当执行链条拉长到第 7 步时,第 2 步的关键信息已经被稀释或遗忘。Agent 并非真的「犯错」——它只是看不见关键上下文了。
死法二:人格分裂
系统提示里塞了三组互相矛盾的指令。调研指令说「深入搜索」,写作指令说「精简表达」,代码指令说「严谨实现」。这些指令在竞争优先级,Agent 在三个角色之间反复横跳。
死法三:故障无隔离
没有断路器,没有独立校验。第 3 步的错误像多米诺骨牌一样把后续 7 步全部推倒,你只能从头重来。
Multi-Agent 的核心理念其实很朴素:职责隔离 + 清晰接口 + 故障收敛。但具体怎么组织这些独立 Agent 之间的协作关系,决定了系统的天花板和地板。
拓扑一:Supervisor — 中央调度型
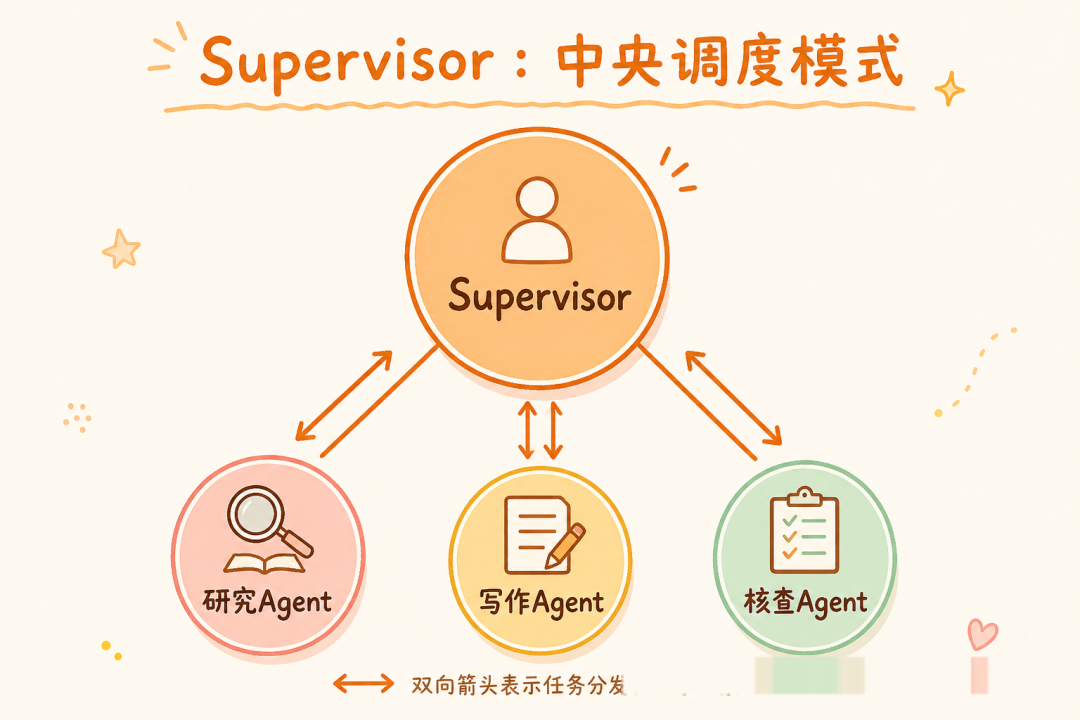
模型:一个调度中心 + N 个专家节点。所有请求先经过 Supervisor 路由,专家完成后结果回流到 Supervisor,由它决定是否继续分派或直接输出。
数据流向:User → Supervisor → Worker(s) → Supervisor → Output
专家之间彼此不可见,所有通信必须经过中枢。
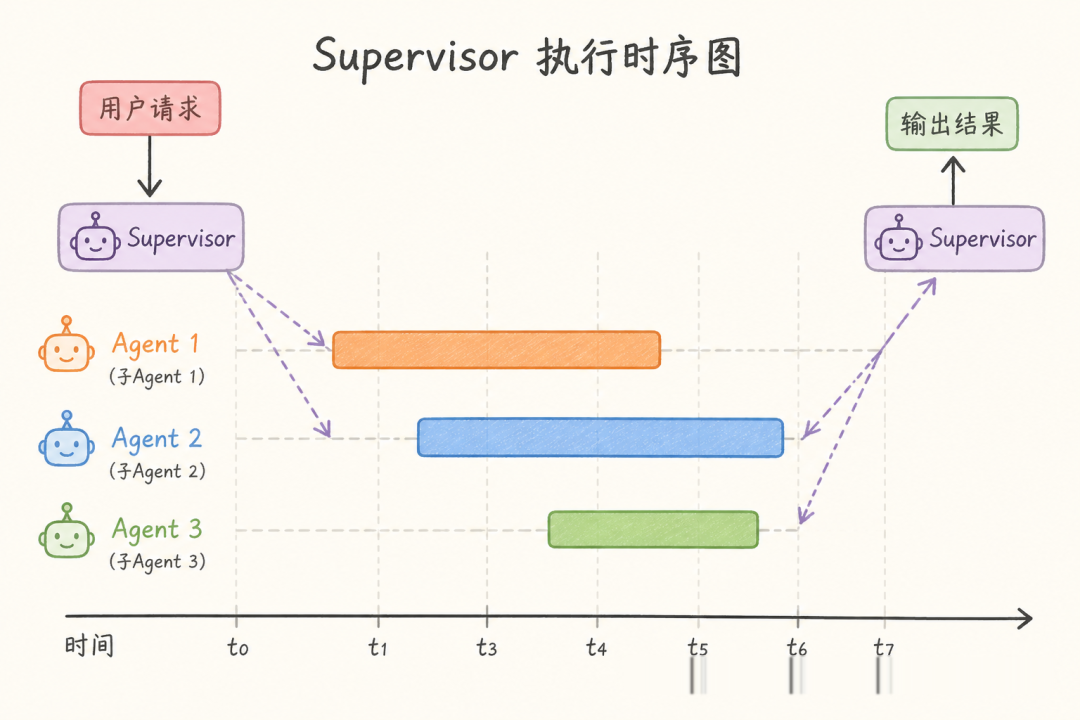
工程优势:调试链路清晰——出错时只需要追踪 Supervisor 的路由决策和对应 Worker 的执行结果。可观测性开箱即用。
工程代价:Supervisor 是单点瓶颈。如果它的任务分解出了偏差,下游所有 Worker 都会被误导。
最佳适用场景:子任务边界明确的流程型工作——工单分派、内容生成管线、代码审查流水线。
拓扑二:Swarm — 去中心化交接型
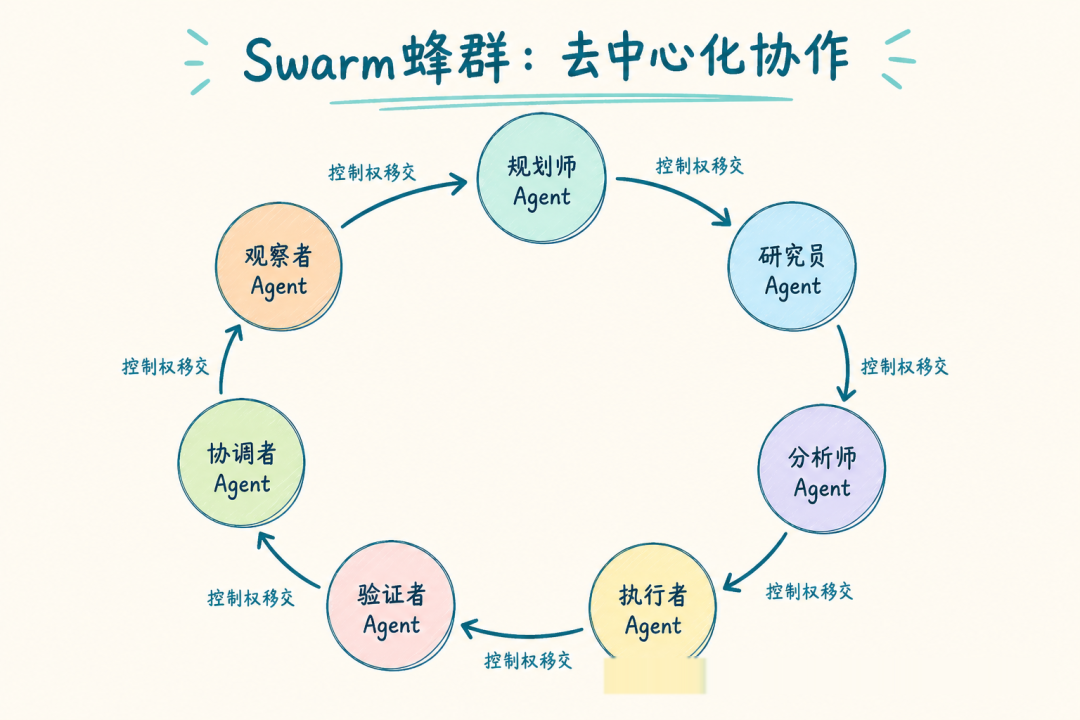
模型:没有中央调度。Agent 之间通过 handoff 机制直接传递控制权和上下文。流程不是预设的,而是从每一次 handoff 中「涌现」出来。
这更接近真实客服团队的工作方式——前台判断问题类型,然后直接转给对应专家,专家处理完可以转回前台或直接结束。
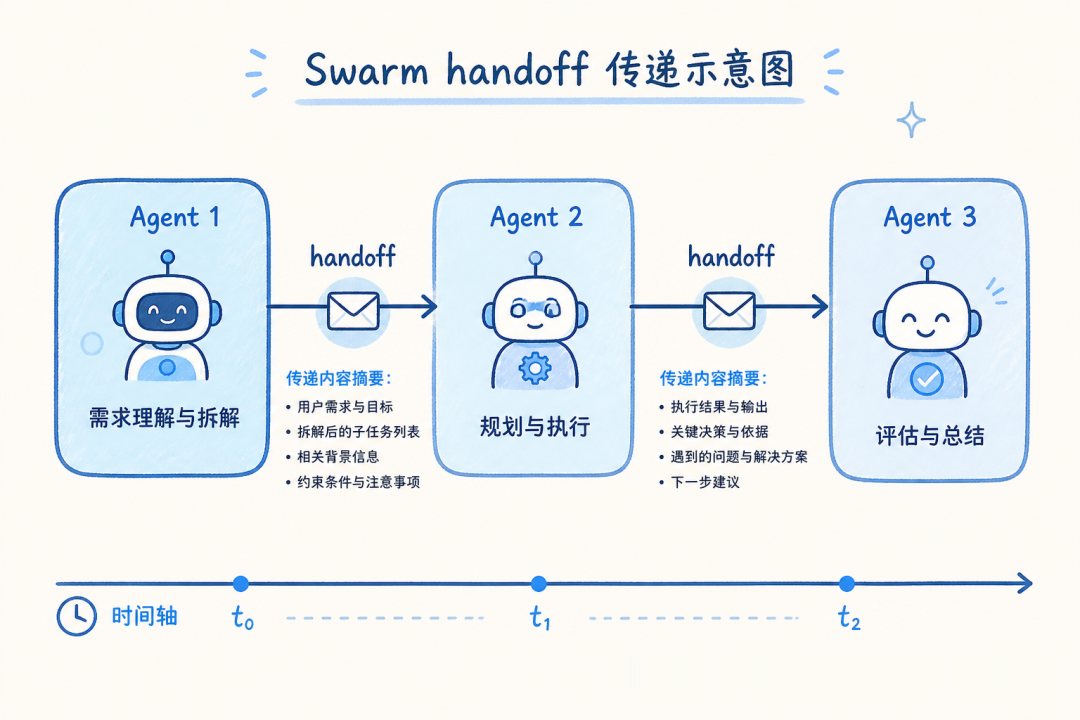
createHandoffTool 是整个模式的枢纽——它不仅转移控制权,还完整传递上下文,确保下游 Agent 不会「失忆」。
核心风险:环路。A 转给 B,B 转回 A,永无止境。recursionLimit 不是建议,是生产环境的熔断器。此外,每个 Agent 的 prompt 里必须写清楚「什么不归我管」,减少误判 handoff。
最佳适用场景:对话驱动、流向不确定的交互系统——客服、咨询、多轮对话路由。
拓扑三:Pipeline — 线性串行型
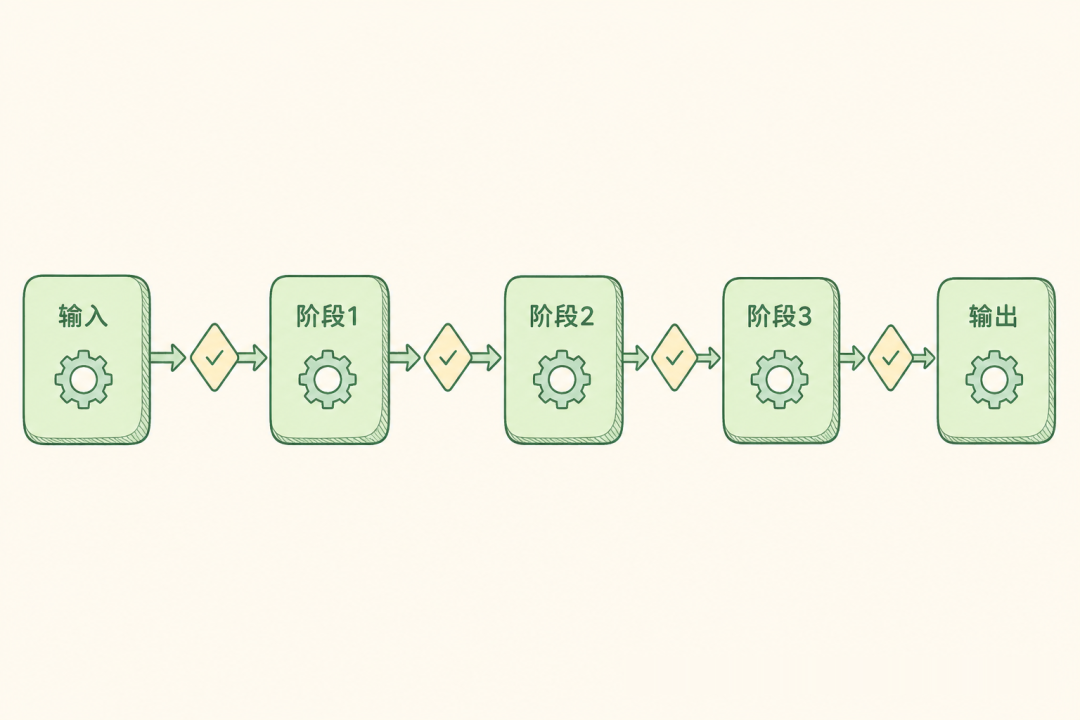
模型:最古典的架构范式。Agent 像流水线上的工位一样串联,前一个的输出即后一个的输入。没有反向通信,没有跳步,完全确定性。
Raw Data → Extractor → Enricher → Analyzer → Reporter → Output
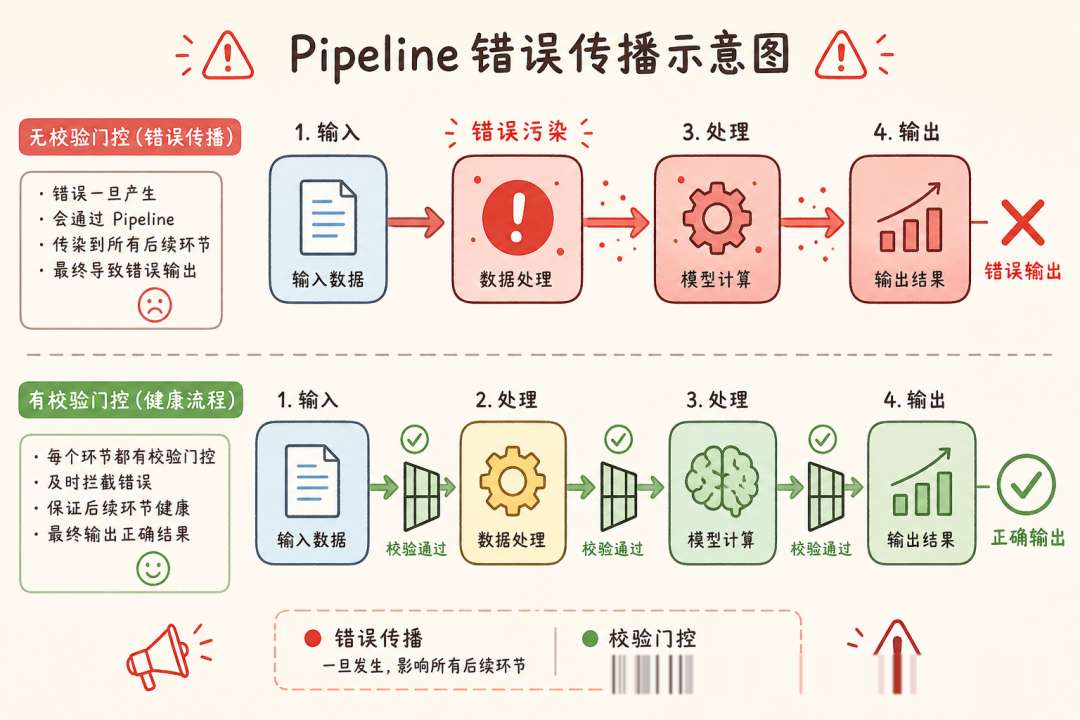
Pipeline 的致命弱点在于错误的隐性传播。上游 Agent 输出了 80% 正确的数据,下游 Agent 无法感知那缺失的 20%,继续基于残缺数据生成看似合理的结果。解法是在每个节点之间插入完整性门控——宁可中断流水线,也不要让污染数据悄悄流过。
最佳适用场景:ETL、批量文档加工、数据清洗——任何「第 N 步输出确定性地成为第 N+1 步输入」的流程。
拓扑四:Mesh — 全连接动态型
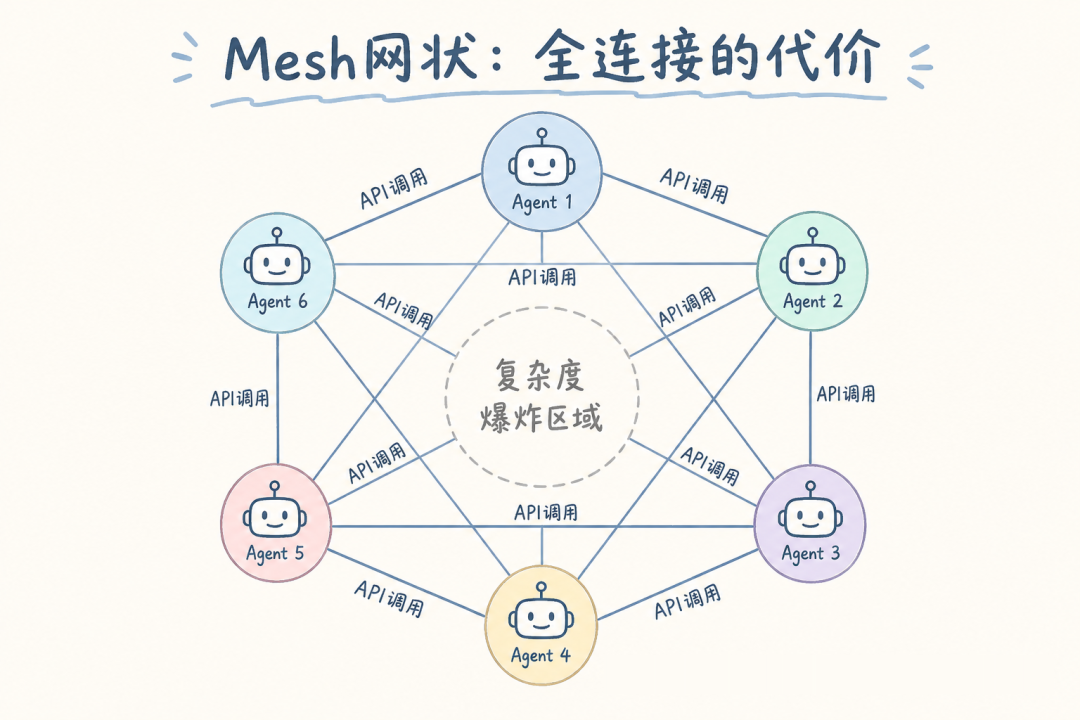
模型:所有 Agent 可以在任意时刻调用任意其他 Agent。没有预设拓扑,路由完全由运行时的 LLM 决策驱动。
这是四种架构中自由度最高的,也是复杂度天花板最高的。
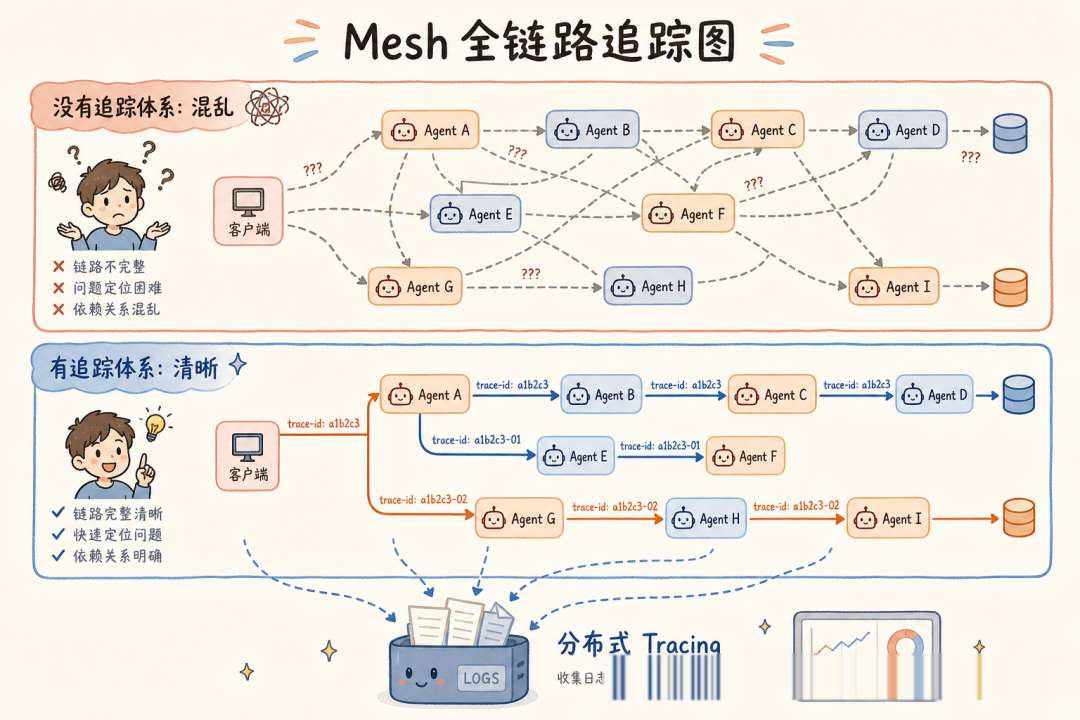
Mesh 的核心价值在于处理非线性任务——写作中途发现论据不足需要补充调研,调研后发现需要事实核查,核查后发现原始论点需要修正。这种「边做边发现」的任务天然适合 Mesh。
核心代价:可调试性接近于零(如果没有完善的 Tracing)。12 次 LLM 调用散布在 4 个 Agent 之间,执行路径每次不同,出了 bug 就像在迷宫里找出口。LangSmith Tracing 不是锦上添花,是生存基础设施。
最佳适用场景:研究型任务、创意协作、「运行时才知道下一步该干什么」的探索性工作。
横向对比:一张表看清取舍
| 拓扑 | 控制逻辑 | 可预测性 | 调试成本 | 典型场景 |
|---|---|---|---|---|
| Supervisor | 中央路由 | ★★★★★ | ★★☆☆☆ 低 | 边界清晰的分工型任务 |
| Swarm | 点对点 handoff | ★★★☆☆ | ★★★☆☆ 中 | 对话驱动的路由场景 |
| Pipeline | 线性串行 | ★★★★★ | ★☆☆☆☆ 最低 | ETL、确定性数据加工 |
| Mesh | 全连接动态 | ★★☆☆☆ | ★★★★★ 最高 | 探索性研究、创意协作 |
选型决策树:
- 任务是否线性?→ 是 → Pipeline(最简,别自找麻烦)
- 任务有分支但分支可枚举?→ Supervisor(好追踪、好维护)
- 流向由用户对话驱动、不可预测?→ Swarm(配合递归上限)
- 任务本身是探索性的、执行中动态决策?→ Mesh(必须先建好 Tracing)
工程踩坑备忘录

坑 1:Supervisor 退化为新的单体
当 Supervisor 的 prompt 超过 300 字,说明你正在把业务逻辑塞进调度层。Supervisor 应该是纯路由——「谁来做」而非「怎么做」。
坑 2:Swarm 的无限 ping-pong
Agent A 觉得该 B 做,B 觉得不归它管转回 A。解法:递归上限 + 每个 Agent 明确声明「什么不是我的职责」。
坑 3:Pipeline 的静默失败
上游返回了 5 个字段中的 4 个。下游基于残缺数据生成了表面合格的输出。真正出问题要等到线上用户触发那个缺失字段。解法:每个节点校验输出的语义完整性,而不仅仅是格式。
坑 4:成本暗增
一次用户请求触发 Supervisor + 3 个 Worker = 4 次 LLM 调用。加上重试可能是 10 次。按月算可能是单体方案的 4-8 倍。解法:Supervisor 用强模型确保路由准确,Worker 用性价比模型执行;按 Agent 维度追踪 token 消耗。
坑 5:Mesh 的黑箱化
没有 Tracing 的 Mesh 系统,等于一个不可维护的系统。上线前先确保每次执行都有完整的调用链路追踪。
收束
四种拓扑,没有绝对优劣,只有场景适配:
- 从 Supervisor 开始——它是大多数场景的安全默认选择,可控、可观测、可维护
- Pipeline 给确定性流程——简单才是最大的竞争力
- Swarm 给对话路由——handoff 机制优雅但需要熔断保护
- Mesh 留给真正需要它的场景——自由的代价是可调试性,用 Tracing 去支付这个代价
最后一条工程原则:Multi-Agent 的成本是乘法级别的。别低估每多一个 Agent 带来的复杂度增长。能用简单拓扑解决的问题,就别升级到复杂拓扑。