一文从入门到精通Prompt工程
最近在了解大语言模型相关一些技术,Prompt工程成了一个比较热的话题,甚至有公司还有prompt工程师,所以在这里对prompt做一个系统性的调研和总结,一起学习下。
1、Prompt工程及必要性
1.1、什么是 prompt
NLP之前的发展可以概括为特征工程、结构工程和目标工程。
特征工程:监督学习依赖特征的好坏,深度学习之前需要相关研究人员或者专业人士利用自己扎实的领域知识从原始数据中定义并提取有用的特征供 模型学习。
结构工程:深度学习出现之后特征能从数据中直接学习到,所以聚焦于如何设计一个合理的网络结果去学习有用的特征,从而减少对人工构建特征的依赖。
目标工程:在预训练+微调出现之后,由于预训练不需要专家知识,可直接在大规模文本上训练。因此又聚焦目标的设计,合理设计预训练跟微调阶段的目标函数,对最终的效果影响深远。
预训练任务是在大规模语言文本数据上进行的,不需要专业领域知识,训练方式是让模型补全上下文(可以理解为完形填空),因此模型的目标就是槽填充(Slot Filting)。在目标工程的过程中,发现下游任务目标与预训练目标对齐是最友好的。因此在下游任务中通过引入“文本提示符(textual prompt)”,把下游任务的目标重构成跟预训练一致的上下文补全是最好的选择。
比如对于一个输入 “I missed the bus today.” ,分别在分类任务和翻译任务下向预训练任务对齐,可以重构如下
情感预测任务
原任务:I missed the bus today. -> positive / negative
原目标:分类预测
重构任务:I missed the bus today. It is a ___ day.
重构目标:槽填充(Slot Filting)
提示词(prompt):It is a day
语言翻译任务
原任务:I missed the bus today -> J’ai raté le bus aujourd’hui
原目标:回归预测
重构任务:English : I missed the bus today. French: ___.
重构目标:槽填充(Slot Filting)
提示词(prompt):English French
1.2、Prompt 分类
按照人的参与与否: 人工设计的, 自动生成的。
按照 prompt 的形状划分:我们把这种在模板文本中包含 masked token 的模板称为填充Prompt (Cloze Prompt),它被输入到 MLM(Mask Language Model)中来预测填充这些槽的 token;把整个Prompt文本都在槽之前的称为前缀Prompt (Prefix Prompt)。通常对于生成类任务或者使用 auto-regressive LM 解决的任务,使用 prefix prompt 会更加合适;对于使用 MLM 解决的任务,cloze prompt 更加适合,因为它们与预训练任务更匹配。
填充Prompt (Cloze Prompt)
[X]. It is a ___ day.
前缀Prompt (Prefix Prompt)
English:[x]. French:____.
1.3、Prompt 工程
在特征工程、结构工程和目标工程之后,NLP的发展进入Prompt 工程阶段。
Prompt 工程:是指选择合适的模板重构下游任务向预训练任务对齐,从而指导大模型(比如:语言模型)输出的过程,涉及设计、创建和优化。
1.4、重要性
prompt工程有助于用户更好地了解大型语言模型的能力和局限性;能提高大语言模型处理复杂任务场景的能力;能实现大语言模型和其他生态工具的高效接轨;能清晰具体地引导模型输出并提升结果的相关性和准确性。
不做Promt优化
输入:今天的天气真的
输出:对不起,我无法理解“真的__”的含义,请您提供更完整的描述或问题。
做Promt优化
输入:完善以下句子:
输出:今天的天气真的
今天的天气真的非常好/不错/凉爽/糟糕/闷热/多云。
2、Prompt 构建
Prompt可以是通过人工构建的,根据人的经验知识构建合理的prompt,这也是最直接的方式。但是通过人工构建需要耗费时间跟精力, 而且即便是专业人员也不一定能构建得到最优的prompt,为此,衍生了不少自动选择prompt的方法。
2.1、Prompt模式
Prompt是根据Prompt模式指引而生成的,在设计Prompt之前先编写Ptompt模式,对目标Prompt进行详细的描述和定义。此过程类比于Java开发中的设计模式,在开发设计之前先对设计模式进行详细的描述和定义。对于AI领域中的Prompt模式,主要包含七大要素:
模式名称(Pattern Name):一个设计模式需要有一个简洁、描述性强的名称,以方便在交流和文献中使用。
问题描述(Problem):描述了在应用中遇到的问题或者需求,需要解决的具体问题。
解决方案(Solution):如何设计和实现解决问题的代码或算法,包括组成结构、相互关系等等。
效果(Consequences):描述了采用该模式的优点和缺点,以及在使用过程中可能面临的问题和解决方案。
适用性(Applicability):描述了一个设计模式可以适用的场景,和使用该模式可带来最大的收益。
结构图(Structure):展示了一个设计模式的组成结构和关系,以便更清晰地理解和实现该模式。
参考(References):该设计模式相关的文献、代码示例等,以便学习者更深入地学习和理解该模式。
以文本分类任务模式为例:
模式名称:文本分类模式
问题描述:如何将输入的文本或数据分类到不同的类别中?
解决方案:使用分类算法或预训练模型,将输入数据映射到已知的类别中。
效果:能够对文本数据进行自动分类和组织,提高文本数据的管理和分析效率。
适用性:适用于各种文本分类任务,包括垃圾邮件过滤、情感分析、新闻分类、文本标签等。
结构图:文本分类模式通常包括数据预处理、特征提取、模型训练和模型评估四个步骤。
参考:常见的文本分类算法包括支持向量机、卷积神经网络等。常见的工具包括、TensorFlow、PyTorch等。
在定义好Prompt模式之后,基于此模式去设计Prompt就不会偏离Prompt设计的初衷。因此Prompt实际上是起到了明确Prompt设计需求的作用,后续所有Prompt的设计都要满足此模式的规定。
2.2、ChatGPT官方Prompt模式
ChatGPT官方给出了4种基础Prompt模式和几种增强模式。

2.2.1、特定指令(By specific)【基础】

在这种模式下,我们给模型提供一些特定信息,例如问题或关键词,模型需要生成与这些信息相关的文本。这种模式通常用于生成答案、解释或推荐等。特定信息可以是单个问题或多个关键词,具体取决于任务的要求。比如
-
定义一下 prompt 工程。
-
翻译一下:永和九年,岁在癸丑,暮春之初,会于会稽山阴之兰亭,修禊事也。
-
转为现代汉语:永和九年,岁在癸丑,暮春之初,会于会稽山阴之兰亭,修禊事也。
此模式重点是:Output Driven。在提示的开头包含所有相关信息,包括任何上下文或期望的结果,以及 长度,格式样式等。诸如于:用 100 字总结一下 ChatGPT。
2.2.2、指令模板(Instruction Template)【基础】
在这种模式下,我们给模型提供一些明确的指令,模型需要根据这些指令生成文本。这种模式通常用于生成类似于技术说明书、操作手册等需要明确指令的文本。指令可以是单个句子或多个段落,具体取决于任务的要求。
输入
使用 STAR 原则与下面的格式总结一下这段话:
最近几天,因为工作 + 兴趣的原则,我在研究用 text 2 image 来展示如何演进 prompt、用 text 2 article 来展示充足 prompt 的优点、结合 GitHub Copliot 来实现 prompt 完成工作。然后,我在本地部署了一个 Stable Diffusion、使用 ChatGPT 写作展示 text 2 article、在 IDEA 中使用 GitHub Copilot。最后,得到了多篇文章和好多的文章阅读量、几个 Jupyter 代码段、以及一些经验。
情境(Situation):
任务(Task):
行动(Action):
结果(Result):
输出
情境(Situation): 最近几天,在工作和兴趣的驱动下,研究如何使用 text 2 image 和 text 2 article 展示 prompt 演进以及结合 GitHub Copliot 来完成工作。
任务(Task): 研究如何使用 text 2 image 展示 prompt 的演进过程 研究如何使用 text 2 article 展示 prompt 的优点 结合 GitHub Copliot 来实现 prompt 完成工作
行动(Action): 本地部署了一个稳定的 Diffusion 模型 使用 ChatGPT 撰写文章来展示 text 2 article 的效果 在 IDEA 中使用 GitHub Copilot
结果(Result): 得到了多篇文章和很多的文章阅读量 获得了几个 Jupyter 代码段以及相关经验
2.2.3、代理模式(By proxy)【基础】
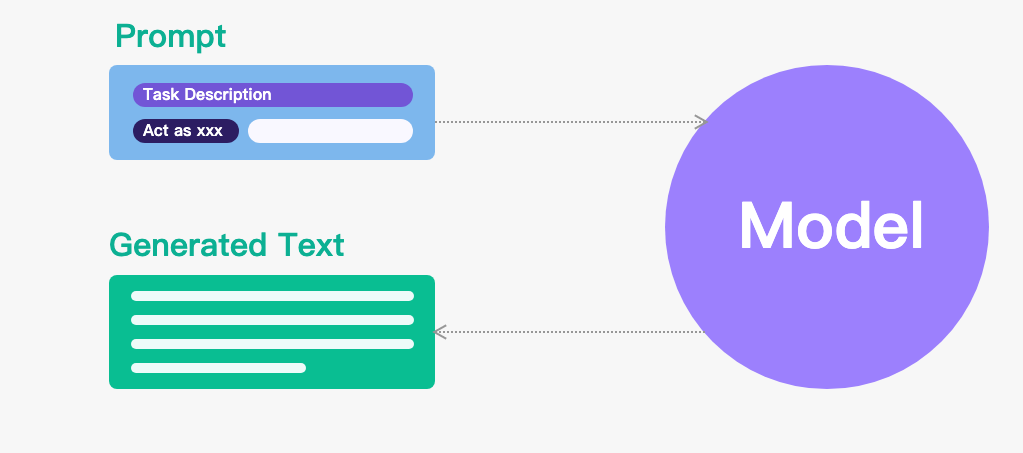
Proxy 模式是指用户可以要求 ChatGPT 以特定的身份、角色或者身份扮演某个特定的人、角色或对象来生成回答。这种模式通常用于模拟某个特定人物的语言风格和语境,生成特定情境下的对话、回答或其他形式的文本。比如当使用 ChatGPT 来代替某个人或实体时,可以使用 by proxy 模式。
例如,可以使用以下 prompt 提问 ChatGPT 代替某个公司的客服
我是一家餐饮公司的客服,有顾客反馈说我们的菜品质量有问题,我们该怎么处理呢?
ChatGPT 会扮演客服的角色,并根据提示来回答,从而帮助公司解决问题
您好,很抱歉听到您的反馈。我们将会仔细审核您的反馈,并尽快采取相应措施来解决这个问题。为此,我们需要更多的信息来进一步了解您的反馈,包括哪些菜品有问题,具体问题是什么等。请问您可以提供更多的信息吗?
2.2.4、示例模式(By demonstration)【基础】
在这种模式下,我们给模型提供一些示例文本,模型需要生成与示例文本类似的文本。这种模式通常用于生成类似于给定示例的文本,例如自动生成电子邮件、产品描述、新闻报道等。示例文本可以是单个句子或多个段落,具体取决于任务的要求。
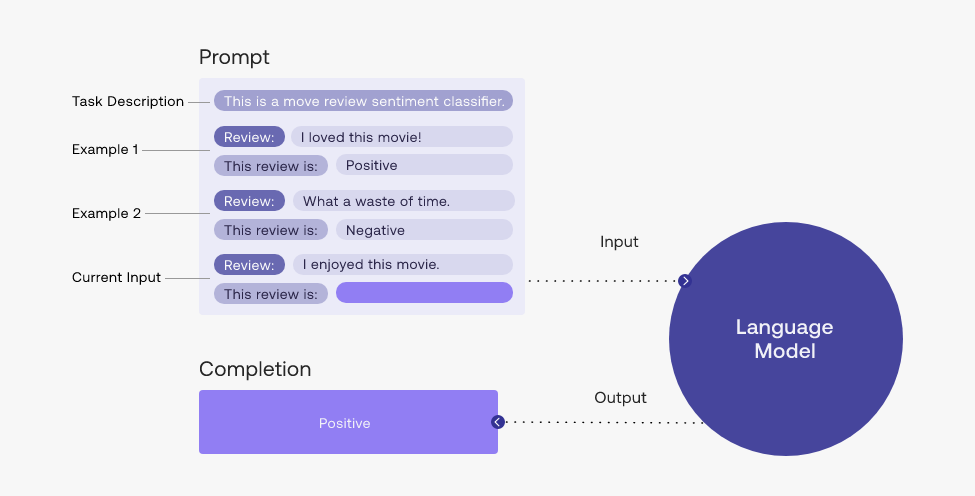
2.2.5、符号化模式【增强】
符号化方法通常通过定义符号、符号之间的关系以及基于这些关系的规则来表示知识。
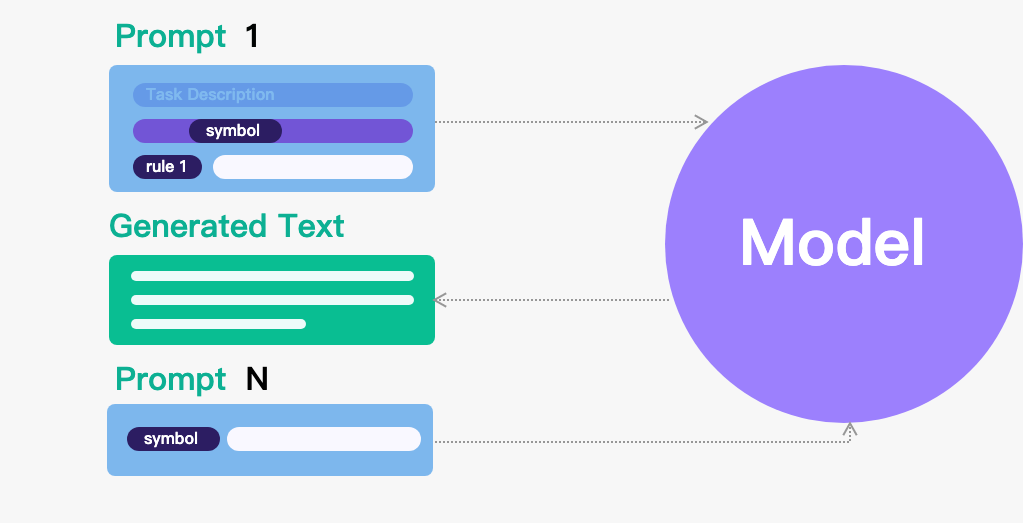
我们来玩一个名为 gkzw 的写作游戏,每当我说 gkzw,你开始写作,规则如下:
- 字数不少于 200 字。
- 文中必须出现 “小明”。
明白了吗?
2.2.6、反向 Prompt 模式【增强】
Negative prompt(负向提示)是一种在使用语言模型时,针对模型输出不希望的结果而设置的一种文本输入方式。通过使用负向提示,可以帮助模型避免输出不良、不准确或不恰当的文本。具体来说,负向提示通常是以否定的形式呈现的,例如在文本生成任务中,使用“不要写…”、“不要提及…”、“不要使用…”等方式来限制模型生成不想要的文本。在情感分析任务中,使用“不是…”、“并不…”等方式来指示模型识别出一段文本的负面情感。在QA(问答)任务中,使用“不是…”、“不包括…”等方式来指示模型回答问题时避免输出错误或不准确的答案。
2.2.7、再生成模式【增强】
根据 AI 提供的信息,再让 AI 生成内容。当我们无法确定我们的 prompt 是否准确,便可以通过 AI 来帮我们丰富 prompt 。再去除掉不合适的词,进行润色,就可以再创作。
生成一个Stable Diffusion 的 prompt去生成图片
phodal: 我想写一段话描述一张照片,帮我美化一下:一年轻女子穿着裙子,背对着镜头,在海边看着日落,太阳已经到地平线下面了,她的头发在风中飘动。
这张照片中的场景令人心醉,一位年轻女子穿着一条裙子,站在海边,背对着镜头,凝视着地平线下的夕阳。太阳已经沉入了海面,一片金黄色的光芒在海面上弥漫,照亮了整片海洋,仿佛这个时刻被定格在了时间的某个角落里。女子的头发随着微风轻轻飘动,轮廓被余晖映照得柔和而温暖。她的目光凝视着远方,仿佛在思考着生命的意义和无尽的未来。这张照片中蕴含着一种深刻的内涵,让人感受到时间和自然的力量,也让人思考着自己在这个宏大而美丽的世界中的角色和意义。
2.2.8、模板方法模式【增强】
模板方法模式是一种行为型模式,它定义了一个操作中的算法骨架,将某些步骤延迟到子类中实现,从而使得子类可以在不改变算法结构的情况下重新定义算法中的某些步骤。
在接下来的例子中,我们会创建一个 muji 游戏中。在游戏的实现可以分为多个步骤,例如初始化游戏、生成随机数、获取用户输入、计算得分等等,而这些步骤可以通过模板方法模式来进行实现。
在这个游戏里,我们结合了几种不同的模式:
Instruction:让 ChatGPT 创建了一个名为 wula 的游戏,并定义了游戏的步骤。
Specific:让 ChatGPT 用 JavaScript 编写一个程序
Proxy:让 ChatGPT 作为 JavaScript Console 执行程序,并返回结果。
Specific:让 ChatGPT 做总结
Demonstration:提供了一个示例,让 ChatGPT 理解游戏的步骤。
2.2.9、拆解模式【增强】
已知问题:ChatGPT 当前版本会丢失上下文。对于复杂问题,无法一次性输出全部内容,需要进行拆解。
我们来定义一下 DDD 游戏的步骤,一共有 6 个步骤,步骤如下:
第一步. 拆解场景。分析特定领域的所有商业活动,并将其拆解出每个场景。
第二步. 场景过程分析。选定一个场景,并使用 “{名词}已{动词}” 的形式描述过程中所有发生的事件,其中的名词是过程中的实体,其中的动词是实体相关的行为。
第三步. 针对场景建模。基于统一语言和拆解出的场景进行建模,以实现 DDD 设计与代码实现的双向绑定。
第四步. 持续建模。回到第一步,选择未完成的场景。你要重复第一到第四步,直到所有的场景完成。
第五步. 围绕模型生成子域。对模型进行分类,以划定不同的子域,需要列出所有的模型包含英语翻译。
第六步. API 生成。对于每一个子域,生成其对应的 RESTful API,并以表格的形式展现这些 API。
需要注意的是,当我说 “““ddd 第 {} 步: {}””” 则表示进行第几步的分析,如 “““ddd 第一步: 博客系统””” 表示只对博客系统进行 DDD 第一步分析。我发的是 “““ddd: {}”"",则表示按 6 个步骤分析:
明白这个游戏怎么玩了吗?
2.2.10、ICIO Prompt 框架
ICIO是Elavis Saravia 总结的框架,主要包含Instruction(指令)、Context(背景信息)、Input Data(输入)和Output Indicator(输出)四个部分。
Instruction【必须】: 指令,即你希望模型执行的具体任务。
Context【选填】: 背景信息,或者说是上下文信息,这可以引导模型做出更好的反应。
Input Data【选填】: 输入数据,告知模型需要处理的数据。
Output Indicator【选填】: 输出指示器,告知模型我们要输出的类型或格式。
2.2.11、CRISPE Prompt 框架
相比ICIO框架更加复杂,但完备性会比较高,适合用于编写 prompt 模板。 主要包括Capacity and Role(能力与角色)、Insight(洞察力)Statement(指令)、Personality(个性)和Experiment(尝试)五个部分:
Capacity and Role:能力与角色,你希望 ChatGPT 扮演怎样的角色。
Insight:洞察力,背景信息和上下文(坦率来说用 Context 更好)。
Statement:指令,你希望 ChatGPT 做什么。
Personality:个性,你希望 ChatGPT 以什么风格或方式回答你。
Experiment:尝试,要求 ChatGPT 为你提供多个答案。
2.2.13、CIRCD Prompt 框架
提出了一个由五个关键部分组成的提示设计框架:上下文、说明、相关性、约束和演示。
Context:上下文,设计提示时,上下文是关键,确保为指定任务提供足够的背景信息。
Instruction:说明,指导模型做什么以及对它的期望。清晰、简洁和具体很重要。
Relevance:相关性,需要引用的特定信息,可以是相关文章或数据的链接,或用户提供的特定输入。
Constraint:约束,这可能涉及指定输出格式、要使用的语言类型,甚至是输出的长度。
Demonstration:示范,LLM通过示例理解预期的内容,有效传达具体细节,生成符合用户期望的文本。
2.3、Prompt 框架要素汇总
基于上述框架,prompt要素汇总后包含但不限于:能力与角色、指令、上下文、相关性、说明、约束、案例。
能力与角色【Capacity and Role】 比如:你是一个程序员、现在你是一个律师
指令【Statement】 指令也可以被称为任务,比如“写一段sql”、“写一首诗”等,是对一系列类似工作或事项的抽象描述,这里并不知道指令的细节,如何完成、什么样的。
说明【Instruction】 说明是指对模型输入的具体问题和事项,是对指令任务的具体描述,比如“计算一下近一周每天的DAG3”。
上下文【Context】 上下文是对语境、环境、知识背景的指定,比如特定领域也有特有的知识或专业术语,比如DAG3是指活跃人数大于3的组织数,不是有向无环图(DAG)。
相关性【Relevance】 相关是指要完成某个指令或任务所需要用的相关是内容,比如写一段sql,sql里面所涉及的表有哪些,表的字段有哪些、每个字段的数据类型是什么?
约束【Constraint】 约束也可以说是大模型的输出,又是需要对模型的输出进行约束,便于理解和整理,比如“所有关键词要大写”或者“输出json格式”等。
案例【Demonstration】 案例是指模型可参考的例子,指导模型学习例子然后学以致用,特别适合于特定的垂类场景,这类场景的数据在模型训练的时候几乎是没有的,所以对模型效果会有很好的提升。
尝试【Experiment】 同样的prompt,多次试验的结果很多时候是不同的,可以让模型多尝试几次,然后从中挑出最相关最准确的。
2.4、Prompt 设计原则
清晰具体 提示应清楚说明模型预期回答的任务或问题。避免提示歧义或含糊不清,因为这会导致回答不明确或不相关。
逐步迭代 从简单开始,不断实验和迭代,根据实验结果不断调整Promot逼近最佳结果。
提供上下文 提示应该为模型提供足够的上下文来理解任务并生成相关响应。这可以包括相关的背景信息、示例或约束。
使用自然语言 以模型可以理解和响应的自然对话风格编写提示。避免使用可能混淆模型的复杂或技术语言。
简明扼要 保持提示简明扼要。避免不必要的细节或信息,这些细节或信息可能会分散模型对手头任务的注意力。
避免复杂的句子结构 使用复杂的句子结构会使模型混淆,导致生成的输出效果不佳。使用简单的句子和直截了当的语言使模型更容易理解并生成所需的输出。
避免歧义 确保提示是具体的,避免歧义。避免使用具有多重含义的词或可以用不同方式解释的短语。
使用关键字 在提示中使用与对话主题相关的关键字。这有助于聊天机器人了解上下文并做出适当的响应。
考虑目标受众 考虑生成的响应的目标受众并相应地调整提示。使用观众可能理解并与之相关的适当语言、术语和示例。
使用适当的格式 使用适当的格式(例如项目符号点、编号列表或粗体文本)来突出提示中的关键信息。这可以帮助模型理解提示的结构和组织。
测试和优化 使用模型测试提示并根据生成的响应的质量对其进行优化。反复细化提示,直到生成的响应具有高质量和相关性。
2.5、Prompt 模式扩展
零样本提示(zero-shot)
不向模型提供任何案例
少样本提示(few-shot)
给模型提供少量案例
链式思考(CoT)提示
提供案例,并对案例答案给出推导过程。通常与少样本提升结合使用。零样本的时,“让我们逐步思考”这个技巧会非常有效。
自我一致性
同一个prompt执行多次,以投票方式决定最终答案。在算数和常识推理中效果较好
知识生成提示(类比官方“再生成模式”)
给模型提供任务相关的知识,打破模型的局限性。可以体现在Promot要素的“相关”里面。
链式思考(CoT)提示
提供案例,并对案例答案给出推导过程。通常与少样本提升结合使用。零样本的时,“让我们逐步思考”这个技巧会非常有效。
自动提示
用一个模型对输入的问题生成一组指令,然后用这一组指令去执行,然后根据评估分数选择最合适指令
Active-Prompt
对一组问题生成k个答案,基于k个答案的不确定度(不一致性)选择最不确定问题由人工标注,然后用新标注的案例来推断。
方向性刺激提示
ReAct框架
多模态思维连提示
基于图的提示
3、自动构建
人工构建prompt的方式有两个弊端,一方面人工构建prompt和测试prompt效果耗费时间跟精力,另一方面是即便是专业人士也不一定能通过人工的方式构建最优的prompt。
为了解决这个问题,自然而然就衍生自动构建prompt的方式,自动构建prompt可以分为离散型的prompt(prompt可以用具体的字符表示)和连续型的prompt。
3.1、Prompt 挖掘
构建prompt候选集:挖掘可能的prompt。例如涉及出生地点的数据“Barack Obama was born in Hawaii”可以被转换为相应的prompt ”
筛选prompt:可以用效果最好的prompt作为最终选择,也可以去集成多种prompt的效果,将多种prompt根据在训练集上的效果进行排序,选择其中topK个,通过直接平均得到模型在这个K个prompt的效果,最终得到的是K个prompt的集成。在前面集成多个prompt的基础上,还能多进一步的优化,通过训练得到每个prompt的权重。
3.2、Prompt 扩展
这种方式依赖于现有的种子prompt,通过把种子prompt扩充得到更多的候选prompt,然后从中选取在目标任务表现最好的prompt作为最后选择。
对于一个种子prompt,首先将这个种子prompt翻译成另外一种语言,得到B个候选,然后将这B个候选再翻译为原语言,每个又有B个候选。所以一个种子prompt可以获取B*B个候选prompt,对这些候选prompt排序,将得分最高的K个作为自动构建prompt的结果。还可以对Prompt做同义词替换,将prompt中的词用它的同义词去替换,从而得以扩充prompt。
3.3、梯度搜索
3.3.1、Trigger 搜索
在给定模型f,我们想要搜寻trigger,使得对于任意的输入x,模型最终分类的结果都是不变的,也就是f(trigger;x)=y。首先选择trigger的长度,接着通过重复”the”,“a”等方式初始化trigger的片段,然后将这些trigger片段跟输入拼接到一起,不断迭代去替换trigger片段里的token使得模型预测结果f(trigger;x)跟期望的目标之间的距离最小化。迭代优化需要用到预测结果跟期望目标之间的损失在模型中的梯度,所以属于基于梯度的方法。
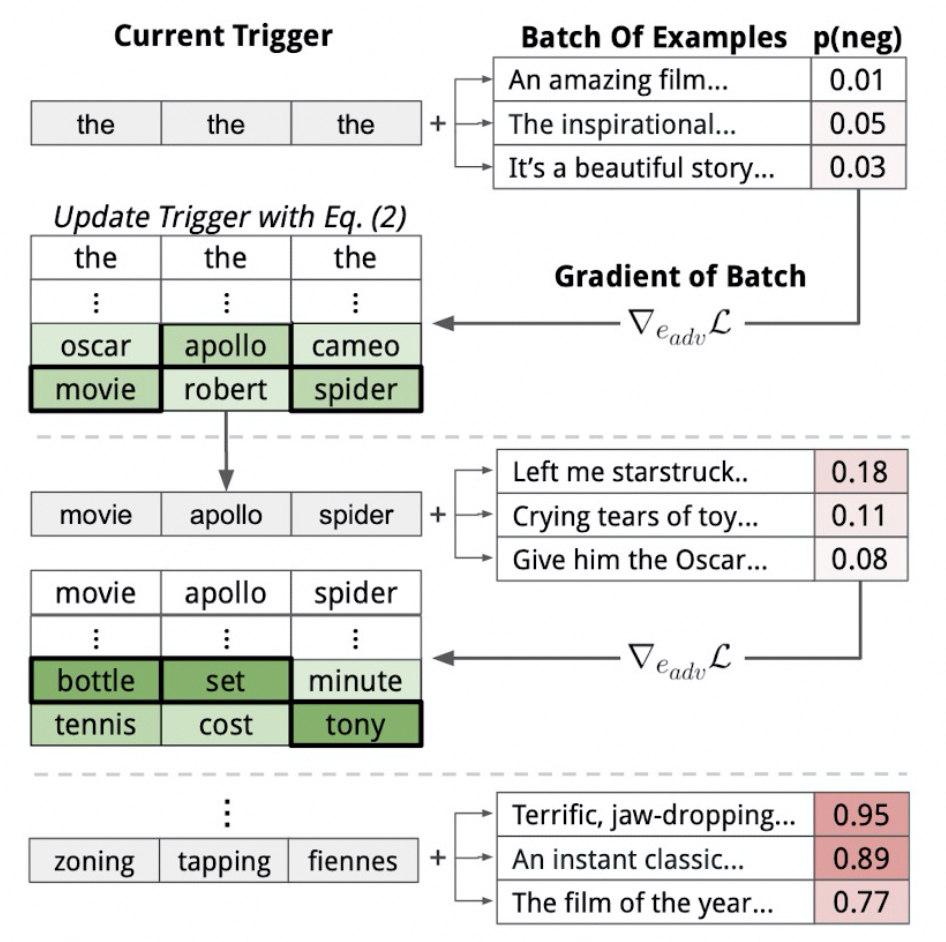
3.3.2、自动Prompt
是一种为下游任务自动搜索prompt的方式,它的目标是在搜寻合适的prompt,使得下游任务的表现最佳。我们想去搜寻那些可以在所有prompt共享使用的trigger,这里的trigger会先用[MASK]进行初始化,然后不断迭代去更新,使得相应的最大似然函数尽可能大。在每一步中,首先计算将某个trigger的token替换为另一个token的对数似然函数的变化的一阶近似,从而可以得到变化最大的K个token(这里的变化是计算相应的token的词嵌入跟对应trigger的token在嵌入层的梯度的乘积,变化越大说明越合适),将其作为候选集。对于候选集的元素,计算在相应prompt在数据中的表现,保留效果最好的部分,作为更新得到的prompt。
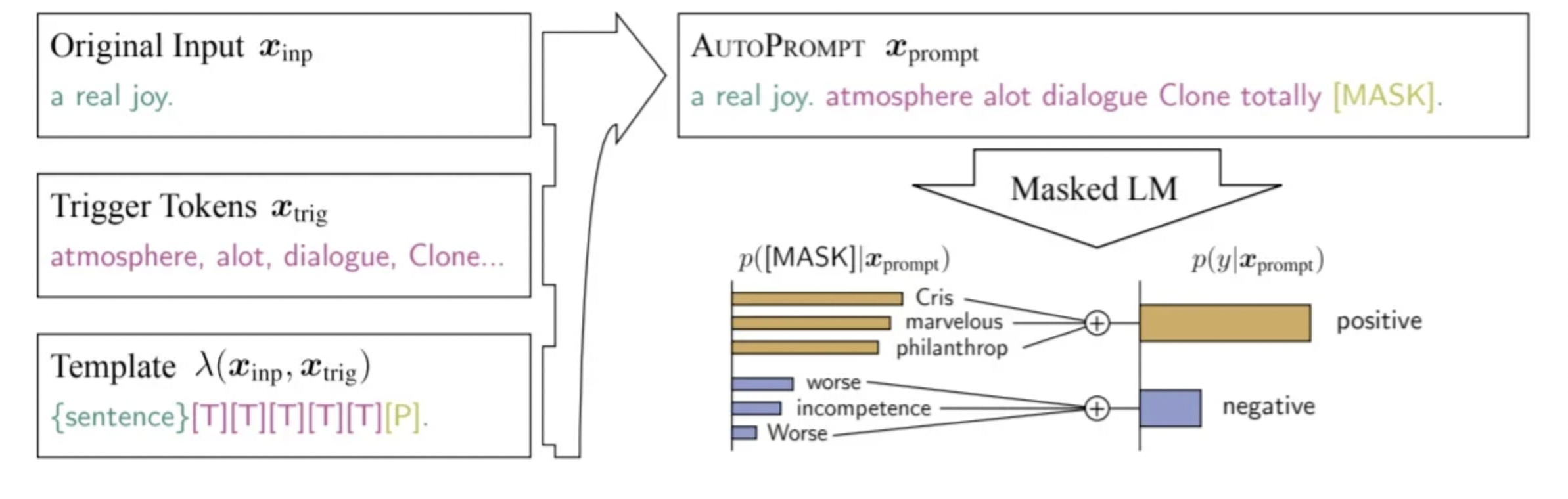
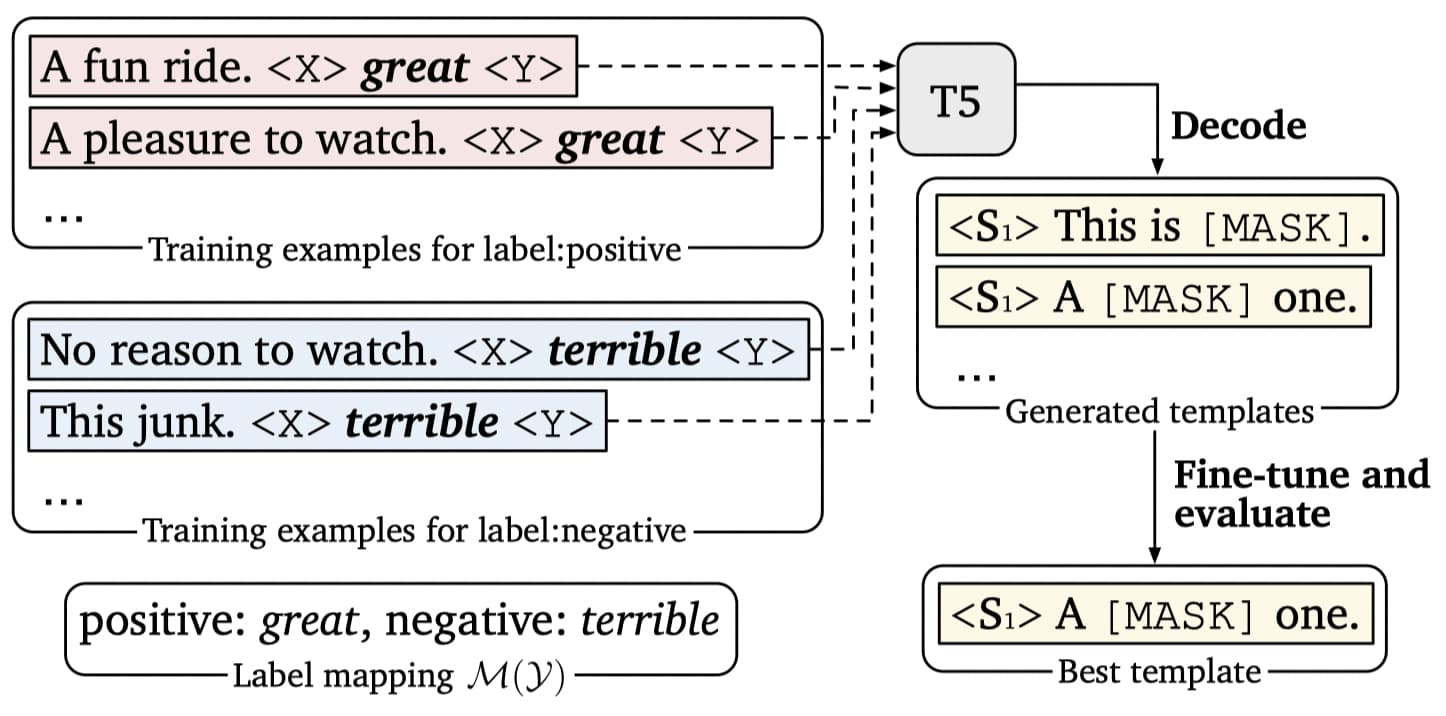
3.3.3 Prompt 模型生成
利用模型T5通过生成的方式去构建prompt。模型T5预训练任务就是去预测那些[MASK]位置的token,所以可以将句子输入T5,然后让T5去生成相应的prompt,这样也就不用去指定prompt对应的token数量了。例如图中左边是原始的数据,通过规则可以转化为右边的格式,M(y)是答案空间(不清楚的可以去看入门篇),

English:[x]. French:[y].,
-
[MASK]:[x]. [MASK]:[y]. -
-
[a]:[x]. [b]:__y’_
3.3.4 Prompt 模型打分
通过人工构建prompt的方式生成候选集,然后让语言模型对候选集里的prompt打分,选择最合适的prompt。前面提到的涉及多个prompt排序都是直接在看下游任务表现的,而这里却是用语言模型来打分。
3.4、多模板方法
受集成学习同时运用多个模型的启发,还有一些工作尝试使用多个 Prompt 来共同完成任务,称为多模板学习 (multi-prompt learning)。常见的多模板方法有模板集成、模板增强、模板合成以及模板拆分, 如下图所示:
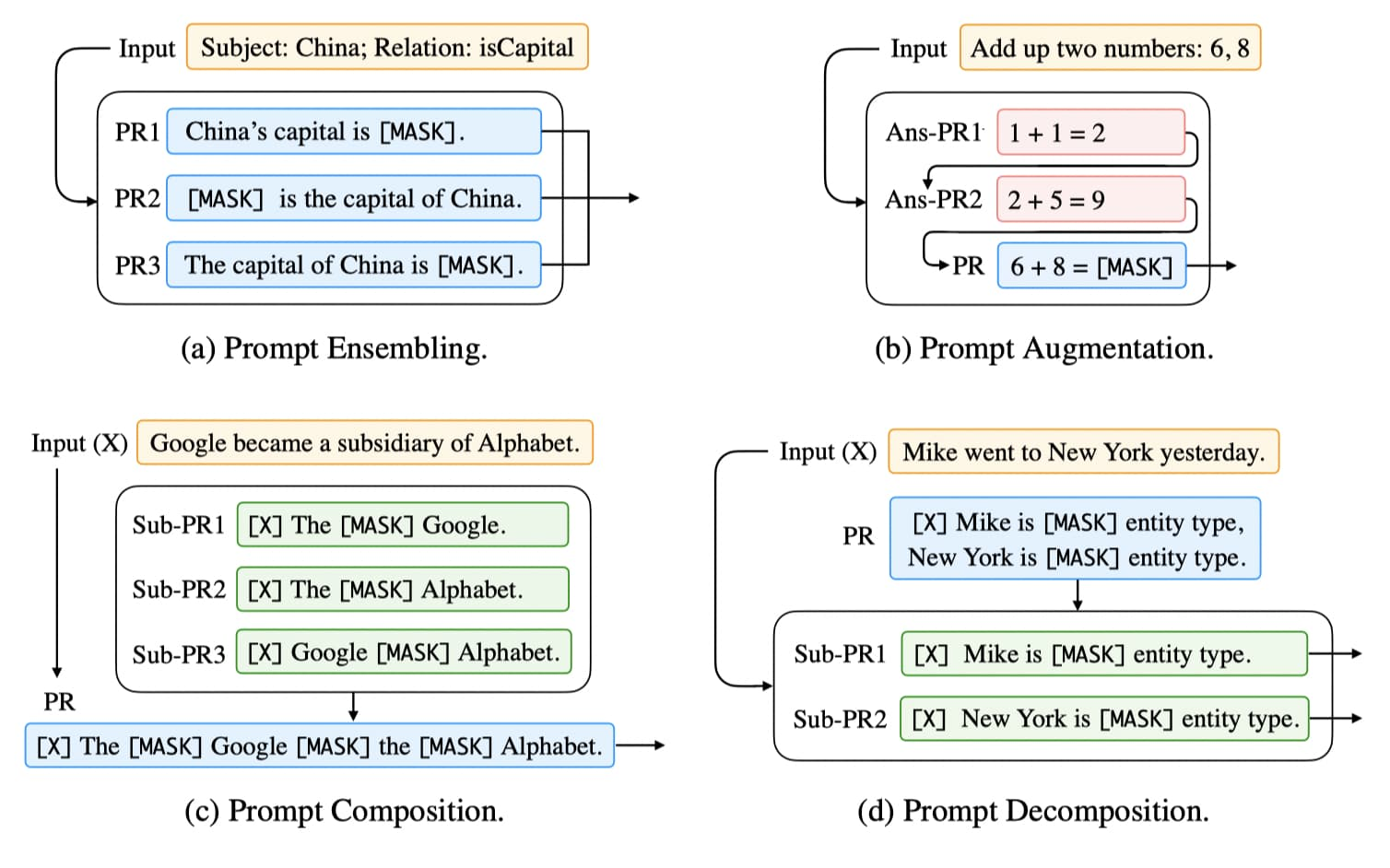
3.4.1、模板集成 (Prompt Ensembling)
使用多个 Prompt 共同对输入进行预测,如图 (a) 所示。相比单模板方法,模板集成可以利用不同 prompt 的互补优势;减轻构建模板的成本,毕竟要选出性能最优 prompt 非常困难;缓解对模板的依赖,使得性能更稳定。
$q_{\textbf{p}}(y\mid \textbf{x}) :=\frac{1}{K}\sum_{i}^K p(\texttt{[MASK]}=v_y\mid P_i(\textbf{x}))$
3.4.2、模板增强 (Prompt Augmentation)
又称示例学习 (demonstration learning)。每次在输入 xx 时,还会提供一些已回答的 prompts 作为示例去引导 LM,如图 (b) 所示。例如我们要预测中国的首都,不是简单地输入“China’s capital is [MASK][MASK] .”而是还会拼接一些填充好的模板作为示例:“Great Britain’s capital is London . Japan’s capital is Tokyo . China’s capital is [MASK][MASK] .” (相当于提供了一些 few-shot 示例)。
3.4.3、模板合成 (Prompt Composition)
适用于由多个子任务组合而成的任务。首先为每个子任务设计对应的子模板 (sub-prompt),然后基于所有的子模板定义一个合成模板 (composite prompt),如图 (c) 所示。
3.4.4、模板拆分 (Prompt Decomposition)
有时候我们需要对一个输入预测出多个结果(例如序列标注),这时候直为输入 xx 构建完整的模板非常困难。模板拆分将完整模板拆分为多个子模板 (sub-prompt),然后分别预测每一个模板的答案。图 (d) 展示了一个命名实体识别 (NER) 的例子,其首先将输入转换为 text span 组成的集合,然后应用子模板来预测每一个 span 的实体类型。