Claude Code 为什么拒绝 RAG,选择了"原始"的 grep?

基于 Claude Code 源码分析,拆解 Anthropic 在代码检索上的架构决策与设计哲学。
引子
一道字节跳动 AI Agent 岗位的面试真题:为什么 Claude Code 不用 RAG 检索代码,而是直接用 grep?

乍听有些反直觉。RAG 几乎是当下 AI 应用的"默认基础设施",而 Claude Code 作为公认最强的 AI 编程工具之一,居然连 embedding 和向量库都没碰,全靠 grep + 文件读取这种最"土"的方式搞定代码上下文。
这背后不是技术力不足,而是一套深思熟虑的架构哲学。本文从源码出发,逐层拆解。

全文脉络:
- 代码检索的本质问题是什么
- RAG 方案的工作原理
- RAG 在代码场景的五大硬伤
- Claude Code 的替代方案:三件套 + 子 Agent
- 多轮迭代循环:Agent 范式的核心
- 两种设计哲学的根本分歧
- 各自适用场景
1. 代码检索:核心矛盾是什么?
问题的本质很简单:LLM 只能处理上下文窗口内的文本,但代码库远超窗口容量。
即便是支持 1M token 的 Claude Opus 4.7(约 200 万字),面对一个中型项目的几百万行代码加依赖库,依然远远不够——还得预留空间给系统提示、对话历史和工具调用结果。

因此必须有一个"检索层":从海量代码中精准抽取与当前任务相关的片段,塞入有限的上下文窗口。
类比查字典——你不会通读整本词典,而是通过拼音索引定位到目标页。
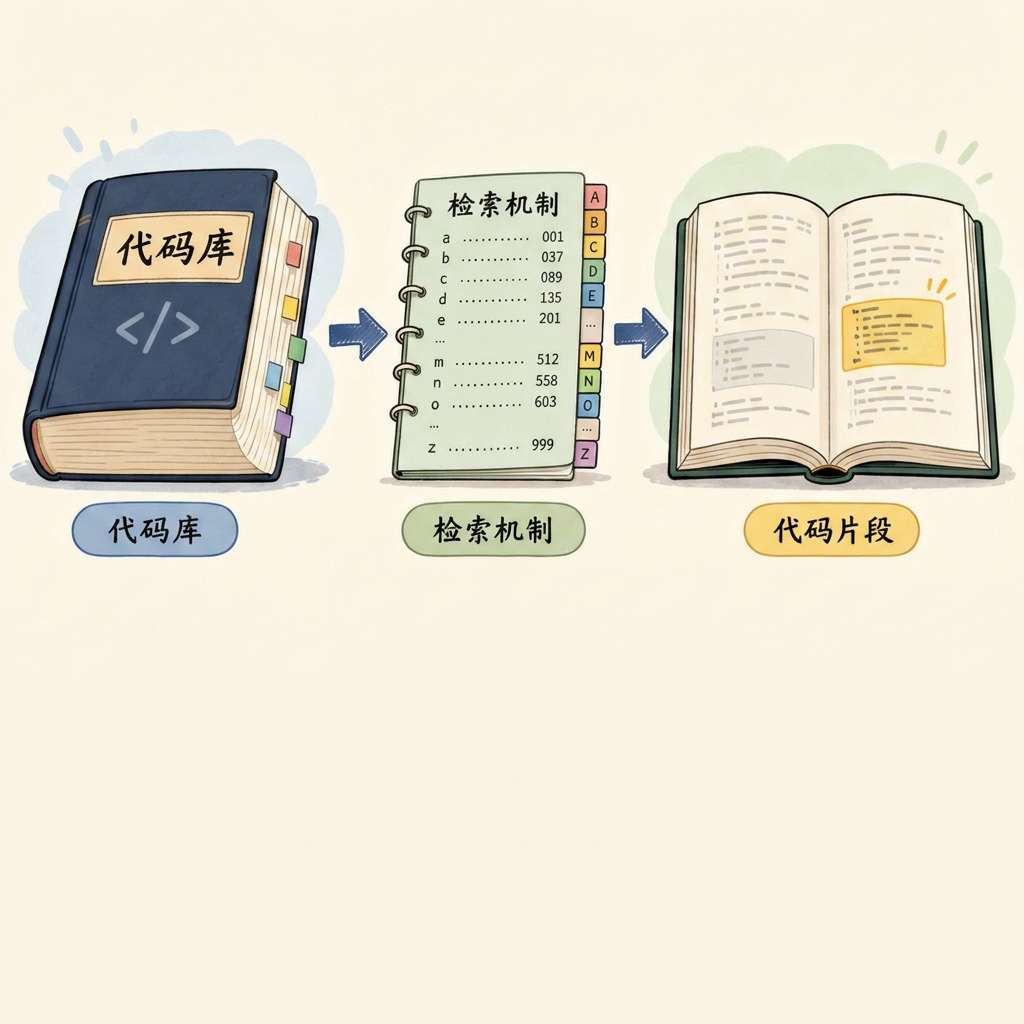
不同方案的差异,就在于"怎么建索引"和"怎么定位"。
2. RAG:预构建索引 + 向量近似匹配
RAG 的核心流程可以用"图书馆分类卡片"来类比:提前为每本书制作索引卡片,读者来了直接查卡片定位。
具体四步:
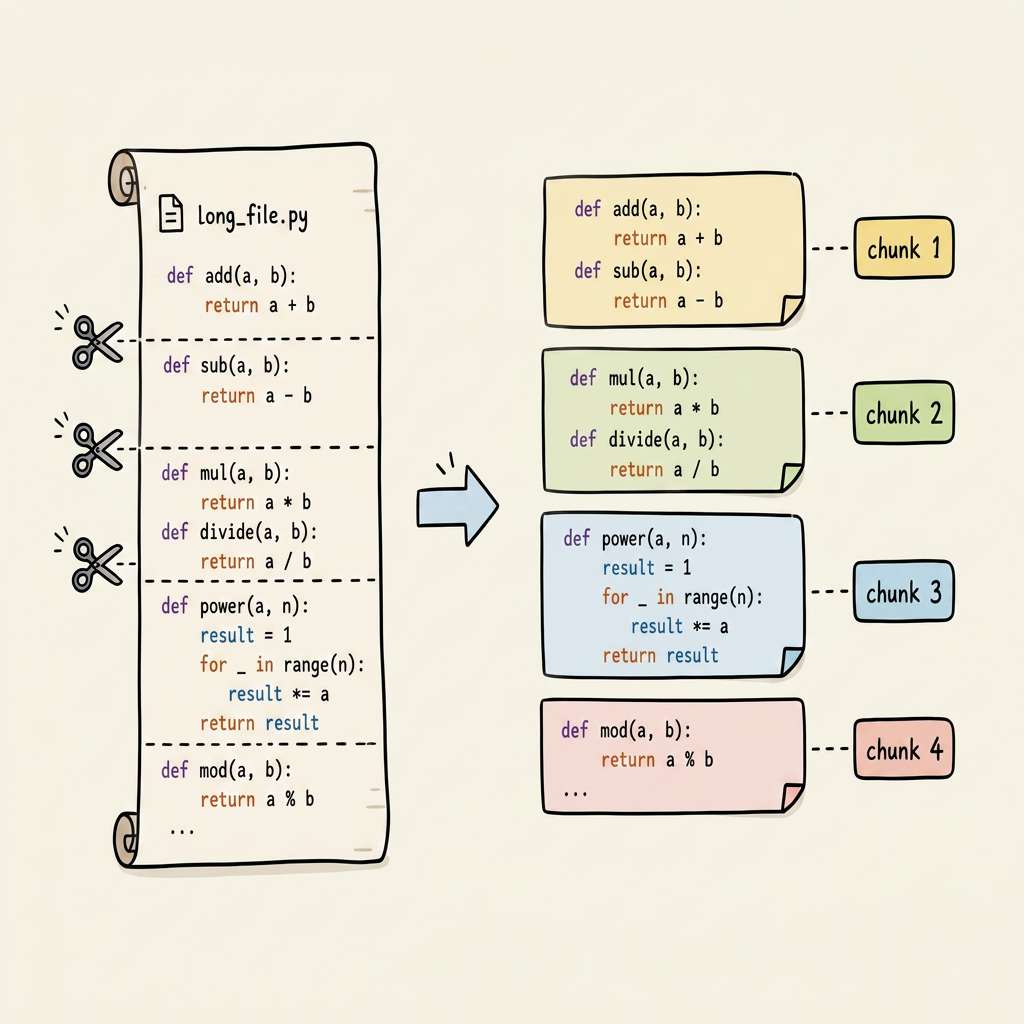
切片(Chunking):将代码按函数、类或固定行数拆成片段。
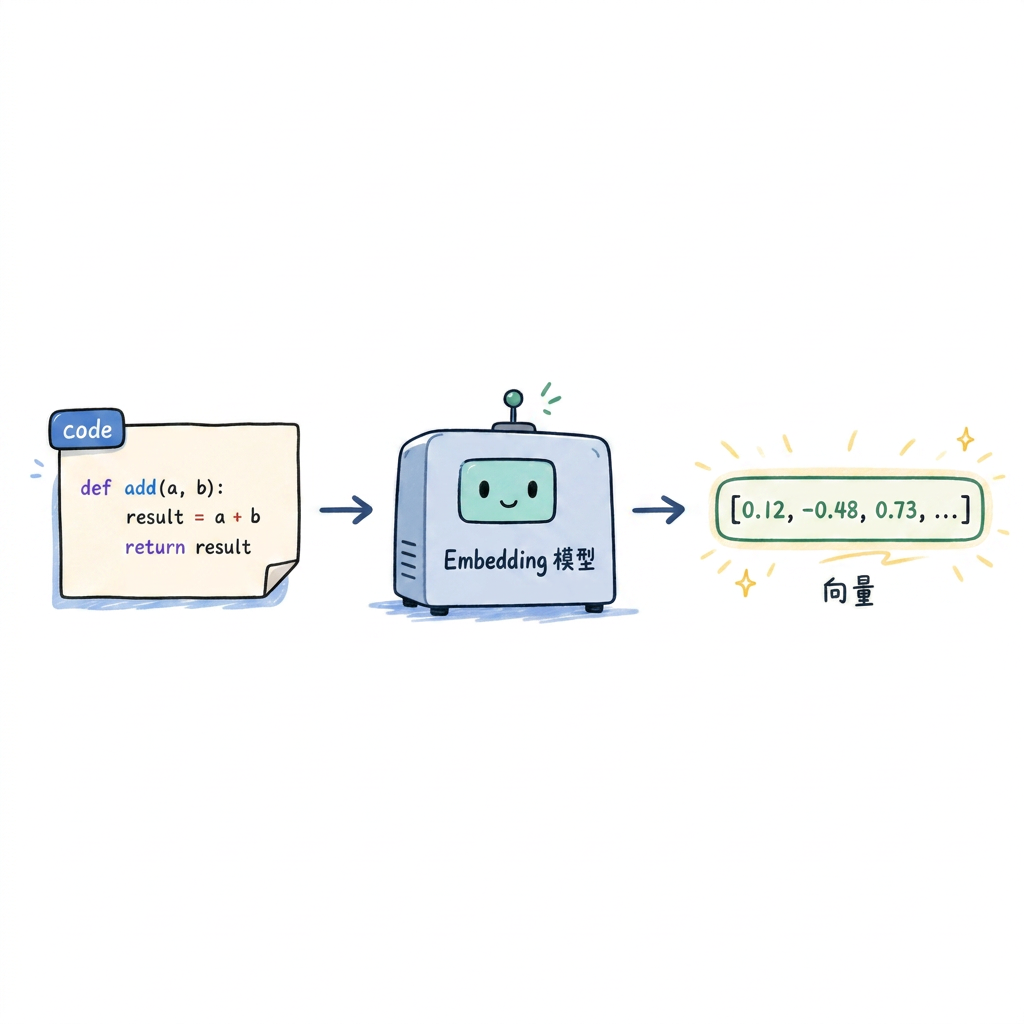
向量化(Embedding):每个片段经过 embedding 模型转化为高维向量——相当于计算"语义指纹"。
建索引(Indexing):所有向量存入 Faiss / Pinecone / Milvus 等向量数据库。
召回(Retrieval):用户提问向量化后,在库中找 Top-K 最近邻,拼入 prompt。
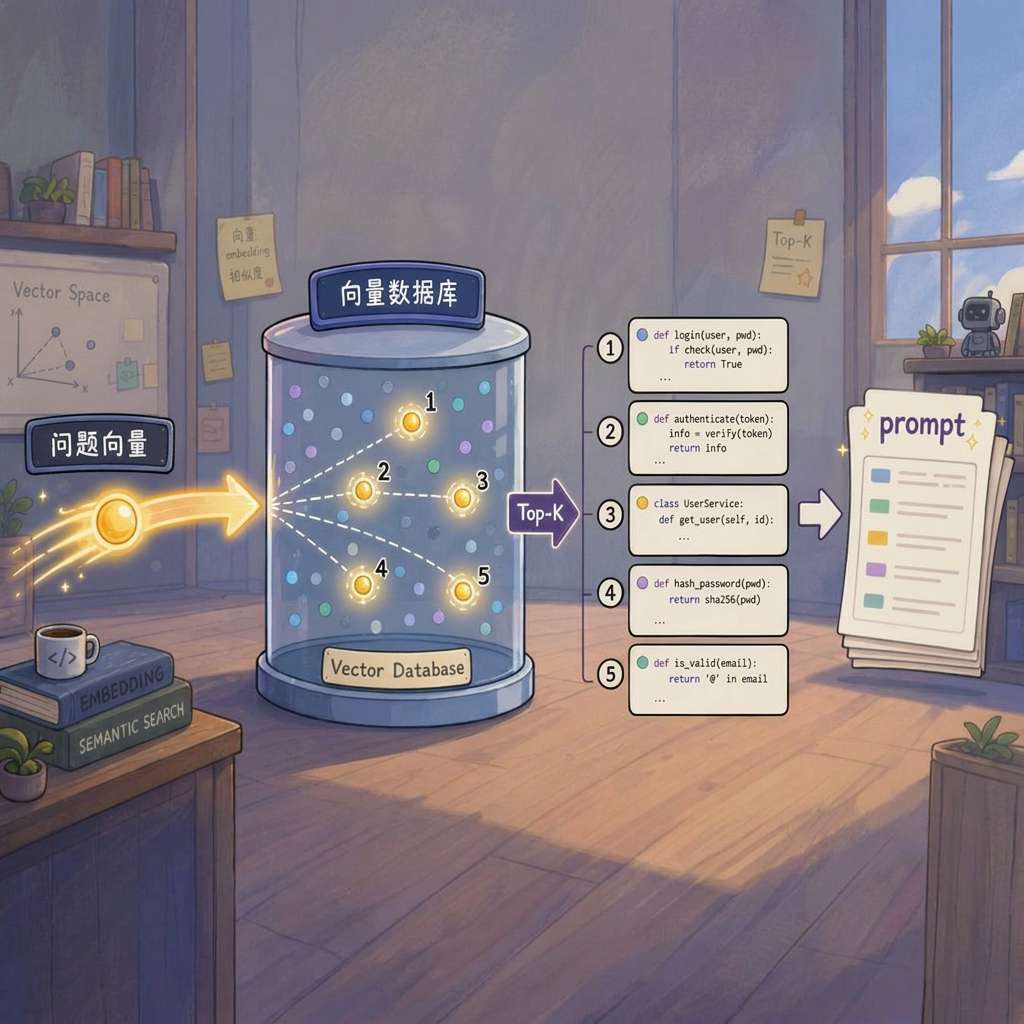
本质:RAG 把"找代码"转化为"算向量相似度"。在静态文档、FAQ 知识库等场景效果优异。但代码场景呢?
3. RAG 在代码场景的五大硬伤
3.1 结构性切片困难
代码有严格的语法结构。按固定行数切片,极易在 if/else、函数调用边界处断裂。模型拿到残缺片段,幻觉概率飙升。

3.2 精确匹配无能
向量召回的本质是"找相似的",不是"找对的"。你要 getUserById,它会把 getUserByName、getUserByEmail、fetchUserInfo 全拉过来——语义相近,但不是你要的那一个。

3.3 索引时效性噩梦
代码时刻在变。每次 commit 后,索引要么全量重建(成本高),要么容忍过期数据(质量差),要么做增量同步(边界 case 极多)。怎么选都不舒服。

3.4 冷启动延迟
百万行代码库建索引需要数分钟。用户打开工具得先等进度条?这与 Claude Code"开箱即用"的产品哲学直接冲突。

3.5 黑盒不可调试
Top-K 召回结果无法解释——为什么是这 5 个而不是那 5 个?出问题时,是召回错了还是模型理解错了?排查链路极其痛苦。
小结:RAG 适合"静态、自然语言、模糊匹配"场景。代码恰好是"动态、结构化、需要精确"的反面。
4. Claude Code 的方案:让 LLM 像程序员一样自己找
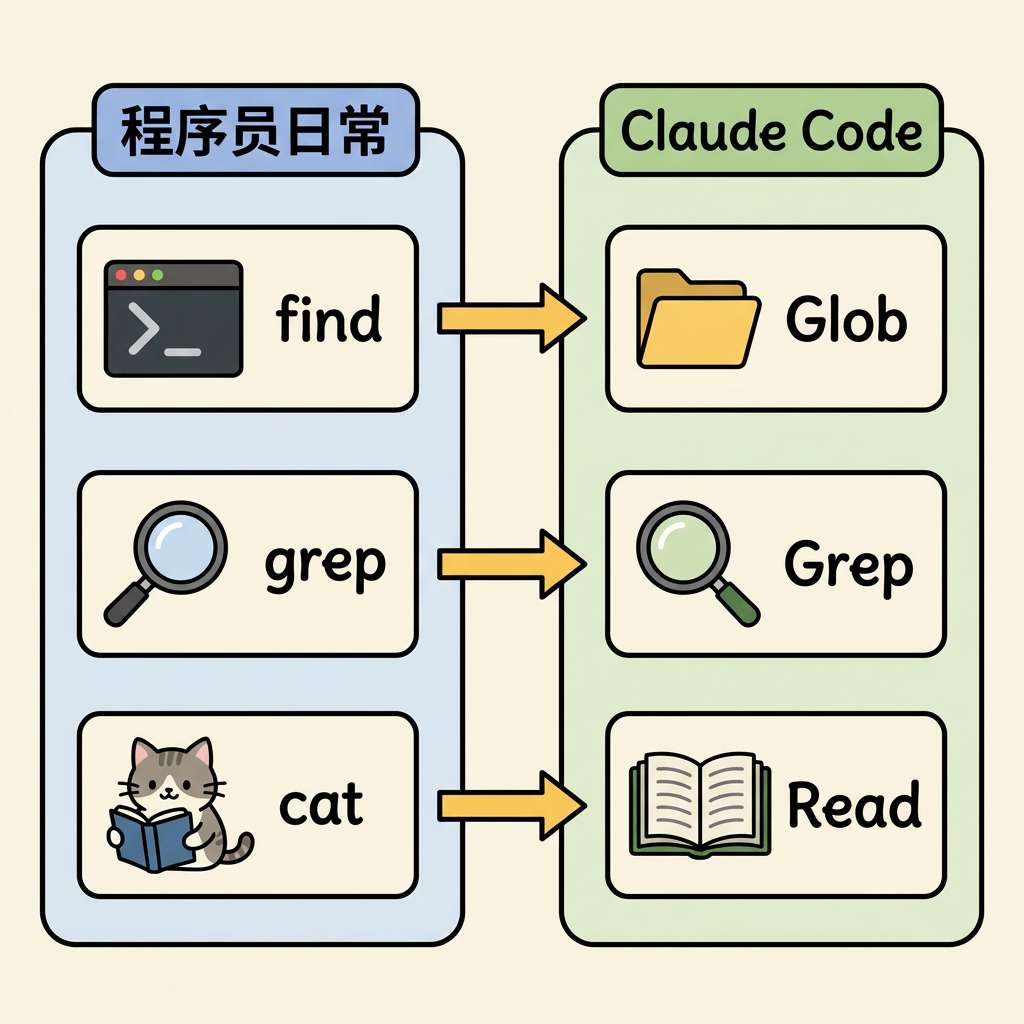
回想程序员接手陌生项目的工作流:ls 看结构 → grep -r 搜关键字 → cat 看具体文件 → 循环,直到找到目标。
没有人会先给项目建向量索引。
Claude Code 的设计哲学与此完全一致:不预处理,不建库,让模型实时查找。 三个核心工具:
| 工具 | 功能 | 类比 |
|---|---|---|
| Glob | 按文件名 pattern 匹配 | find |
| Grep | 按内容正则搜索 | grep -r |
| Read | 按需读取文件内容 | cat + 编辑器跳转 |
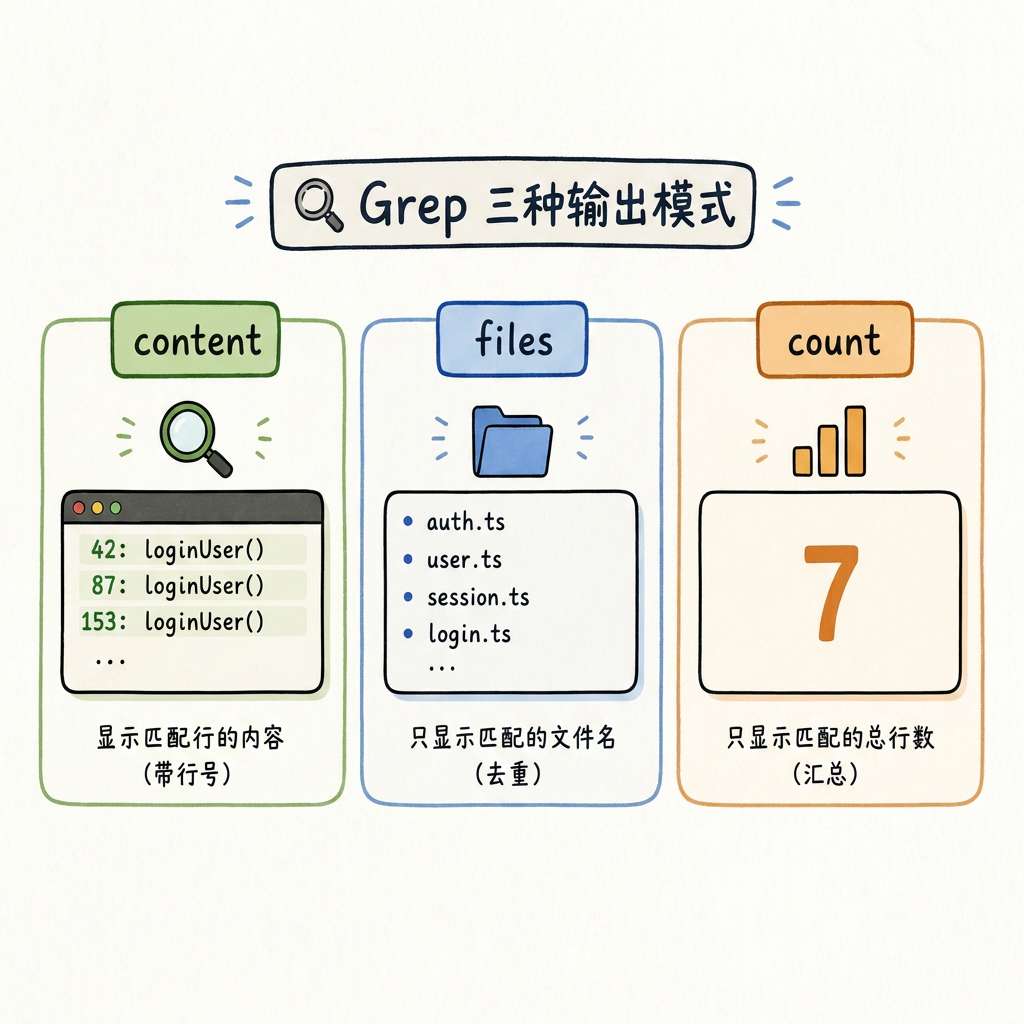
4.1 Grep:不只是 ripgrep 的封装
为什么不让模型直接用 Bash 跑 grep?三层考量:
- 安全:独立工具 = 独立权限闸门,避免 Bash 万能通道的风险
- 格式可控:支持
content(匹配行)、files_with_matches(仅文件名)、count(仅计数)三种输出粒度,按需选择节省 token - 性能:底层是 Rust 实现的 ripgrep,多线程 + 自动忽略 .gitignore 规则
源码 src/tools/GrepTool/prompt.ts 中的关键约束:
ALWAYS use Grep for search tasks. NEVER invoke `grep` or `rg` as a Bash command.
Anthropic 用 system prompt 硬性约束模型走专用工具,杜绝 Bash 旁路。
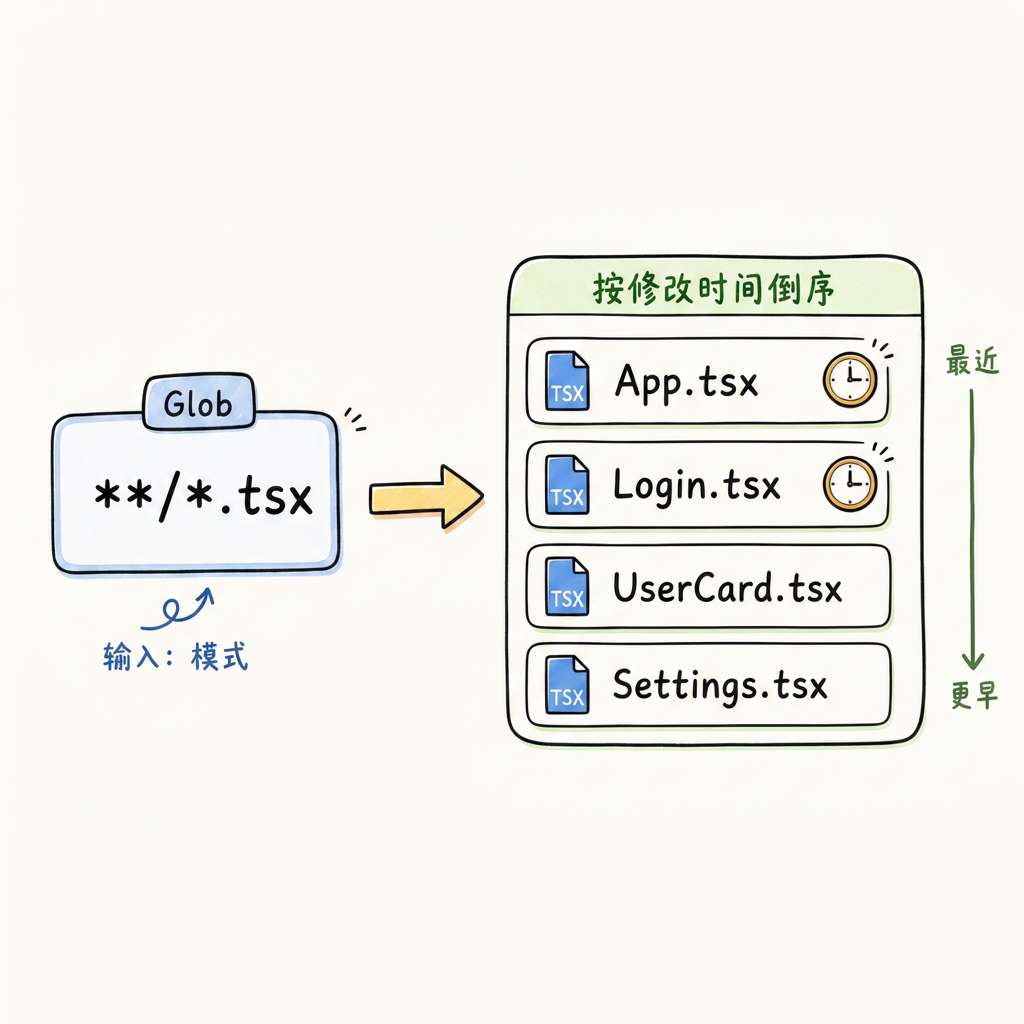
4.2 Glob:最近修改优先的文件发现
按文件名 pattern 匹配(如 **/*.tsx),结果按修改时间倒序排列——最近改过的文件最可能与当前任务相关。硬上限 100 文件,防止输出爆炸。
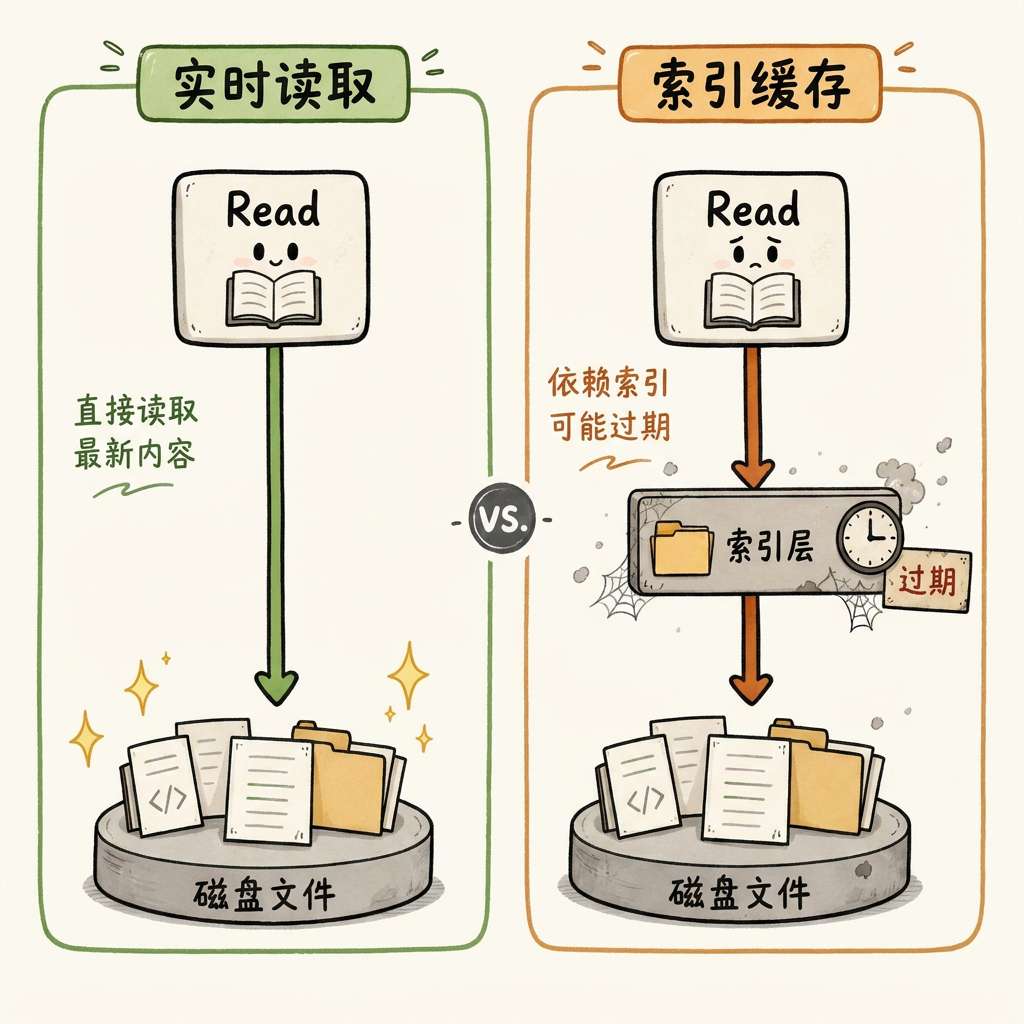
4.3 Read:按需分段,实时最新
默认只读 2000 行,支持 offset + limit 精确分段。关键特性:每次直接读磁盘最新版本,无缓存、无索引层。文件刚改完,下一次 Read 立即可见——实时性的根本保障。
源码 src/tools/FileReadTool/FileReadTool.ts:
When you already know which part of the file you need, only read that part.
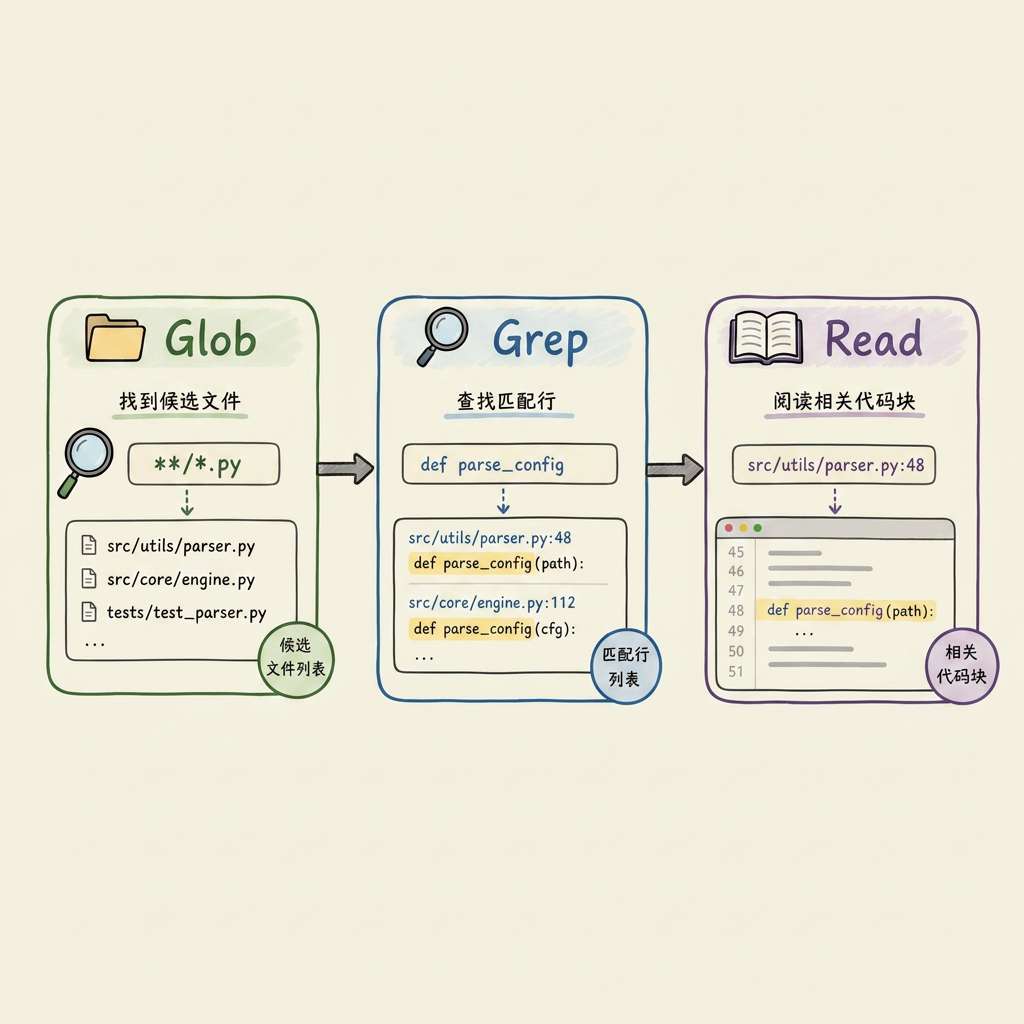
4.4 组合检索示例
任务:「这个项目登录功能在哪实现的?」
- Glob:
**/*login*.{ts,tsx,js}→ 5 个候选文件 - Grep:
passport|auth|login→ 定位命中行 - Read:读取具体实现段
每一步都基于上一步的结果动态决策,而非一次性静态召回。
4.5 子 Agent:大型探索任务的上下文隔离
当探索范围超过 3 次查询时,主 Agent 会派出独立的 Explore 子 Agent:
- 拥有独立上下文,与主 Agent 完全隔离
- 只有只读工具(Grep/Glob/Read/Bash-readonly),不能编辑、不能嵌套派遣
- 完成后仅返回精简结论,所有中间搜索过程被"压缩"掉

这解决了大型探索任务的上下文污染问题:主 Agent 的注意力始终聚焦在核心任务上。

源码 src/tools/AgentTool/prompt.ts:
For simple, directed codebase searches use Grep/Glob/Read directly.
For broader codebase exploration and deep research, use the Agent tool
with subagent_type=Explore.
子 Agent 还支持并行派遣——同时调研多个模块,结果并发返回。
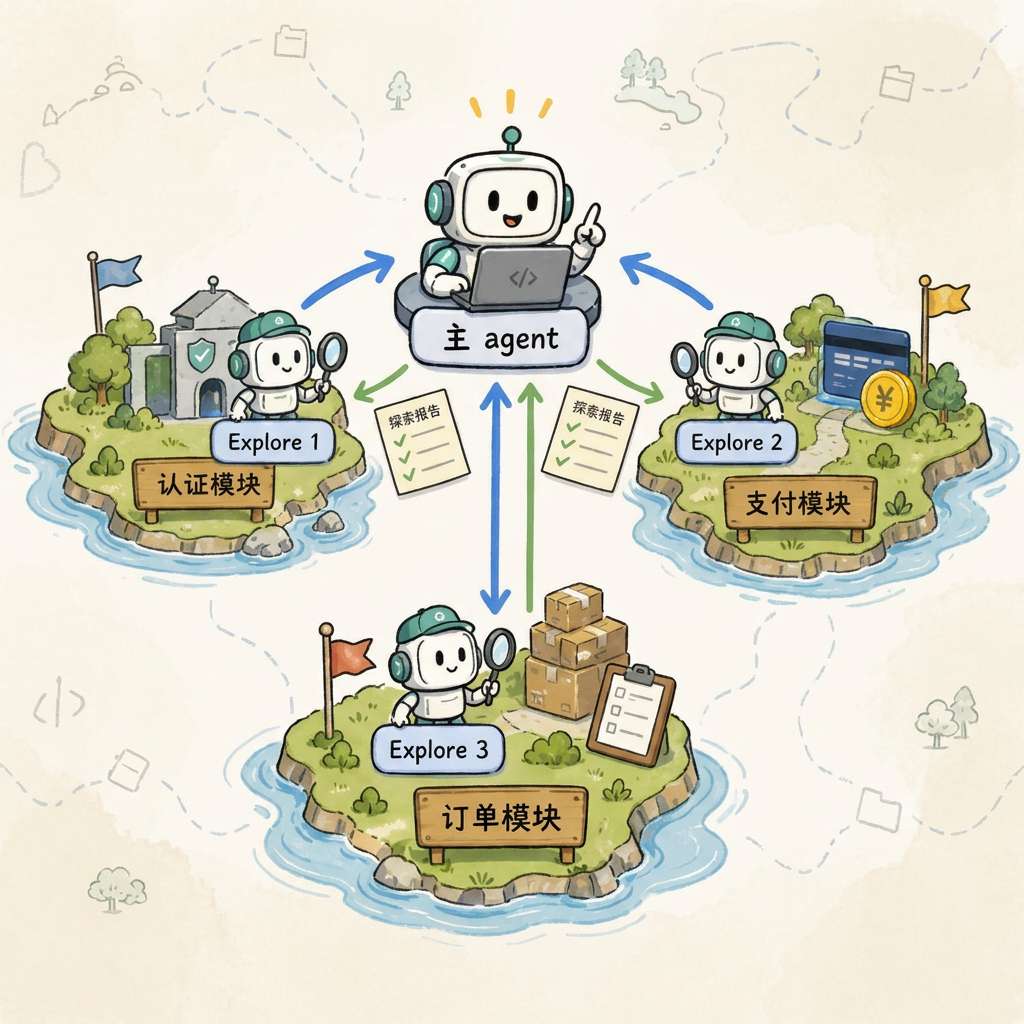
系统层次:
- 底层:Grep / Glob / Read — 简单定向检索
- 中层:Explore 子 Agent — 开放式探索 + 上下文隔离
- 上层:主 Agent — 任务编排与最终决策
5. 核心引擎:LLM 驱动的多轮迭代循环
RAG 是单次召回:提问 → Top-K → 生成。一锤子买卖,召回错了只能将错就错。
Claude Code 是多轮探索:提问 → Grep → 看结果 → 调整方向 → Read → 再判断 → 循环,直到模型自己确认"搞定了"。

src/query.ts 核心循环:
while (true) {
const response = await callLLM(messages)
if (没有 tool_use) break
for (const toolUse of response.toolUses) {
const result = await executeTool(toolUse)
messages.push(result)
}
}
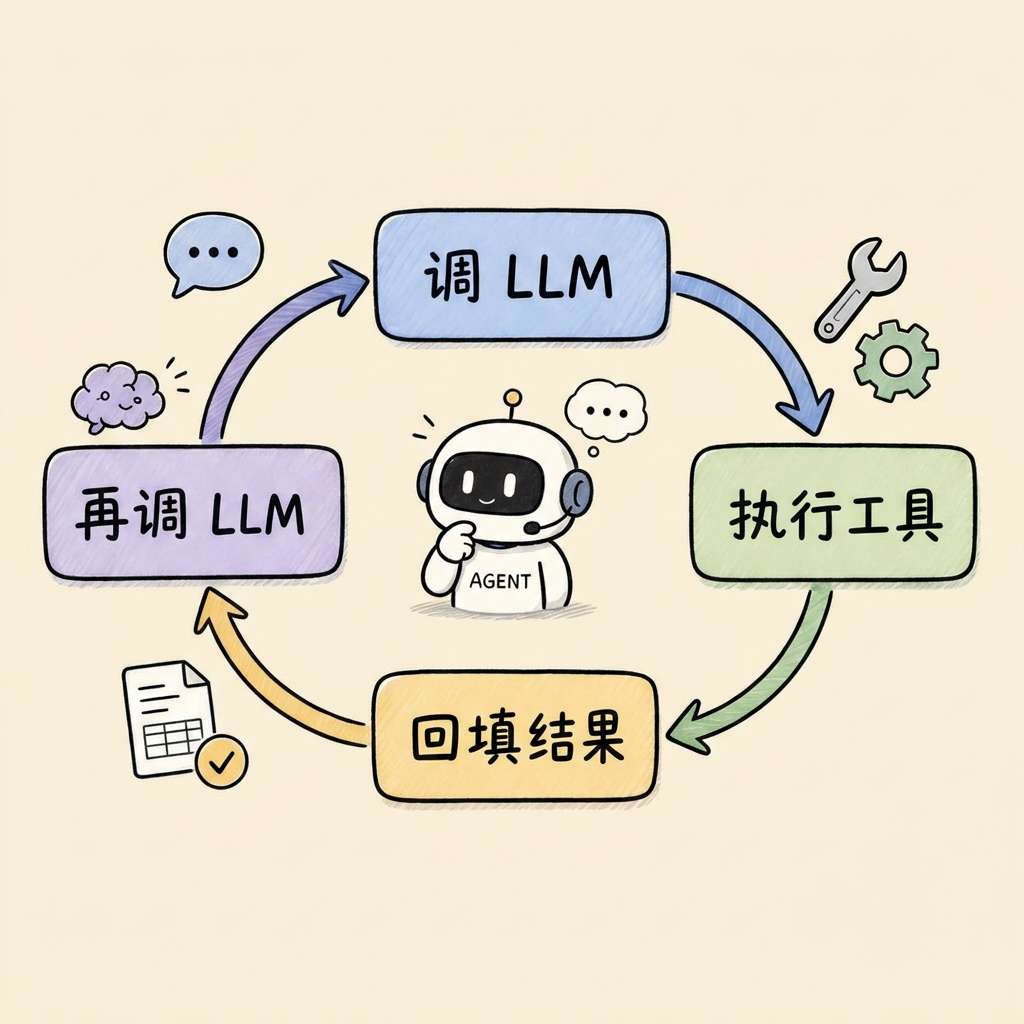
这个循环赋予了模型"走一步看一步"的能力:
- Grep 结果为空?换关键字重搜
- Read 出来的逻辑不对?顺着引用链继续追踪
- 发现跨文件依赖?跟过去看
grep 本身平平无奇,但 “让 LLM 自主决定每轮 grep 什么” 就构成了一个强大的自适应检索系统。
6. 六大原因总结 + 哲学分歧
| 维度 | grep 方案 | RAG 方案 |
|---|---|---|
| 冷启动 | 毫秒级,开箱即用 | 分钟级索引构建 |
| 实时性 | 每次读磁盘最新版 | 索引滞后 |
| 精确性 | 确定性正则匹配 | 向量近似,易混淆 |
| Token 经济 | 按需读取 | 全量 embedding 成本 |
| 可解释性 | 全链路透明 | Top-K 黑盒 |
| 决策权 | LLM 自主多轮迭代 | 一次性召回 |

更深层的哲学分歧:
- RAG 派:LLM 不够强 → 用工程手段帮它准备好材料 → 本质是"替模型做决定"
- Claude Code 派:LLM 已经够强 → 给它工具、还它决策权 → 本质是"信任模型"
Anthropic 押注的是模型能力的持续增长。这是一个长期主义的架构选择。

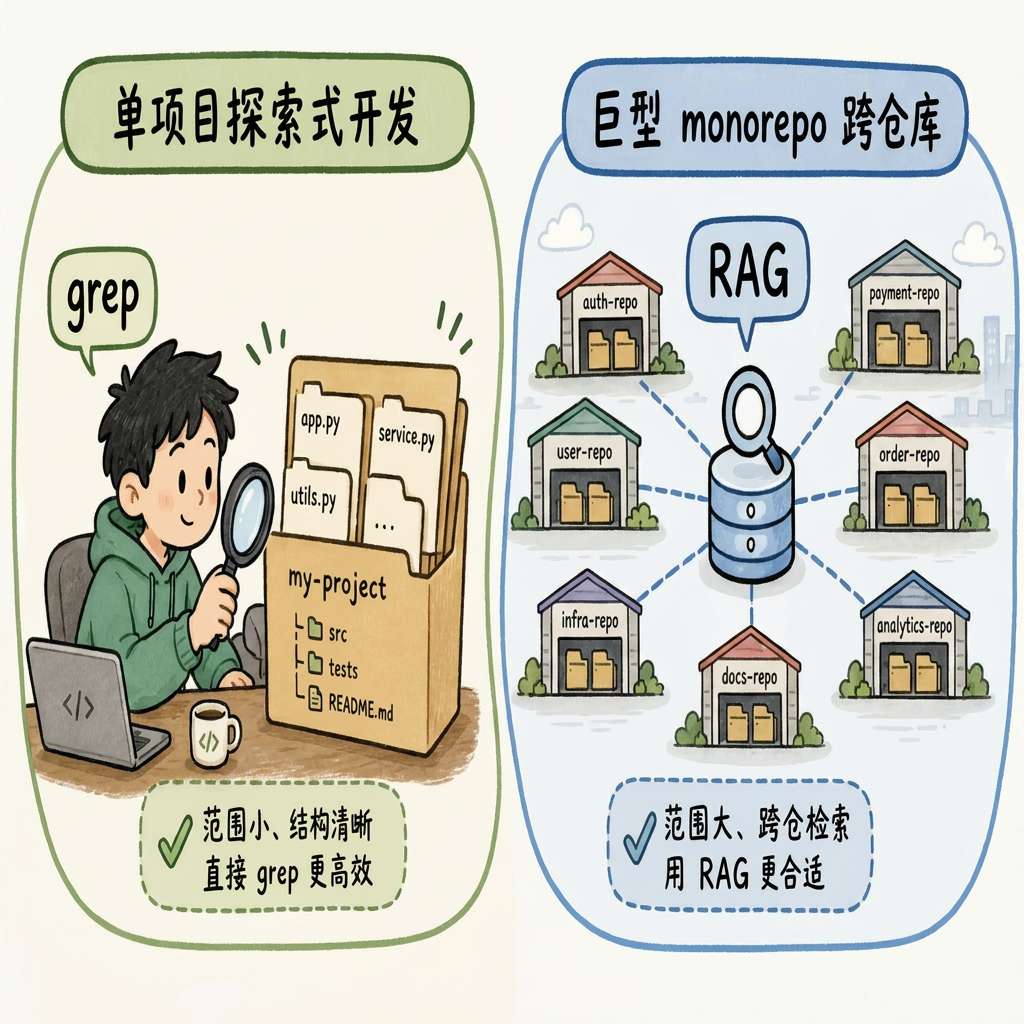
7. RAG 并非一无是处:各有战场
RAG 仍然适用于:
- 巨型代码库 / 跨仓库检索:千万行级别,grep 性能可能成瓶颈
- 纯语义查询:“找处理用户认证相关的代码"这类模糊描述,关键字搜索天然弱势
- 多源混合知识库:代码 + 文档 + Wiki 联合检索
Claude Code 方案最适合:单项目、探索式开发、需要精确性、要求实时性——恰好是绝大多数 AI 编程工具的主战场。
没有银弹,工具为场景服务。
结论:三句话回答面试题
- 代码场景下 RAG 有本质缺陷:切片破坏结构、向量近似不精确、索引滞后难维护。
- Claude Code 用 Grep + Glob + Read 三件套配合子 Agent 探索,将检索决策权交还 LLM,通过多轮迭代循环实现自适应精准定位。
- 底层是 Anthropic 的设计哲学:信任模型能力,不替模型做决定,押注 LLM 持续变强。
这道题的本质不是技术选型比较,而是对 Agent 设计哲学 的理解:
Agent 不是带工具的聊天机器人,而是能自主决策的执行体。工程师的职责是给它好工具,而不是替它思考。

如果未来 LLM 的上下文窗口达到 1 亿 token,整个代码库都能塞进去,grep 还有意义吗?RAG 还有意义吗?
这个问题,留给你思考!