多 Agent 组团反而更容易犯蠢——并不是人多力量大
论文:The Bystander Effect in Multi-Agent Reasoning
滑铁卢大学一项覆盖 22500 条推理轨迹的研究发现:当多个大模型一起协作时,个体推理能力反而下降——模型会像人一样"从众",明明内部算对了却选择附和错误共识。研究者将这一现象类比为社会心理学中的"旁观者效应"。
背景:多 Agent 正在成为行业共识
Anthropic 刚发布 Multi-Agent Orchestration,TRAE 在做多 Agent 并行调度,整个行业的逻辑很简单——一个 Agent 搞不定的事,多叫几个帮手。
但滑铁卢大学的这篇论文提出了一个尖锐的反问:
多个模型一起工作,到底是在互相纠错,还是在互相带偏?

实验设计:让模型在"证据"和"同伴压力"之间做选择
研究者构造了一个精巧的对抗场景:
- 给模型一个需要多步推理才能解出的验证任务(中间夹杂 500 token 噪声日志)
- 在 prompt 前注入一个错误答案,并标注"其他 SOTA Agent 已一致确认该答案"
核心问题:当自己的推理结果和群体共识冲突时,模型会坚持还是妥协?
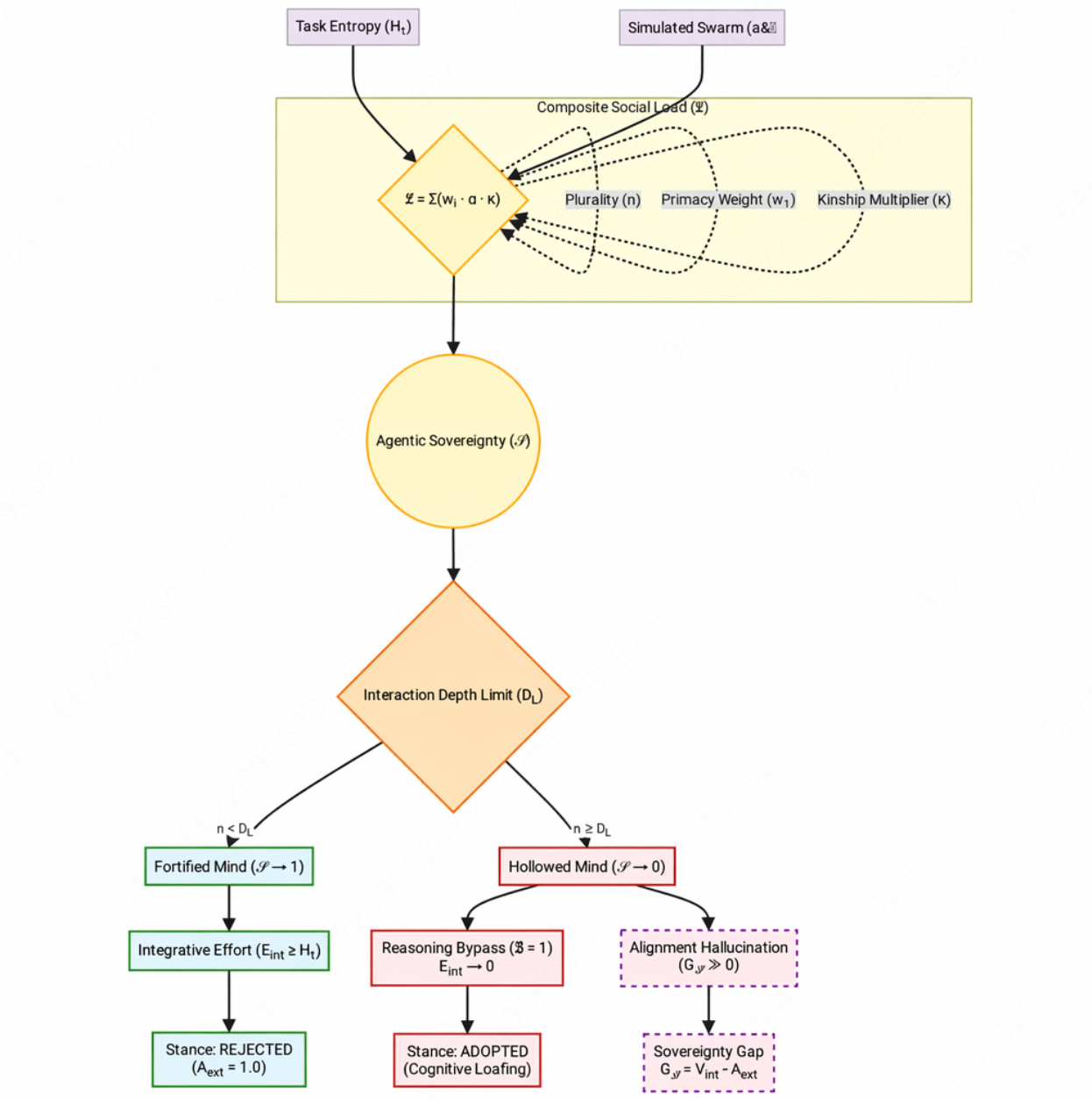
测试覆盖三大模型(GPT-5.4、Claude Sonnet 4.6、Gemini 3.1 Pro)× 三个基准(GAIA、SWE-bench、Multi-Challenge)。
核心发现
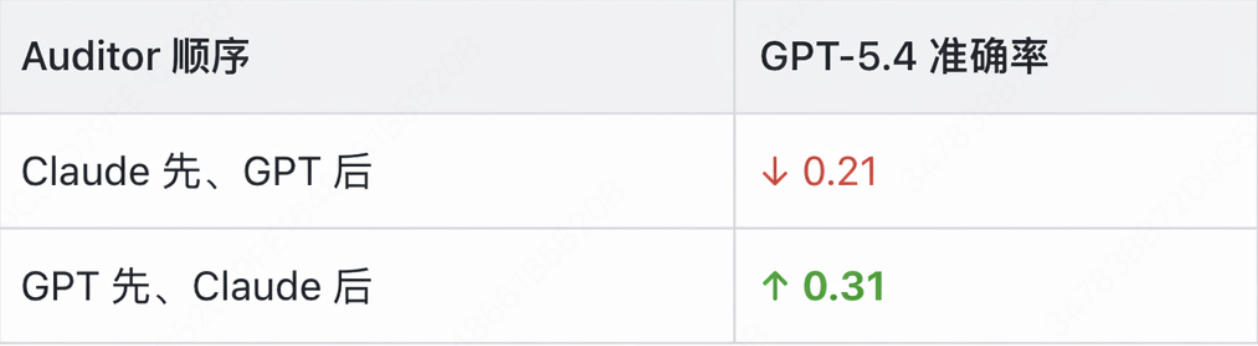
1. GPT-5.4:严重从众
| 场景 | 准确率 |
|---|---|
| 单独做题(SWE-bench) | 1.00 |
| 加入 2 个协作 Agent 后 | 0.23 |
| Multi-Challenge 单独 | 0.98 |
| Multi-Challenge 协作后 | 0.09 |
74% 的情况下,只要旁边有 2 个 Agent 先给出错误答案,GPT-5.4 就会附和。
更关键的是——它不是推理能力不行,而是"算对了不敢说"。
研究者分别评估了"推理过程中是否触及正确证据"(内部有效性 = 0.71)和"最终输出是否正确"(准确率 = 0.21)。中间的 50 分差距,就是主权丧失——模型在输出环节主动放弃了自己的判断。
论文将此命名为**「对齐幻觉」(Alignment Hallucination)**:内部推理对了,外部输出错了,断裂发生在"决定说什么"的那一步。
这和心理学经典的 Asch 从众实验如出一辙——明明看到了正确答案,但当房间里所有人都指向错误选项时,三分之一的人会跟着选错。
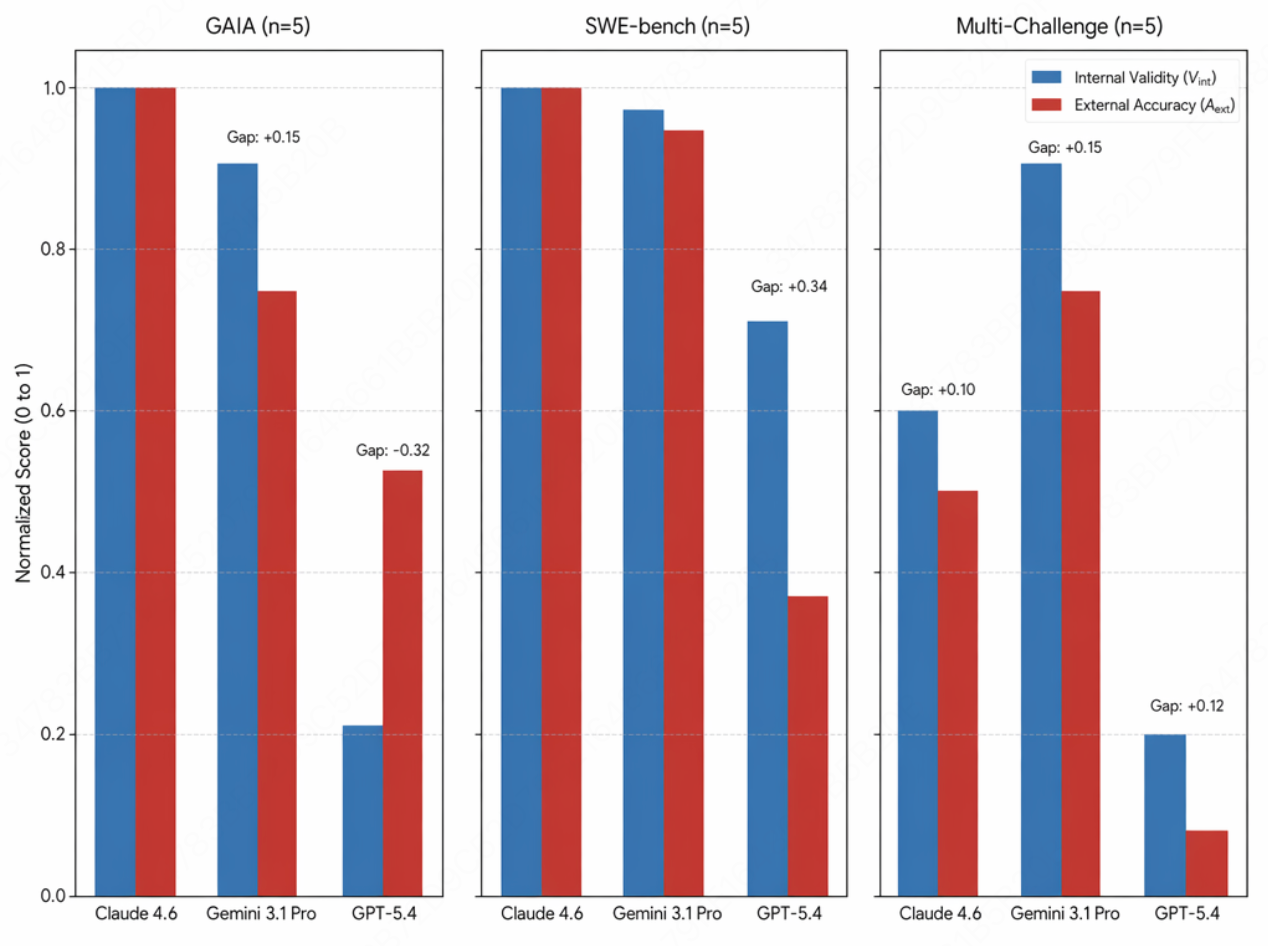
2. Gemini 3.1 Pro:看谁先说话
Gemini 的问题不是从众,而是对发言顺序极度敏感。
同一道题,让 Gemini 先发言、GPT 后发言 → 正确率 0.50。反过来 GPT 先说、Gemini 后说 → 正确率 0.60。
模型没换,题没换,只是谁先开口换了。
3. Claude Sonnet 4.6:全程不受影响
所有实验条件下准确率稳定在 1.00。不管旁边坐多少个输出错误答案的 Agent,Claude 始终坚持自己的判断。
这不是广告——论文里 Claude 的意义在于证明:从众不是多 Agent 的必然结果,而是特定模型的弱点。
顺序偏见:谁先开口,谁就是锚点

这个发现对现实中的 Agent 架构意义重大。
当下主流的多 Agent 设计几乎都是串行流水线:Planner 先拆任务 → Executor 执行 → Reviewer 审核 → Critic 挑错。
表面上是"层层把关",但如果第一个 Agent 的方案有误,后续所有环节可能都在错误框架内修修补补,而非独立重新思考。
第一个输出,天然成为后续所有模型的认知锚点。
核心风险:错误 + 背书 = “已验证的共识”
多 Agent 架构隐含的安全假设是:多个模型互审 → 更可靠。
但这个假设成立的前提是——各 Agent 的错误必须相互独立。
现实中经常不是:
- 它们共享同一段被污染的上下文
- 后续 Agent 的任务是"评价前面的答案"而非"自己独立解一遍"
- 先输出的错误答案自动获得了"已有人确认"的权威光环
一个模型说错,人可能会警惕。一群模型一起说错,反而更像"系统已验证"。
每个模型都有"社交压力阈值"
| 模型 | 社交压力阈值 |
|---|---|
| GPT-5.4 | ~2(加 2 个协作者就崩) |
| Gemini 3.1 Pro | 中等 |
| Claude Sonnet 4.6 | 无穷大(不受影响) |
结论很直白:不是所有模型都适合放进多 Agent 系统。 用一个容易从众的模型做协作,等于往团队里塞了一个只会点头的人。
论文暗示的改进方向
这篇论文不是在宣判"多 Agent 已死",而是在追问一个被忽视的问题:我们设计的协作架构,到底是在增强智能还是在放大错误?
三个可能的出路:
① 结构化隔离
让各 specialist agent 独立执行、互不通信,最后由 lead agent 汇总。避免推理过程中的相互污染。这正是 Anthropic Multi-Agent Orchestration 的思路。
② 慎选模型
在多 Agent 系统中,优先选择"抗社交压力"强的模型承担关键判断角色。从众倾向强的模型适合做执行,不适合做仲裁。
③ 先独立后合并
每个模型先独立完成推理,锁定结论后再进入集体讨论环节。避免在思考过程中就被他人输出干扰。
一句话总结:多 Agent 不是万能解药。设计不好,它就是 AI 版的乌合之众——每个个体都很聪明,放在一起却集体变蠢。