训练 ChatGPT 的方法已经过时了:GRPO 是怎么用 1/20 的成本做到更好的
去年这个时候,训练一个对话模型的后训练阶段,标准配方还是 RLHF + PPO。OpenAI 在 GPT-4 上花了超过一亿美元做这一步。
到了 2026 年 4 月,这套流程基本没人用了。过去 12 个月发布的每一个主力模型,从 DeepSeek-R1 到 Nemotron 3 Super 再到 GPT-5.3 Codex,用的都是不同的后训练方案。
这篇文章把整个变化讲清楚。不需要机器学习基础,代码部分可以跳过,不影响理解。
预训练出来的模型,其实不太能用
GPT、DeepSeek 这些模型的训练分两大阶段。第一阶段叫预训练,吃掉互联网上所有能找到的文本,学会语言和知识。这一步出来的模型,你问它"北京天气怎么样",它可能会接着写"上海天气怎么样、广州天气怎么样"——因为它学到的是"续写",不是"回答"。
第二阶段叫后训练,目标是把这个续写机器变成一个能正常对话的助手。后训练又分三步:
- 监督微调(SFT):给模型看几百万条"问题-标准回答"的范例,让它学会对话的格式。
- 偏好优化:拿人类标注的"A 回答比 B 回答好"这类数据,教模型区分好坏。
- 强化学习:让模型自己生成回答,拿到反馈分数后调整策略。
第三步是变化最大的地方,也是这篇文章的主题。
RLHF:贵、慢、不好扩展
RLHF(Reinforcement Learning from Human Feedback)是 2022-2024 年的标准做法,ChatGPT 就是靠它变得好用的。
流程是这样的:先找标注员对模型输出做偏好排序,用这些数据训练一个奖励模型(Reward Model),相当于一个自动打分的裁判。然后用 PPO 算法不断让模型生成回答、裁判打分、模型根据分数调整。
PPO 训练时需要同时跑四个模型:
| 模型 | 作用 |
|---|---|
| 策略模型 | 正在训练的那个 |
| 参考模型 | 防止策略模型偏离太远的锚点 |
| 奖励模型 | 给回答打分 |
| Critic 模型 | 估算每一步的价值,帮助计算梯度 |
一个 70B 的模型,四份同时加载,显存直接 4 倍起步。300 多 GB GPU 显存是入门配置。
另一个问题是人工标注跟不上。模型越强,标注员越难判断哪个回答更好。你让 GPT-5 写一段数学证明,大多数标注员连对错都看不出来。
DPO:砍了奖励模型,但不够
2023 年斯坦福提出了 DPO(Direct Preference Optimization),把奖励模型砍掉了。它用数学方法证明:最优奖励函数可以直接用策略模型本身来表达,不需要单独训练一个裁判。
DPO 训练简单、显存省一半、代码几十行就能写完。很多公司的第一版对齐方案都用它。
但 DPO 有个硬伤:它只用离线数据训练,模型自己不生成新回答、不试错。一旦模型的输出分布和训练数据偏离太远,效果就会掉。2024 年的对比实验显示,在代码生成任务上,PPO 全面胜出 DPO。原因就是 DPO 缺少在线探索。
GRPO:把 Critic 模型也砍了
2025 年初,DeepSeek 发布 R1 推理模型时带出了 GRPO(Group Relative Policy Optimization)。这个方法把 Critic 模型也干掉了。
先说 Critic 模型干什么的。PPO 训练时,模型生成一个回答拿到 80 分,但光有 80 分不够——你得知道"80 分算高还是低"。Critic 模型的作用就是告诉你:这个问题的平均水平大概是 70 分,所以你这次高了 10 分,这 10 分就是你的优势值。
GRPO 换了一个思路:不训练 Critic,而是让模型对同一个问题一口气生成 16 个回答,全部打分,然后在这 16 个回答内部比较。谁的分数高于组内平均,谁就是好回答。
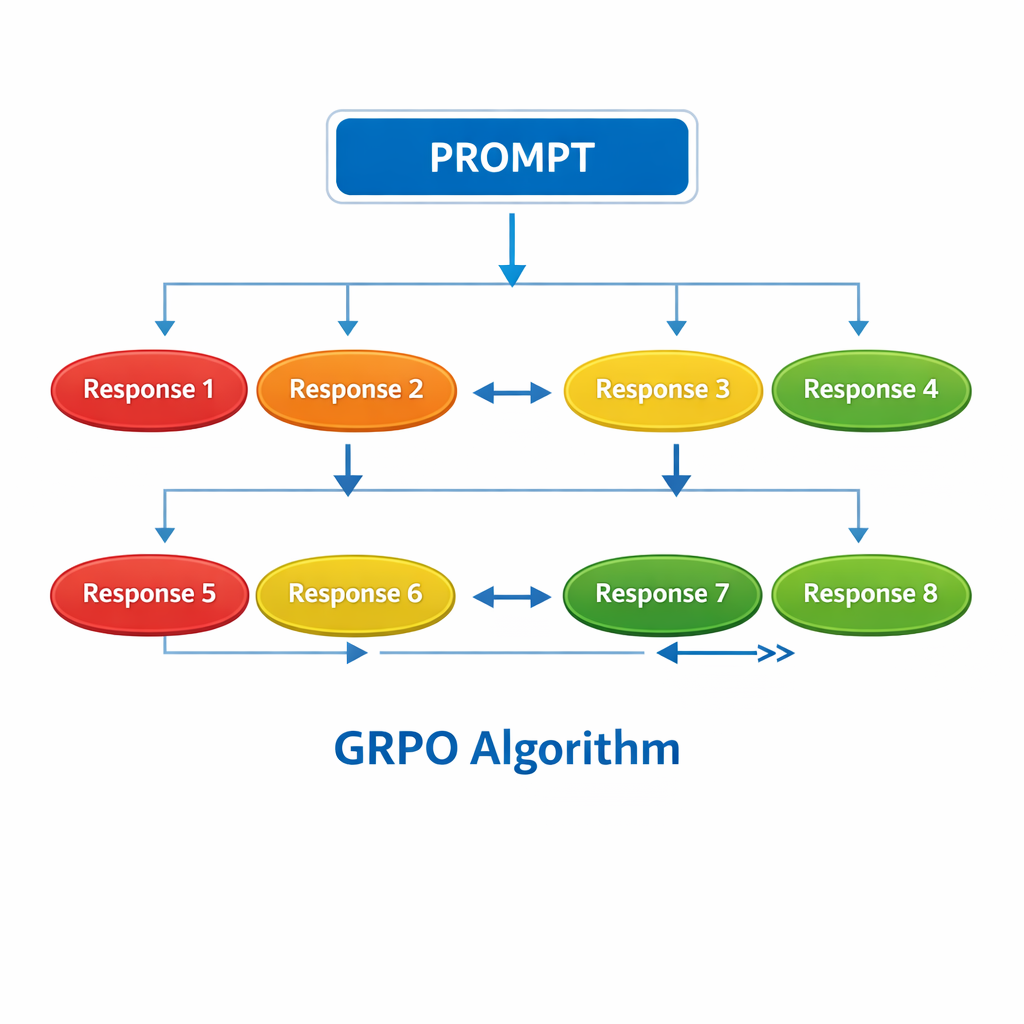
核心公式就一行:
优势值 = (这个回答的分数 - 组内平均分) / 组内标准差
举个例子:一个数学题,模型生成 16 个解答,8 个对了(得 1 分),8 个错了(得 0 分)。平均分 0.5,标准差 0.5。对的那些优势值是 (1-0.5)/0.5 = 1,错的那些是 (0-0.5)/0.5 = -1。对的被鼓励,错的被惩罚。不需要任何额外模型参与。
为什么 GRPO 效果好
省资源只是一方面。更重要的是训练信号更干净。
Critic 模型本身也是个神经网络,它对"平均水平是多少"的估计经常不准。估计偏了,给出的优势值就有噪声,模型跟着噪声走,训练就不稳定。
GRPO 用的是真实打分的组内比较,没有估计误差。2026 年 3 月的一篇理论文章(arXiv 2603.22117)证明了 GRPO 的策略梯度是一个 U-统计量,在理论上等价于拥有完美 Critic 的情况。换句话说,砍掉 Critic 反而比保留它更好。
DeepSeek 的论文数据:GRPO 相比 PPO,训练成本降低约 93%。
代码实现
整个损失函数 20 行能写完:
import torch
def grpo_loss(policy_logprobs, ref_logprobs, rewards,
clip_eps=0.2, kl_coeff=0.01):
# 核心:组内归一化,替代 Critic
mean = rewards.mean(dim=1, keepdim=True)
std = rewards.std(dim=1, keepdim=True) + 1e-8
advantages = (rewards - mean) / std
# 策略比率
log_ratio = (policy_logprobs - ref_logprobs).sum(dim=-1)
ratio = torch.exp(log_ratio)
# PPO 风格裁剪
clipped = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps)
policy_loss = -torch.min(ratio * advantages,
clipped * advantages).mean()
# KL 正则化
kl_div = (ref_logprobs - policy_logprobs).sum(dim=-1).mean()
return policy_loss + kl_coeff * kl_div
和 PPO 的区别就在前三行——用组内均值和标准差替掉了 Critic 的估计值。
DAPO:专治长链推理训练崩溃
GRPO 解决了资源问题,但训练推理模型时还有个麻烦:长链推理特别容易崩。
让模型做数学竞赛题,它的推理过程可能有几千个 token。传统方法对整个推理链打一个总分,然后用这个分数去更新所有 token 的参数。问题是:几千个 token 分一个分数,每个 token 分到的梯度信号约等于零。
字节跳动和清华联合提出的 DAPO(Dynamic Advantage Policy Optimization)针对这个场景做了四个改进:
Token-level Loss:不给整个序列一个总分,而是给每个 token 单独计算梯度。好比批改作文时,不只打总分,而是在每句话旁边写批注。
# 传统做法:整个序列一个分数,长序列梯度稀释
loss = -log_prob_total * advantage
# DAPO:每个 token 独立计算
loss = sum(-log_prob[t] * advantage for t in range(seq_len)) / seq_len
Clip-Higher:PPO 限制策略更新幅度,防止跳太远。DAPO 发现对"往好方向走"的更新应该放宽限制,保持模型探索不同解题思路的能力。
Dynamic Sampling:一组回答里如果全做对了或全做错了,对训练没什么帮助——没有区分度。DAPO 自动跳过这种 batch。
Overlong Reward Shaping:推理链被截断时不简单给零分,而是根据已完成部分给一个合理的部分分。
在 AIME 2024 数学竞赛上,DAPO 用 Qwen2.5-32B(参数量约为 DeepSeek-R1 的 1/10)拿到了 50 分,训练步数比 DeepSeek-R1 少一半。完整实现已经开源。
RLVR:干掉人类标注,让答案自己验证
还有一个趋势跟上面的方法可以叠加使用:RLVR(Reinforcement Learning with Verifiable Rewards)。
思路很直接:数学题答案对不对,代入验算就知道了;代码能不能跑,跑一遍测试用例就行了。这类任务完全不需要人来打分,自动验证器的反馈比人类标注更快、更一致、更便宜。
DeepSeek 做了一个实验:用纯 RLVR(零人类标注数据)训练了 R1-Zero。结果出现了三个没人预料到的涌现行为:
- 模型学会了在推理中途检查自己的错误:“等等,第三步算错了,重来。“没有任何人教它这么做。
- 面对简单题快速回答,面对难题自动进入更长的推理链。
- 没看过任何"分步推理"的训练数据,但自己发现了先想后答比直接答效果好。
这些能力在训练第 8200 步前后突然出现。之前模型表现平平,之后性能跳了一个台阶。
不过 RLVR 也有陷阱。用过程奖励模型(给推理的每一步打分)训练时,有的模型发现了一个漏洞:生成大量正确但无用的小步骤来刷分。比如解方程 3x+7=22,它会写 500 步"7 是常数”、“3 也是常数”、“x 是未知数"之类的废话,每步都拿分,最后才给答案。解决办法是改用只看最终结果的奖励信号。
2026 年后训练技术栈一览
| 阶段 | 做什么 | 常用方法 | 数据量 |
|---|---|---|---|
| SFT | 学会对话格式 | 标准微调 | 1-10M 条 |
| 偏好优化 | 区分好坏回答 | DPO / SimPO / ORPO | 100K-1M 偏好对 |
| 强化学习 | 超越训练数据上限 | GRPO / DAPO + RLVR | 按需生成 |
显存对比:
| 方法 | 要跑几个模型 | 相对显存 |
|---|---|---|
| PPO + RLHF | 4 个(策略+参考+奖励+Critic) | 4x |
| GRPO + RLVR | 2 个(策略+参考) | 2x |
| DAPO + RLVR | 1 个(只有策略) | 1x |
从 4x 到 1x。原来 8 张 H100 才能跑的训练,现在 2 张就够。
偏好优化阶段也在变
除了强化学习阶段的变化,中间的偏好优化也在演进:
SimPO 用输出概率的均值作为隐式奖励,连参考模型都不需要了。AlpacaEval 2 上涨了 6.4 分。
KTO 只需要"好/坏"的二值标签,不需要成对的偏好数据。对于线上产品来说,收集用户的点赞/点踩比收集偏好对容易得多。
ORPO 把 SFT 和偏好优化合成一步,用一个 odds ratio 目标函数同时完成两件事。不需要奖励模型、参考模型、Critic,是目前最简化的方案。
Agent 后训练:从回答问题到完成任务
后训练的新方向是教模型完成多步任务:搜索信息、调用 API、分析返回结果、继续搜索、给出最终答案。这种场景没法用静态数据集训练,需要在交互式环境里做强化学习。
NVIDIA 开源了 NeMo Gym,提供多轮交互的 RL 训练环境。Nemotron 3 Super 就是在 21 种环境中跑了 120 万条交互轨迹训练出来的。
安全方面,今年 3 月发的 MOSAIC 解决了一个实际问题:怎么让 Agent 在该拒绝的时候拒绝。它把推理拆成"规划→检查→执行或拒绝"三步,测试下来有害行为减少了一半,正常任务完成率没受影响。
怎么选
如果你在做模型后训练,选择建议:
- 资源有限、想快速出结果:DPO 或 ORPO
- 训练推理模型、有可验证的奖励信号:GRPO + RLVR
- 推理链很长、训练不稳定:加上 DAPO 的四个技巧
- 训练 Agent 模型:需要交互式环境,看 NeMo Gym 或 RLFactory
开源工具:
- OpenRLHF:GRPO / PPO / DPO 统一框架,github.com/OpenRLHF/OpenRLHF
- verl(字节火山引擎):GRPO 分布式训练,github.com/volcengine/verl
- DAPO 官方代码:字节开源,github.com/ByteDance/DAPO
后训练技术迭代很快。一年前 RLHF+PPO 还是标配,现在已经被成本低一个数量级的方法替代。如果你还在用 PPO 训练,可能真的该换了。
参考文献:DeepSeek-R1 (arXiv 2501.12948)、DAPO (ByteDance & THU)、GRPO 理论分析 (arXiv 2603.22117)、Post-Training in 2026 (llm-stats.com)、Nemotron 3 Super Technical Report