深入浅出:多功能 Copilot 智能助手如何借助 LLM 实现精准意图识别
1. Copilot中的意图识别
如果要搭建一个 Copilot 智能助手,比如支持 知识问答、数据分析、智能托管、AIGC 等众多场景或能力,那么最核心的就是基于LLM进行意图识别分发能力,意图识别的准确率直接决定了 Copilot 智能助手的能力上限。
针对丰富且复杂的 query,需要构建足够强的意图识别模型来准确理解 query 背后的意图和深层次的需求,并将其分发至相应的服务模块对 query 进行承接。对此,我们可以通过高质量的数据预处理与增强技术获得大批高质量数据,能够帮助模型学习丰富的语义特征,使其学会识别意图的语义边界,提升意图识别的准确性。
2. 垂域意图识别的挑战
领域封闭性:Copilot智能助手一般都是在特定的业务领域中进行搭建,比如“商家智能助手”,垂域意图范围集中且高度专业化,通用语义模型的泛化能力难以完全满足实际需求,有时意图数量高达几百个且每个都与业务属性密切相关,需要更深的行业语义理解。
语义边界模糊:多种意图之间具有高度相关性(或相似性),意图的语义边界不够清晰。
3. 数据驱动方法论
可以回顾一下,在日常的算法工作中,经常会遇到两类需求:
- 规则化:要求模型必须做什么,必须不能做什么。针对这种需求,简单且有效的方法是将规则写入 prompt,让模型遵循硬规则的指令,或者调用函数工具,处理成符合硬规则的结果。
- 表现力:要求模型提升某种表现力,但这种表现力较为复杂,难以被简单的规则所描述。例如意图识别就是一种表现力,哪些query应该被分配到哪些意图是难以被简单的硬规则所描述的。而实践证明针对这种表现力的需求,最佳实践是数据驱动。
数据驱动实际上是一种思维方式,它告诉我们大部分问题无法通过类似if-else的方法映射地去解决,而是需要 Case-Based Learning,让模型学习通过大量高质量样本学习到能力。这也是大模型和 ImageNet 共通的构建思路。
2006 年,计算机视觉研究仍然是一个缺乏资金,且很少收到外界关注的学科。许多研究人员专注于构建更好的算法。他们坚信,算法是计算机视觉的中心,如果把机器智能与生物智能做类比,那么算法就相当于机器的突触,或者说是大脑中错综复杂的神经回路。有什么比让这些回路变得更好、更快、更强大还要重要的呢? 但李飞飞并不这么认为。彼时,她刚刚获得加州理工大学的博士学位,在伊利诺伊大学厄巴纳-香槟分校担任助理教授的职位。在攻读博士期间,李飞飞意识到了这种研究思路的局限性:如果训练算法的数据不能很好地反映现实世界,那么即使是最好的算法也无法很好地完成工作。 李飞飞的想法是:构建一个能够完全反映真实世界的数据集。
因此,做好意图识别的第一步就是构建一个能够尽可能反映真实世界的意图语义的数据集,特别是各个意图语义的边界,来让模型准确区分意图。此外,这个数据集还需要支持快速的意图迭代节奏,能够保持意图准确的情况下,根据意图迭代点及时变化意图分布,刻画新的意图边界。
3.1 数据增强
通用LLM说在垂域的意图识别数据上的泛化性并不强,本质上是原因是样本不具有多样性,无法刻画意图的语义边界。
为了让模型掌握分类的语义边界,需要一批处于语义边界的 hard sample,即困难样本加入训练集。因此,可以从原有的少量样本(实际业务场景中通过人工标注的几百到上千条)出发,自动扩展出困难样本,并且保证这种自动扩展是低成本且鲁棒的(不会出现意图标签的变化),也就是数据增强。
| 方法 | 描述 | 增强比例 |
|---|---|---|
| 随机重复 | 分为词级的随机重复和字符级的随机重复。对于词级的随机重复,首先进行分词,随后随机挑选一个词进行重复;对于字符级的随机重复,随机挑选三个字符进行重复。 | 1:2 |
| 错别字替换 | 采用《A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check》的错别字字典,随机挑选三个字符进行错别字替换。 | 1:1 |
| 随机位置替换 | 随机选择邻近的两个字,对这两个字的顺序进行变换 | 1:1 |
| 同义改写 | 调用 GPT-4,编写 Prompt 提示大模型同义改写 | 1:3 |
| 同义扩写 | 调用 GPT-4,编写 Prompt 提示大模型同义扩写 | 1:3 |
| 多句融合 | 随机选择两个意图不同的query,调用 GPT-4,编写Prompt 提示大模型将两个标问改写为一个query,意图标签是2个意图 | 2:1 |
需要注意的是,为了保证增强样本的意图和原样本一致,可以人工总结一些关键业务实体列表(比如“服务竞争力”、“体验分”等),并在增强过程中避免对这些业务实体进行改变,从而保证关键语义没有被改变。然后经人工筛查验证,保证增强样本的意图一致率。
另外,为了保证一个 query 对应唯一的意图,并且避免模型对单个重复 query 的过拟合,需要对所有样本进行去重,保证每个 query 仅出现1次。
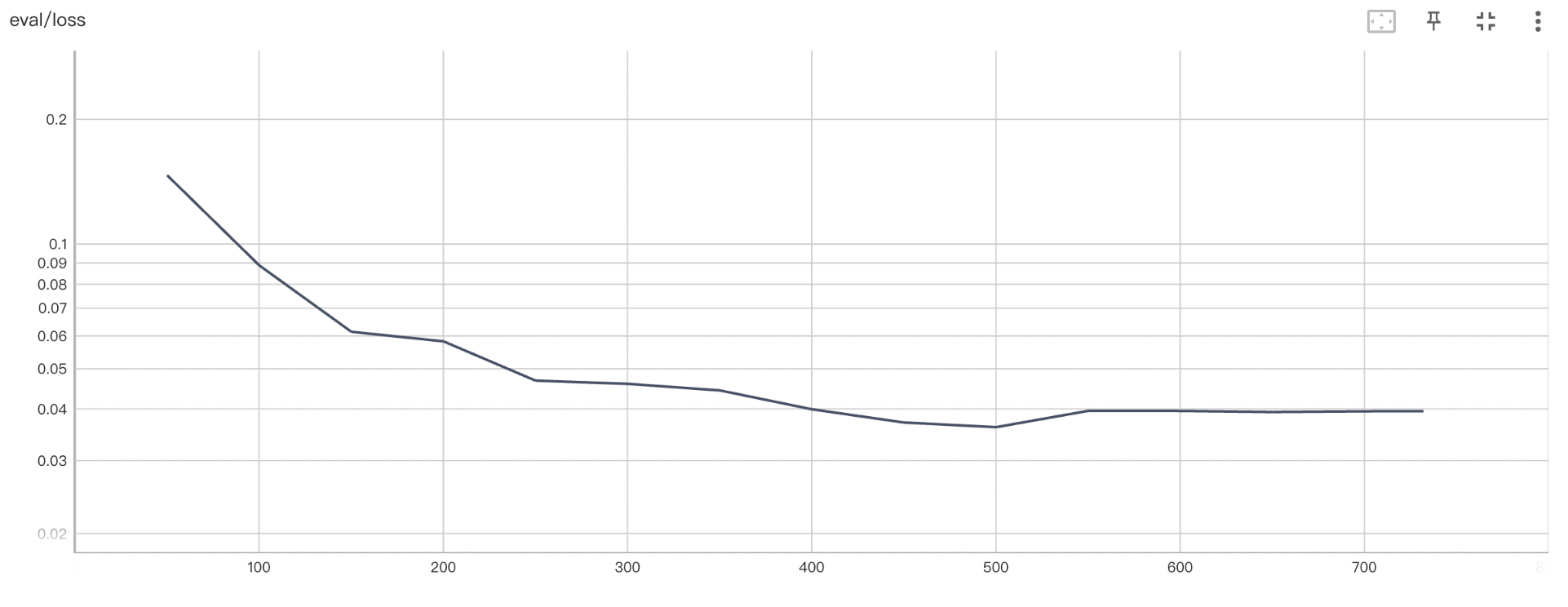
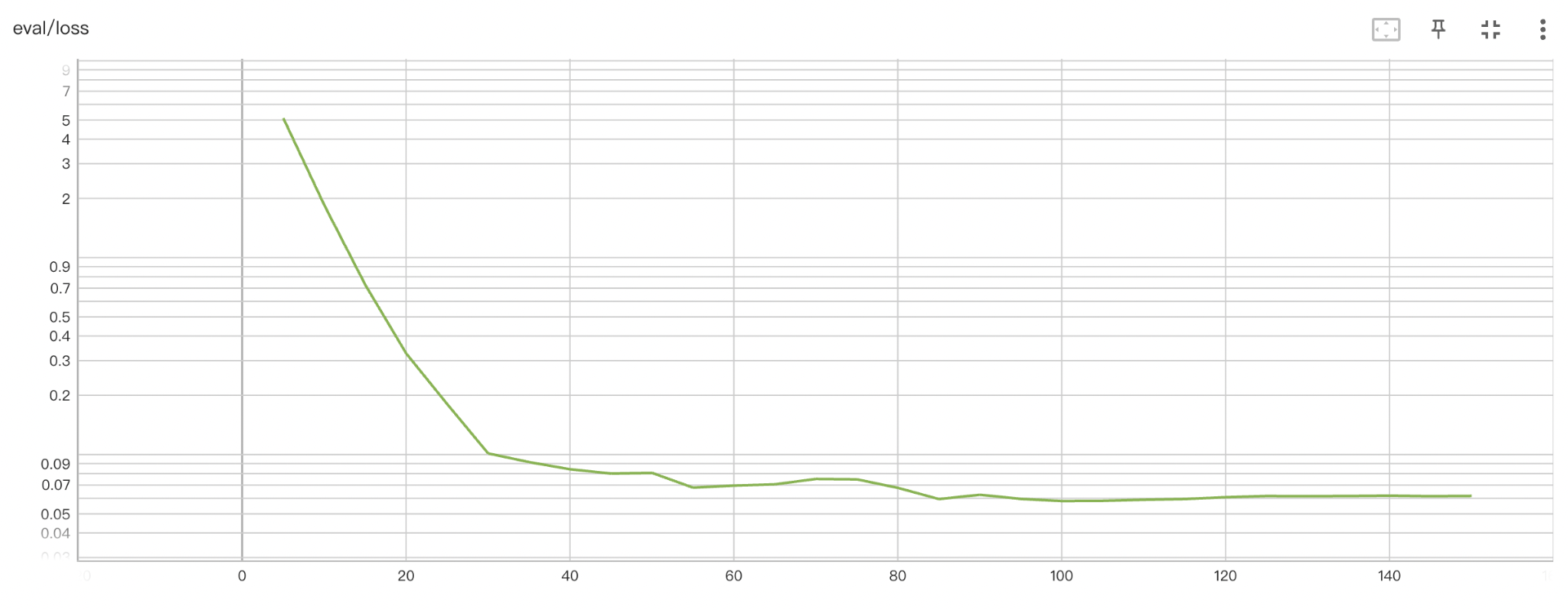
经过上述数据增强方法,样本数可从 几百上千扩展至几万,以下是扩展数据前后的训练Loss变化情况:
| 样本 | 训练 Loss | 验证 Loss |
|---|---|---|
| 增强样本 | 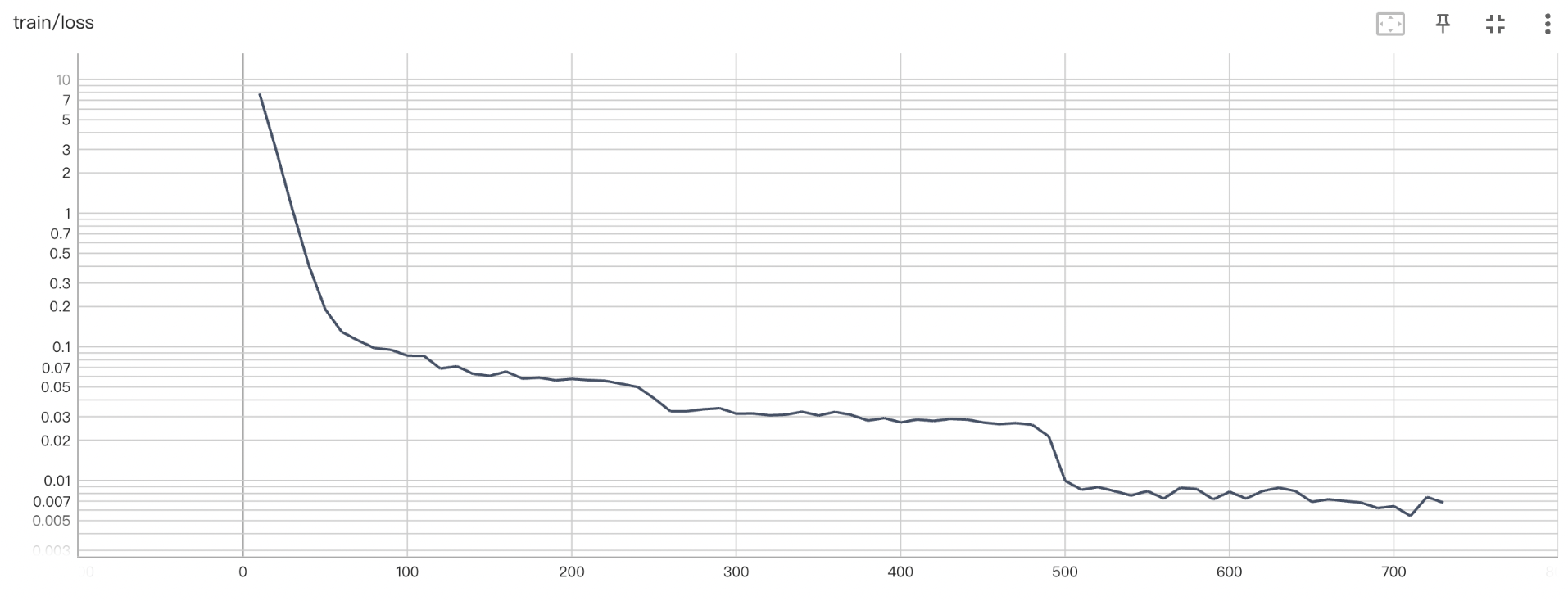 |
 |
| 未增强样本 | 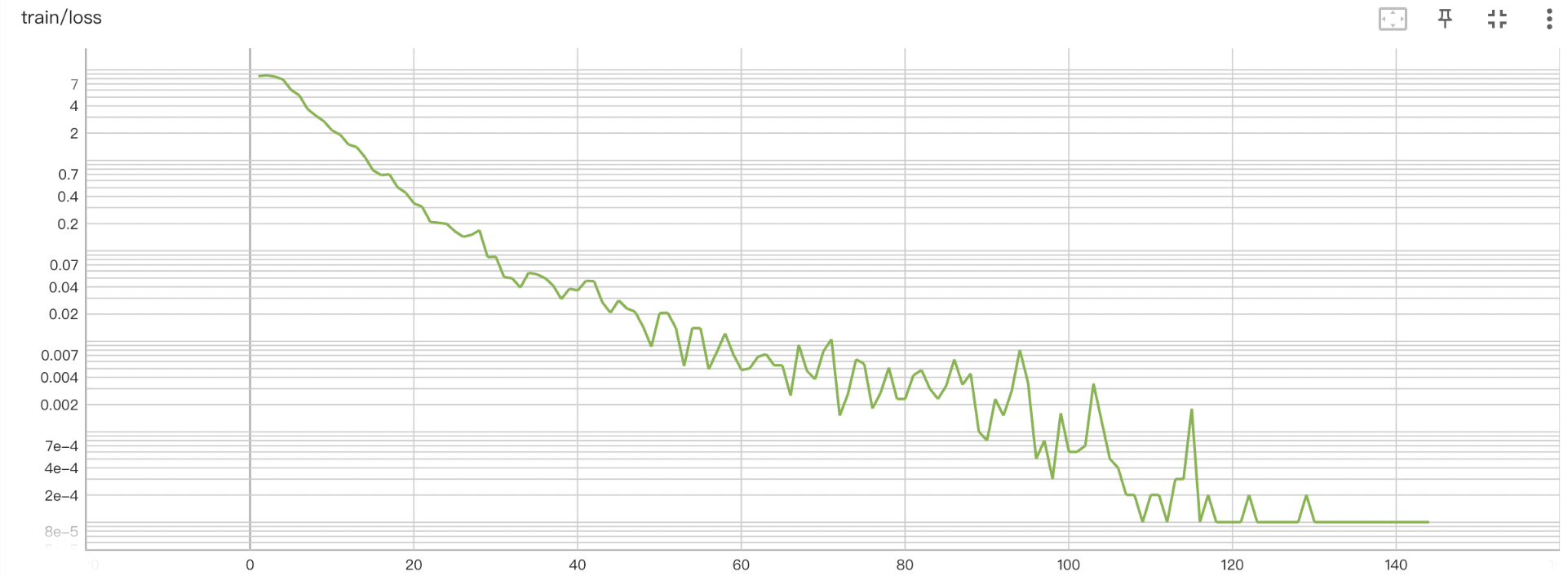 |
 |
可以发现:
- 未进行数据增强时,训练 loss 在前期快速收敛,然而,由于训练样本少,模型无法在验证集上有好的泛化效果,验证 loss 维持在一个较高的水平(0.057 以上)。而到了训练后期,模型呈现出过拟合的趋势,虽然训练 loss 趋近于 0,但验证 loss 逐步上升至 0.06 左右。
- 进行数据增强后,训练 loss 呈现出随着 epoch 阶梯式下降的趋势,这是因为训练集具备多样性,各个样本语义差异大,因此模型仅在“看”过整个训练集后才能对已“看”过的样本做出较好的推理。此外,由于训练集蕴含的规律模式较为丰富,模型在验证集上有较好的泛化性,最佳验证 loss 在 0.036 左右。
上述的结论在全链路评测中也得到了验证,经过数据增强后,模型在各个数据集上的意图准确率都得到了大幅提高。
3.2 负样本构造
在上述增强方法中,我们关注的是意图之间的语义边界,而忽略了 Copilot 的意图识别实际上是封闭域的,应当将意图的外部边界也纳入建模范围内,否则会导致过拟合现象。例如,在对数据集进行 badcase 分析时,你会发现在数据增强后,模型对于特定意图存在过拟合现象。这是因为某类意图的样本占比非常高(比如20%甚至更多),导致当输入一些简短 query 时(意图不明确时),模型会倾向于输出占比高的(20%)样本的意图。针对上述问题,可以专门构造一个“其他”意图,用来承接除业务意图之范围外的开放域 query。
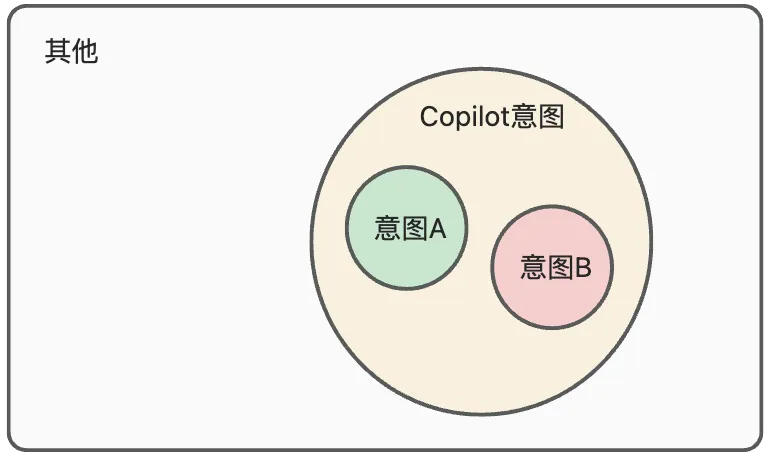
主要构造方法包括:
- 闲聊语料:调用 GPT-4,套取非业务意图的闲聊query,例如:你今天过得怎么样?
- 模糊短语:真实的用户query一般都很简短且部分query意图非常模糊,因此,为了针对性优化这些简短模糊的query,可以收集一些高频且表达模糊的短语,具体操作为 a. 采用 n-grams 进行分词得到短语,其中 n 取 1、2、3 b. 统计短语的出现频次比例和对应的意图个数 c. 筛选频次比例 >= 0.001(高频) 且 意图个数 >= 40(意图模糊)的短语作为样本,标注意图为“其他”
经过实践证明,通过上述的负样本优化,可以进一步地提高意图准确率。
3.3 标注提效
为了积累更多真实的样本,可以抽取线上真实的用户query进行批量的标注,主要方法是可以先通过 GPT-4 或者其它开源LLM等进行批量的标注,然后再对部分数据进行人工校验。

- 调用 GPT-4 进行意图标注,并挨个进行人工校验
- 调用 GPT-4 和其它多个开源LLM进行意图标注,通过投票方式将多个模型标注一致的样本直接进入样本库,并对模型标注不一致的样本(困难样本)进行人工校验。这个方案本质上和集成学习(Ensemble Learning)的原理差不多。
在标注的过程中,应该更加关注那些容易混淆的困难样本,因为这些困难样本就是在意图语义空间中处于边界的样本,对于意图准确率的提升至关重要,可以通过一种智能筛选的方法以快速筛选困难样本:可以统计各个 query 的语义距离,如果语义距离小于一个阈值(比较相似),但标注的意图不同,则可以认为这两个样本是难以区分的,加入到困难样本池中,最后进行人工重标注。
语义相似度的计算方法很多,例如编辑距离、LLM Embedding余弦距离、BGE余弦距离等,考虑到速度和便利性的话,建议使用编辑距离来计算语义相似度。
4. 训练优化
4.1 训练方式
为了找出高效的训练方法,使用不同的训练方式、不同的批大小、不同的学习率进行了大量实验,最终可以找到合适的训练方式和训练参数设置。
| 训练方式 | 批大小 | 学习率 | 耗时 | 验证 loss |
|---|---|---|---|---|
| LoRA | 32 | 1e-4 | 1 h | 0.0066 |
| 32 | 5e-4 | 1 h | 0.0044 | |
| 64 | 1e-5 | 1 h | 0.014 | |
| 64 | 2e-5 | 1 h | 0.0087 | |
| 64 | 5e-5 | 1 h | 0.0084 | |
| 64 | 1e-4 | 1 h | 0.0076 | |
| 64 | 5e-4 | 1 h | 0.0056 | |
| 64 | 1e-3 | 1 h | 0.0044 | |
| 128 | 5e-4 | 1 h | 0.0062 | |
| 128 | 1e-3 | 1 h | 0.0052 | |
| SFT | 4 | 5e-7 | 5 h | 0.0047 |
| 8 | 1e-7 | 3 h | 0.0056 | |
| 8 | 5e-7 | 3 h | 0.0058 | |
| 8 | 1e-6 | 3 h | 0.0044 | |
| 8 | 2e-6 | 3 h | 0.0044 | |
| 8 | 5e-6 | 3 h | 0.0042 | |
| 8 | 1e-5 | 3 h | 0.0050 | |
| 16 | 5e-7 | 2 h 20 mins | 0.0052 | |
| 16 | 5e-6 | 2 h 20 mins | 0.0029 | |
| 16 | 1e-5 | 2 h 20 mins | 0.0037 | |
| 32 | 5e-7 | 2 h 15 mins | 0.0044 | |
| 32 | 5e-6 | 2 h 15 mins | 0.0034 | |
| 32 | 1e-5 | 2 h 15 mins | 0.0034 | |
| 64 | 5e-7 | 2 h 4 mins | 0.0041 | |
| 64 | 5e-6 | 2 h 4 mins | 0.0045 | |
| 64 | 1e-5 | 2 h 4 mins | 0.0040 | |
| 128 | 5e-7 | 2 h 4 mins | 0.0042 |
- 相比于 LoRA,SFT 消耗的算力和时间较多,但是 SFT 在验证集上的 loss 更低,说明训练效果更好一些。这是因为意图识别所需的样本量较大(~10万),而 LoRA 只引入了低秩矩阵来调整模型,因此其对模型的修改是有限的,相比于全量微调在样本量较大的情况下会损失一些泛化能力。
- 当批大小提高时,整体的训练时间也在逐步减少,但是存在效益低减的情况。这是因为批大小的增大虽然能够减少整体所需算力,但是最终会受到 IO 和并行的影响,导致整体 GPU 利用率较低。
- 在学习率的选取上,大的学习率可能会导致 loss 不稳定,而小学习率可能会导致欠拟合。通过经验和实验确定,全参微调的学习率应设定在 5e-6 至 1e-5 之间,而LoRA的学习率应设定在 5e-4 左右。
4.2 基座选择
为了验证不同的大模型基座对下游意图识别任务的影响,可以对不同尺寸的大模型基座进行实验
| 模型 | 验证 Loss |
|---|---|
| Qwen2.5-7B-Instruct | 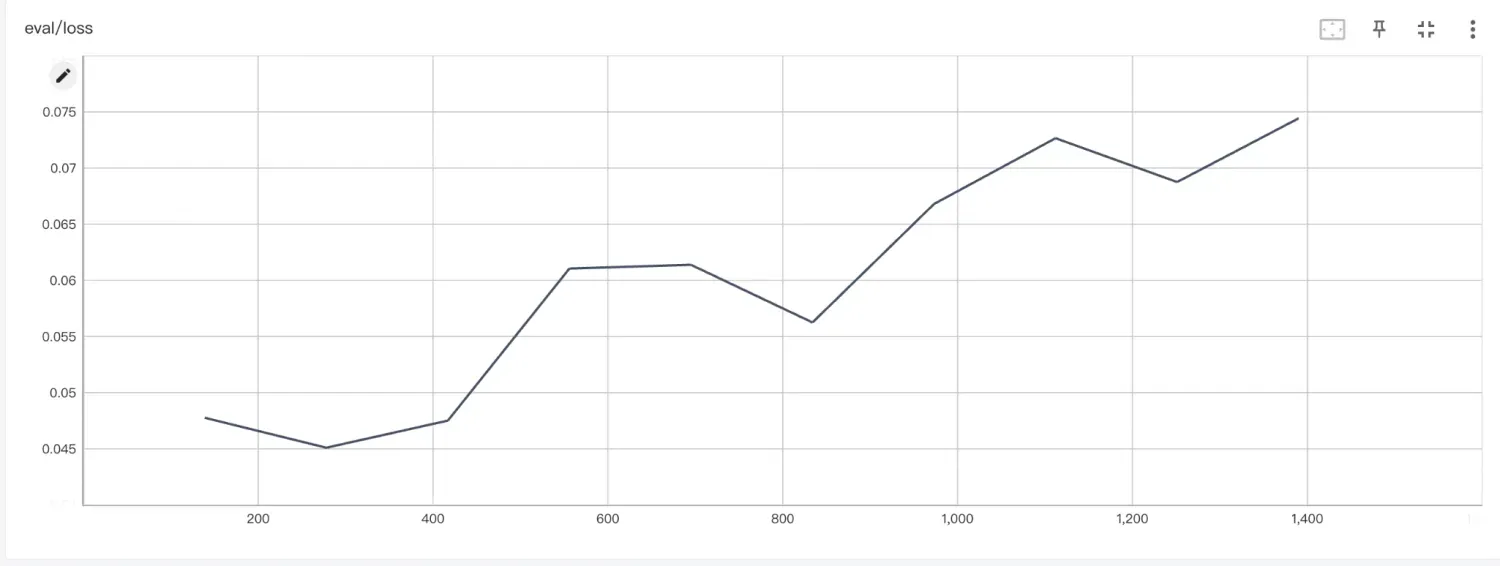 |
| Qwen2.5-14B-Instruct | 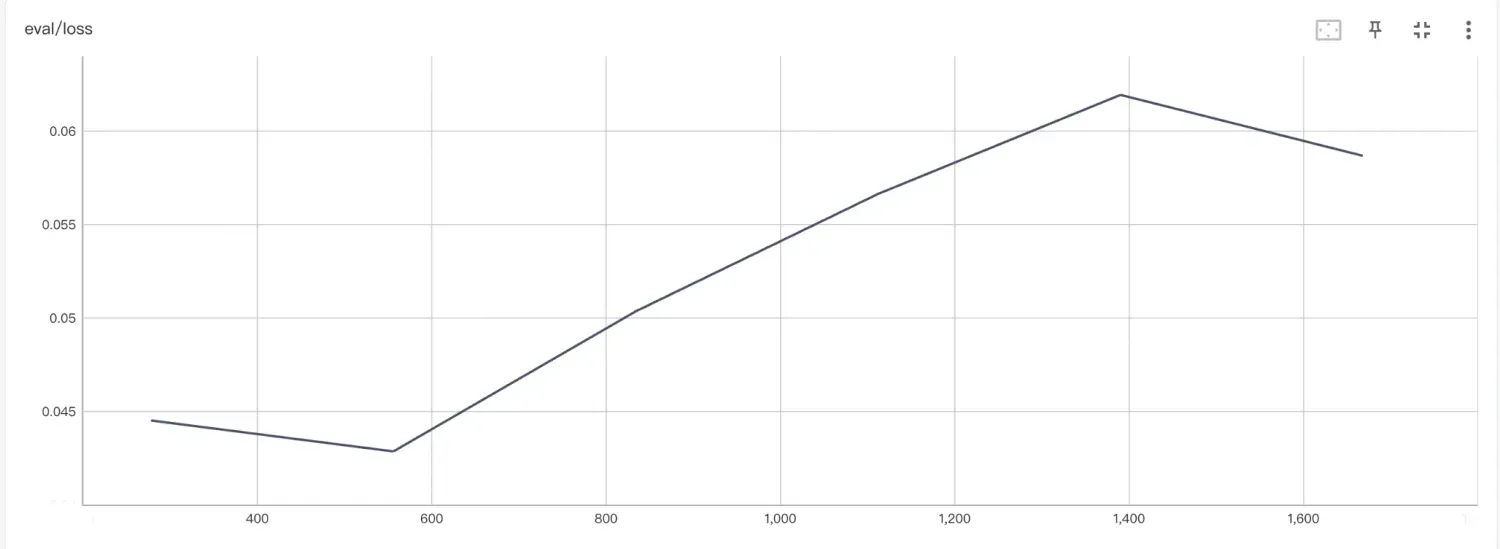 |
可以看到,随着模型尺寸的增大,eval loss 略微下降,这说明模型的泛化能力有略微的提升。从评测指标上来看,随着模型尺寸的增大,准确率略有上升,但上升幅度不大。这种趋势符合《Scaling Laws for Neural Language Models》中描述的缩放定律。
此外,还可以对比相同尺寸的大模型基座对下游意图识别任务的影响
| 模型 | 验证 Loss |
|---|---|
| Qwen2.5-7B-Instruct | 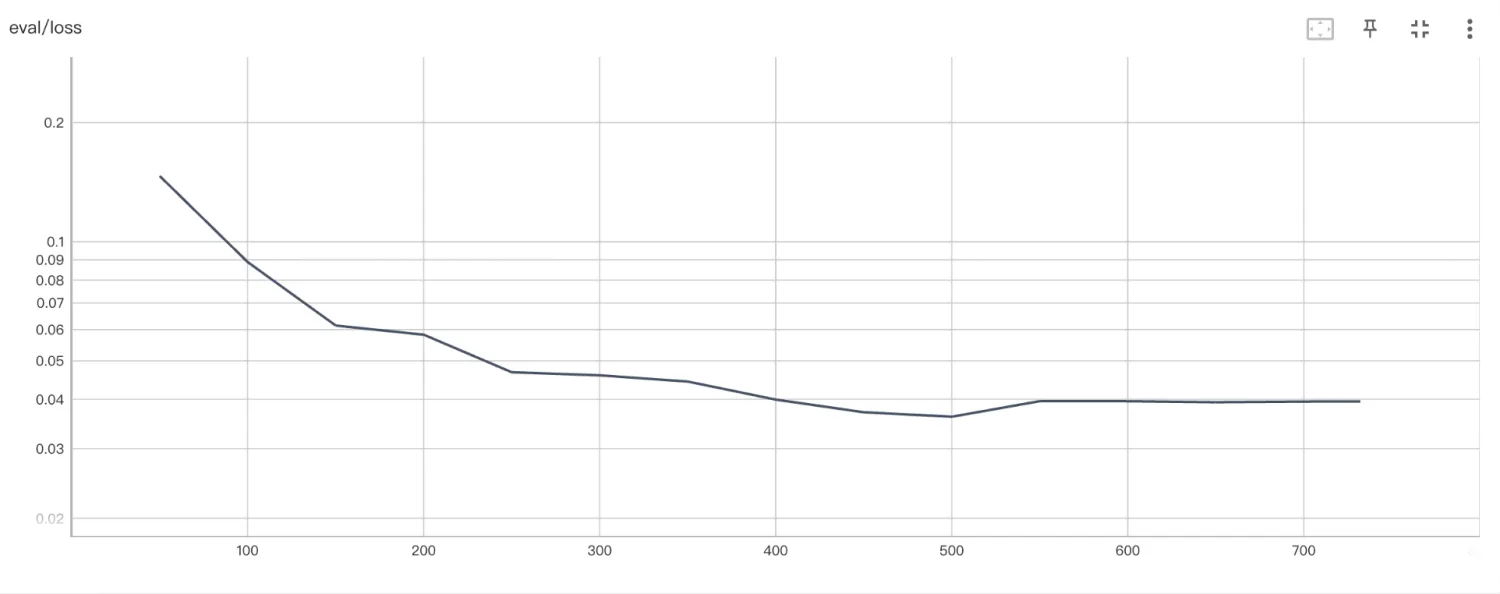 |
| Qwen2.5-7B | 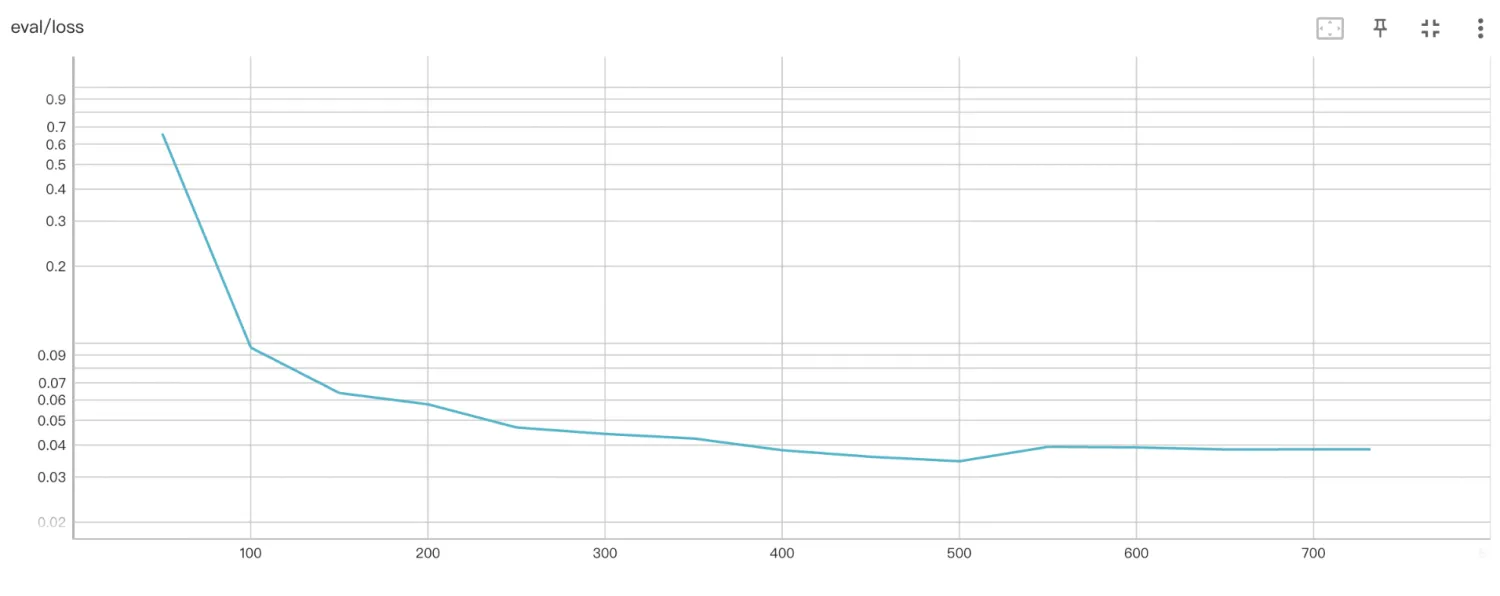 |
可以发现,相同尺寸的大模型在微调后的表现几乎一致,这说明意图识别仅需要大模型预训练所带来的语义理解能力,而不需要指令微调带来的指令遵循能力。这和意图识别本身的任务特点有关(重点在于语义的理解,而非复杂指令的遵循)。