经典多模态模型CLIP - 直观且详尽的解释
在本文中,您将了解“contrastive language-image pre-training”(CLIP),这是一种创建视觉和语言表示的策略,效果非常好,可用于制作高度特定且性能卓越的分类器,而无需任何训练数据。本文将介绍其理论,CLIP 与更传统的方法有何不同,然后逐步介绍其架构。

这对谁有用?任何对计算机视觉、自然语言处理 (NLP) 或多模态建模感兴趣的人。
经典图像分类器
在训练模型检测图像是猫还是狗时,一种常见的方法是向模型提供猫和狗的图像,然后根据误差逐步调整模型,直到学会区分两者。

这种传统的监督学习形式在许多用例中都是完全可以接受的,并且众所周知在各种任务中表现良好。然而,这种策略也会导致高度专业化的模型,这些模型仅在其训练的范围内表现良好。

将 CLIP 与传统的监督模型进行比较,每个模型都使用 ImageNet(一种流行的图像分类数据集)进行训练,并且表现良好,但当暴露于包含不同表示形式的相同类别的类似数据集时,传统监督模型的性能会大幅下降,而 CLIP 则不会。这意味着 CLIP 中的表示形式比其他方法更稳健、更通用。 因为CLIP为了解决过度专业化的问题,采用了完全不同的分类方法;通过对比学习来学习图像与其注释之间的关联。
CLIP 简介
如果我们不创建一个可以预测图像是否属于某个类别的模型,而是创建一个可以预测图像是否属于某个任意标题的模型,结果会怎样?这是一种微妙的思维转变,为全新的训练策略和模型应用打开了大门。

CLIP 的核心思想是使用从互联网上抓取的带字幕的图像来创建一个模型,该模型可以预测文本是否与图像匹配。

CLIP 通过学习如何对图像和文本进行Embedding来实现这一点,当将文本和图像Embedding相互比较时,匹配的图像具有较高的相似度,而不匹配的图像具有较低的相似度。**本质上,该模型学习将图像和文本映射到同一个Embedding空间中,使得匹配的图和文Embedding彼此靠近,而不匹配的图和文Embedding彼此相距较远。**这种学习预测事物是否属于同一类或不属于同一类的策略通常被称为“对比学习” (contrastive Learning)。

在 CLIP 中,对比学习是通过学习文本编码器和图像编码器来完成的,它们学习将输入映射到向量空间中的某个位置。然后,CLIP 在训练期间比对这些位置,并尝试最大化不匹配的图和文的Embedding距离,并最小化匹配的图和文的Embedding距离。

CLIP 采用的训练策略允许我们做各种各样的事情:
- 我们可以通过询问模型哪些文本(如“一张猫的照片”和“一张狗的照片”)最有可能与图像相关联来构建图像分类器
- 我们可以构建一个图像搜索系统,用于查找与输入文本最相关的图像。例如,我们可以查看各种图像,并找出哪张图像最有可能对应于文本“一张狗的照片”
- 我们可以使用图像编码器来提取与文本相关的图像的抽象信息(Embedding)。编码器可以将图像的信息嵌入成一个embedding,由此图像的信息可通过Embedding供其他机器学习模型使用。
- 同样我们可以抽取文本的Embedding可供其他机器学习模型使用。
CLIP 的组成部分
CLIP 是一种High-Level的框架,不局限于某个具体的网络结构,可以使用各种不同的子组件来实现相同的结果。
文本编码器

CLIP 中的文本编码器将输入文本转换为表示文本含义的Embedding向量(数字列表)。

CLIP 中的文本编码器是一个标准的 Transformer 编码器。就本文而言,Transformer 可以被认为是一个系统,它获取整个单词输入序列,然后重新表示和比较这些单词以创建整个输入的抽象、上下文的表示。
Transformer 中的自注意力机制是创建该上下文化表示的主要机制。

CLIP 对通用 Transformer 所做的一项修改是,它只会输出一个向量,而不是上图所示的一个矩阵,它直接提取输入序列中最后一个标记的向量来表示整个输入的文本序列。

图像编码器

同理,图像编码器将图像转换为表示图像含义的Embedding向量(数字列表)。

CLIP 论文中讨论了几种图像编码器方法。在本文中,考虑 ResNET-50,这是一种久经考验的卷积方法,已应用很多常规图像任务。我将在以后的文章中介绍 ResNET,但就本文而言,出于方便,我们可以简单的将 ResNET 视为经典的卷积神经网络。
卷积神经网络是一种图像建模策略,它使用一个称为卷积核的小值矩阵来扫描图像,并根据卷积核和输入图像为每个像素计算一个新值。

卷积网络背后的整个想法是,通过对图像进行卷积和下采样的组合,可以提取更多更微妙的特征表示。一旦图像被压缩为少量高质量的抽象特征,就可以使用密集网络(Dense Layer)将这些特征转换为最终输出。
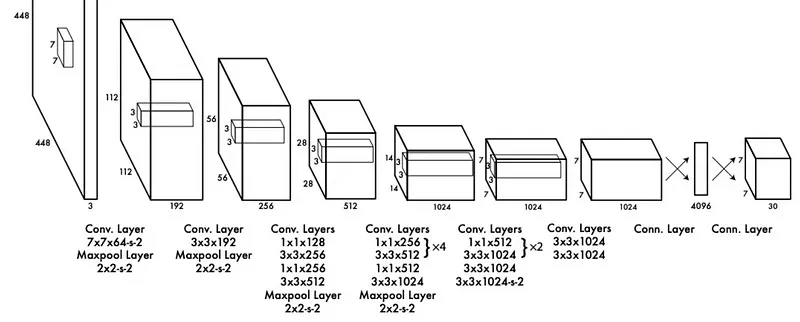
从 CLIP 的角度来看,最终结果是一个向量,可以将其视为对输入图像的高度抽象。

多模态嵌入空间和 CLIP 训练

在前两节中,我们讨论了可以将文本和图像嵌入为向量的建模策略,将复杂事物概括为抽象向量的想法通常被称为“嵌入”。我们将图像和文本等事物“嵌入”到向量空间中,以此来概括它们本身的含义或信息。

我们可以将这些嵌入向量视为将输入表示为高维空间中的某个点。为了便于说明,我们可以想象创建编码器,将其输入嵌入到维度为 2 的向量中。然后可以将这些向量视为二维空间中的点,我们可以绘制它们的位置。

我们可以将这个二维空间视为多模态嵌入空间,并且我们可以训练 CLIP(通过训练图像和文本编码器)从而将这些点映射到图文彼此接近的位置。

在机器学习中,有很多种方法可以定义“接近”。可以说,最常见的方法是余弦相似度,CLIP 就是采用这种方法。余弦相似度背后的理念是,如果两个向量之间的角度较小,我们可以说它们是相似的。

如果两个向量之间的角度很小,则这两个向量之间的余弦相似度将接近 1。如果向量相隔 90 度,则余弦相似度将为零。如果向量指向相反的方向,则余弦相似度将为 -1。
我们可以使用以等式来计算两个向量之间的角度的余弦相似度:
