多模态RAG:通用框架方案调研汇总
目 录
- 标准 RAG
- 多模态
- 多模态RAG
-
一些多模态RAG具体方案
- 1. Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications
- 2. ColPali
- 3. LLM2CLIP:Powerful Language Model Unlocks Richer Visual Representation
- 4. M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
- 5. FIT-RAG: Are RAG Architectures Settling On A Standardised Approach?
- 最后安利一些不错的开源Demo
- Reference
多模态检索增强生成是一种新兴的设计范式,允许AI模型与文本、图像、视频等存储进行交互。在介绍多模态 RAG 之前,我们先简单了解一下传统的检索增强生成 (RAG)。
标准 RAG
RAG 的理念是找到与用户查询相关的核心信息,然后将该信息注入Prompt中并将其传递给大语言模型(LLM)从而生成回答。

RAG 系统的检索通常是通过Embedding来实现的。为了对某些内容进行Emebdding,通常使用复杂的 AI 模型将信息转换为纯数字的向量。

检索过程基于一组候选文档和用户query,通过计算它们的向量相似度来完成,与用户query距离最小的文档则被视是为最相关的。 一旦 RAG 系统检索到足够的相关信息,就会使用用户query和相关文档来构建增强的Prompt,然后将其传递给LLM进行生成。
"Answer the customers prompt based on the following context:
==== context: {document title} ====
{the most relevant document content retrievaled by RAG}
...
prompt: {prompt}"
这种通用系统通常假设整个知识库由文本组成,但许多知识来源不止文本,可能还有音频、视频、图像等,这就是多模态 RAG(Multimodal RAG) 的作用所在。
在讨论多模态 RAG 之前,让我们先简单探讨一下多模态的概念。
多模态
在数据科学中,“模态”本质上是一种数据类型。文本、图像、音频、视频、表格,这些都可以被视为不同的“模态”。这些能够理解多种类型数据的模型通常被称为“多模态模型”。
多模态模型的理念通常围绕“联合Embedding”这一理念展开。联合Embedding是一种建模策略,它迫使模型同时学习不同类型的数据。该领域的一篇里程碑式论文是 CLIP,它创建了一个能够执行与图像和文本相关的任务的强大的多模态模型。自 CLIP 以来,已经出现了各种建模策略,以某种方式对齐图像和文本。

多模态RAG
多模态 RAG 的理念是允许 RAG 系统以某种方式将多种模态的信息注入多模态模型。因此,多模态 RAG 系统不仅可以根据用户问题检索文本片段,还可以检索图像、视频和其他不同模态的数据。
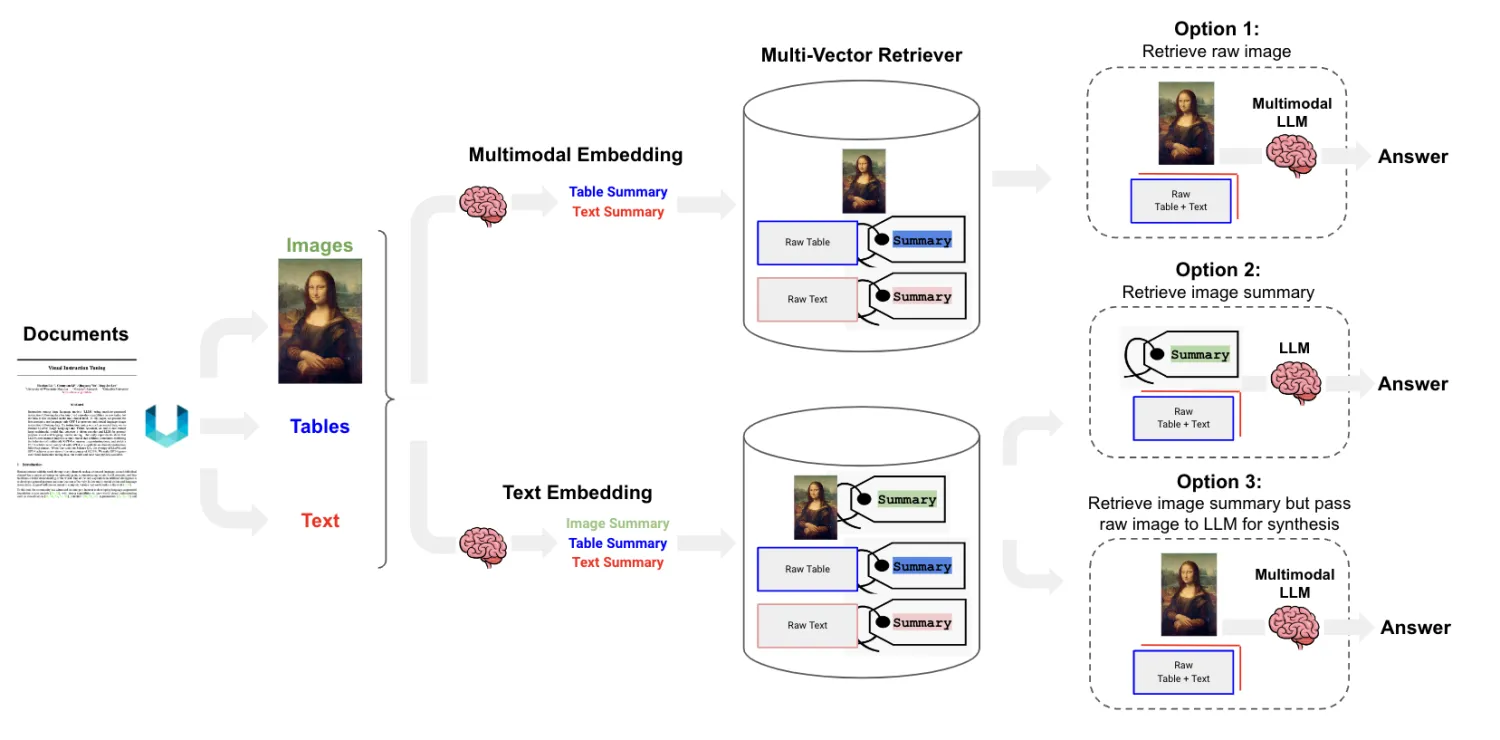
目前,基于LLM大模型,有三种MM-RAG的模式:
Option 1:
- 使用多模态LLM对文本和图片进行embedding
- 基于embedding对文本和图片进行相似检索
- 将检索到的原图片和文本输入LLM获取Answer
Option 2:
- 使用多模态LLM给图片生成文本摘要
- 对文本和生成的文本摘要进行embedding和检索
- 将检索的文本和文本摘要输入LLM获取Answer
Option 3:
- 使用多模态LLM对图片生成文本摘要
- 对文本和生成的文本摘要进行embedding
- 将检索的的文本和摘要对应的原始图片输入LLM获取Answer
Other Option:
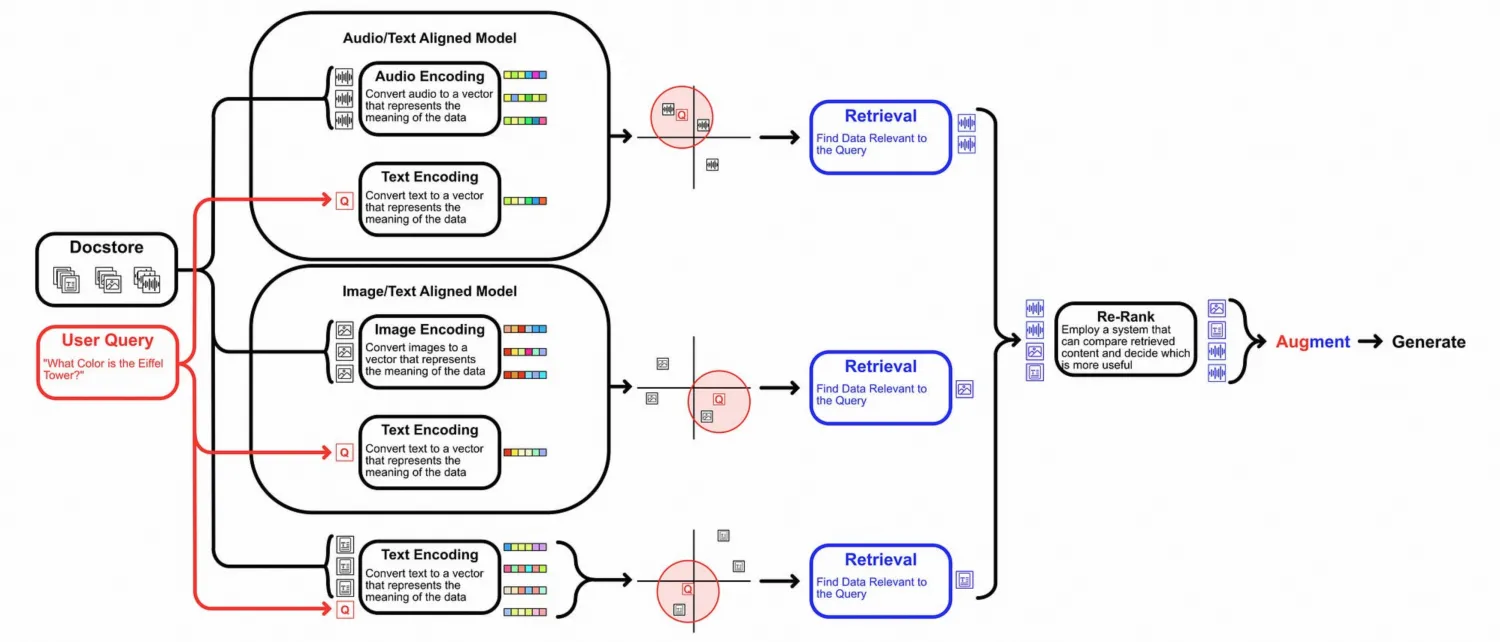
- 除此之外,还有另外一种模式,就是为每一种模态构建一个Embedding模型,每种模态数据单独检索,适用于有很多不同模态的数据场景,且需要对每种模态进行单独优化的场景,但缺点是复杂度高、维护成本高。
一些多模态RAG具体方案
以下是一些多模态RAG的相关工作,这些多模态RAG的框架基本上都是上述的几种Option中的一种,大同小异。
1. Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications
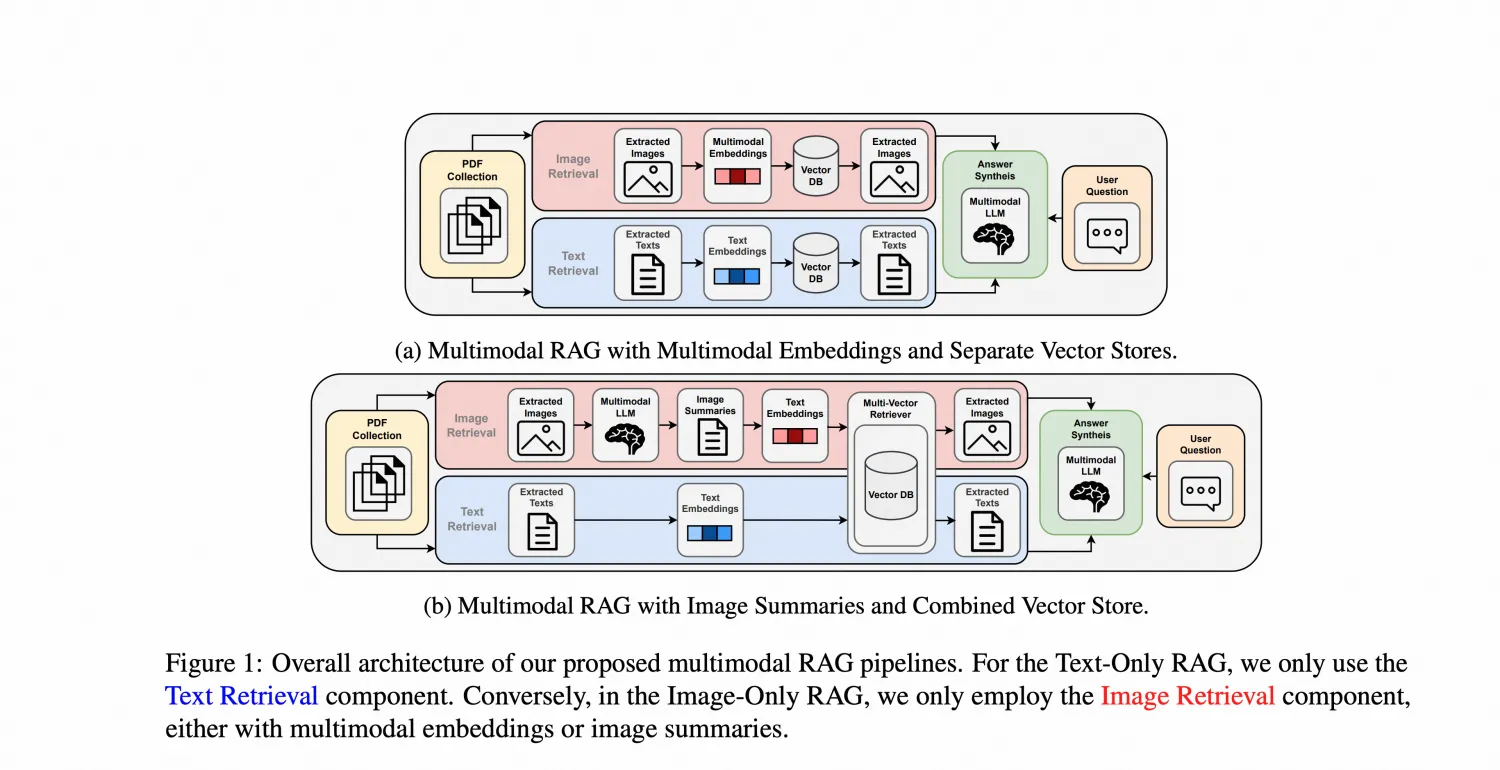
这篇文章里面讲了来两种MM-RAG框架,分别对应上面的Option 1 和 3
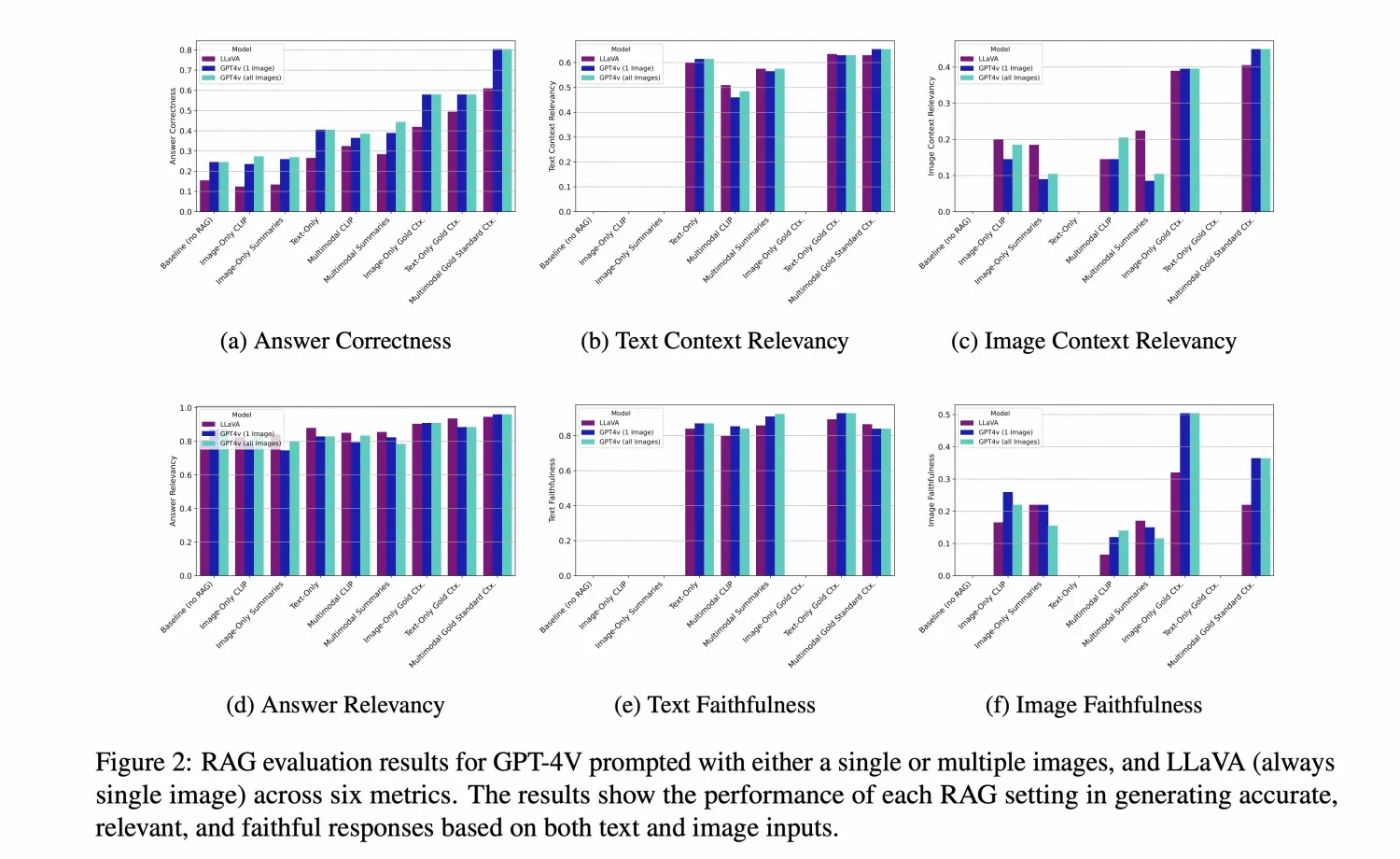
主要证明了几个点:
- 图片summary检索比图片Embedding检索效果好
- 多模态检索比单模太检索性能好
- 图片检索领域还需要继续优化
2. ColPali

文档通过一个Vision Encoder(PaliGemma-3B)直接切成patch,然后输入给一个Vision LLM(SigLIP-So400m)获得Patch Embedding,然后输入到一个Language Model(Gemma 2B)获得高维的上下文Embedding,最后通过一个Projector映射成128的低维向量。
检索的时候,在输入query后,会获取query每个token的embedding,每个token去检索最相似的patch,然后将所有token最相似的pathc的相似分加起来作为文档的相似分。
3. LLM2CLIP:Powerful Language Model Unlocks Richer Visual Representation
这篇文章其实是讲了一个新的多模态表征的方法,将LLM和经典的CLIP结合起来,用LLM强大的文本表示能力来增强CLIP的文本表示能力。(推荐做Embedding的使用此模型,在CoCo数据集上准确率90%+)
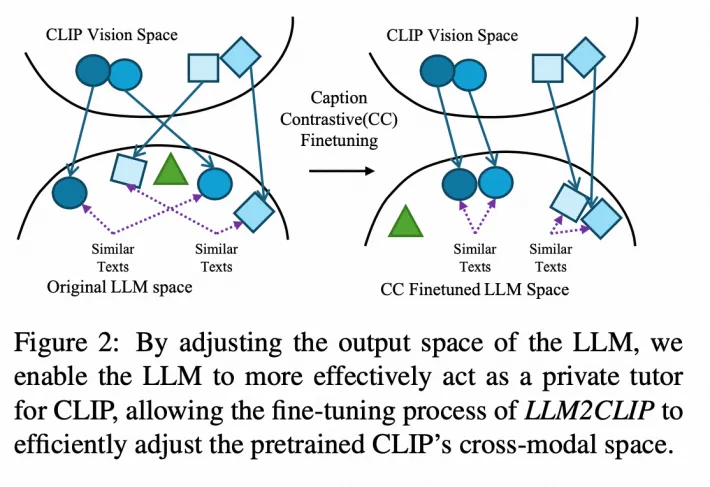

先是证明了LLM虽然理解文本的能力很强,但是其输出的embedding的区分性很低:MS-COCO数据集,每个图片有5个caption,随机选取两个作为 pair,同一个图片的两个caption作为positive sample,其它图片的caption作为negative sample。比如图片$ i_1 $的两个caption $ <c^1_1, c^1_2>$和图片$ i_2 $的连个caption$ <c^2_1, c^2_2>$是正样本,而$ <c^1_1, c^2_2>$则可以视作负样本。 Caption Retrieval Accuracy(CRA),LLM直接对给定的caption检索其对应的另一个caption,准确率,Caption Retrieval Accuracy(CRA)在5%-10%左右。
然后通过caption-to-caption对比学习优化LLM的输出,使其具有区分性,微调后,LLM的CRA到80%以上,充分释放了LLM的语言处理能力。
最后用训练好的LLM替换CLIP原有的文本处理模块,并对CLIP的视觉部分进行微调。微调时,LLM的参数冻结,并且各添加一个Projector模块来实现对齐。
4. M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
使用ColPali的文档embedding方法获取embedding,然后计算query和文档之间的相似度(MaxSim)取top-K,然后使用Qwen2-VL进行回答问题。本质上没有太多的创新点。提供了一个新的Benchmark。


5. FIT-RAG: Are RAG Architectures Settling On A Standardised Approach?
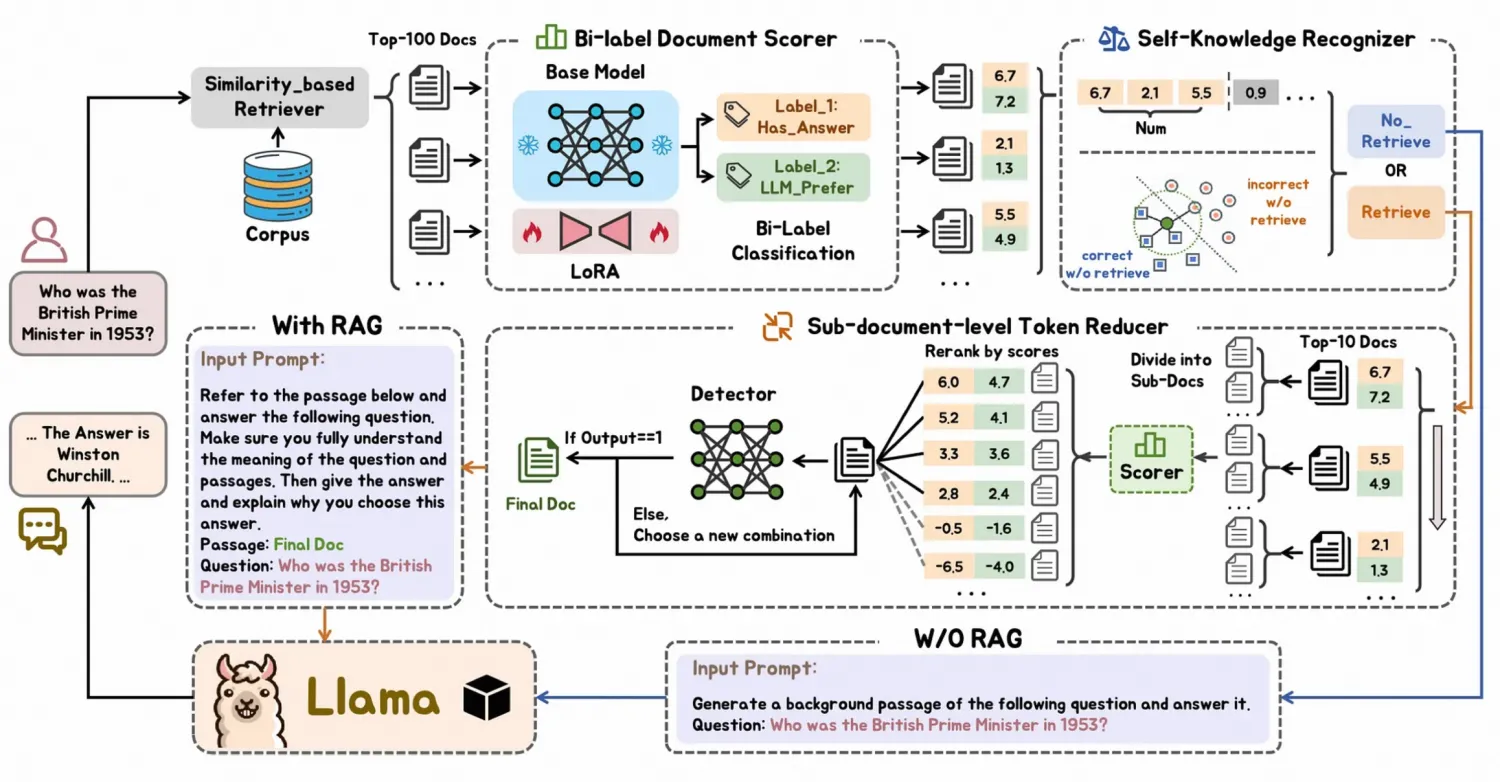
FIT-RAG 由五个组成部分组成:
- 基于相似性的检索器
- 双标签文档评分器
- 双面自我知识识别器
- 子文档级标记减少器
- 提示构建模块
双标签文档评分器使用双标签学习进行训练,其中涉及两个标签,Has_Answer标签表示该文档是否包含问题的答案,而LLM_Prefer标签表示该文档是否有助于LLM生成准确的答案。
- 事实信息 ( Has_Answer )
- LLM 偏好(LLM_Prefer)
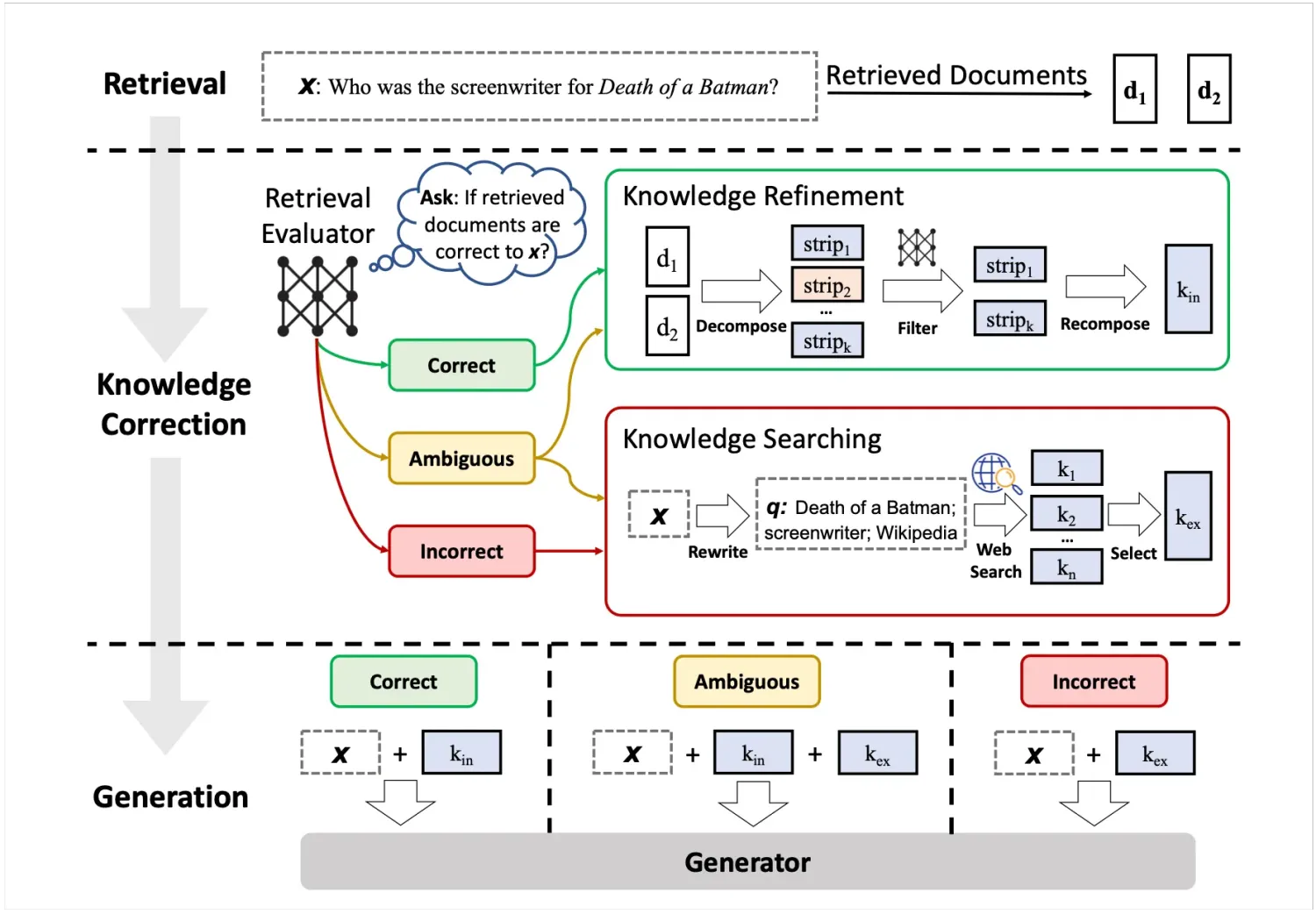
其中提到了CRAG,一个轻量的RAG质量评估方案,感觉还不错就放这里了,不用过多讲了,看图就能很清楚了。
最后安利一些不错的开源Demo
1. kotaemon
性能非常不错,目前见到的最满意的多模态的Demo了。支持图片、url、pdf等文件,还支持GraphRAG(待探索),还提供API接口。kotaemon

2. clip_blip_embedding_rag
是一种基于CLIP/BLIP模型的嵌入服务,该服务支持文本和图像的嵌入生成与相似度计算,为多模态信息检索提供了基础能力。clip_blip_embedding_rag

Reference
https://github.com/langchain-ai/langchain/blob/master/cookbook/Multi_modal_RAG.ipynb
https://arxiv.org/pdf/2410.21943