多模态大语言模型(MMLLM)的现状、发展和潜力
1、大模型
随着ChatGPT流行,大模型技术正逐渐成为AI领域的热点。许多行业大佬纷纷投身于这一赛道,展示了大模型的独特魅力和广阔前景。
王慧文,前美团联合创始人,发起“AI英雄帖”。
李志飞,出门问问创始人,打造中国版OpenA。
李沐 和 Alex Smola,前亚马逊员工,师徒俩携手大模型创业。
周伯文,前京东AI部门负责人,强调大模型并非大公司专属。
王小川,前搜狗CEO,认为OpenAI的成功是技术理想主义的胜利。
李岩,快手前AI核心成员,投身于大模型赛道。
贾扬清,阿里巴巴VP,专注构建大模型基础设施,已完成首轮融资。
1.1、不是“大”的模型就叫大模型
关于大模型,部分学者描述它为“大规模预训练模型”(large pretrained language model),同时还有学者提出了“基础模型”(Foundation Models)的新概念。为AI技术的发展和应用提供了新的视角和可能性。
在2021年8月,李飞飞、Percy Liang以及其他一百多位学者共同发布了一篇名为《On the Opportunities and Risks of Foundation Models》的文章,其中引入了“基础模型”(Foundation Models)这一术语。文章中指出,这类基于自监督学习的模型在训练过程中展现出多方面的能力,这些能力不仅为各种下游应用提供了动力,也奠定了理论基础,因此将这类大模型称为“基础模型”。
小模型: 主要是为特定的应用场景设计并训练的,能够完成特定的任务。然而,当应用到其他场景时,这些模型可能无法直接适用,需要进行重新训练。目前大多数模型都属于这一类,其训练方式类似于“手工作坊式”,依赖大量的标注数据。如果应用场景的数据量不足,这些模型的精度往往不会达到理想状态。
大模型: 则在大规模的无标注数据上进行训练,从而学习到广泛的特征和规则。在使用大模型开发应用时,可以通过对大模型进行微调(在具体的下游应用中使用小规模的标注数据进行二次训练)或者不进行任何微调,使其能够适应并完成多种应用场景下的任务,展现出其通用的智能能力。
1.2、大模型赛道早已启动

多语言预训练大模型
- Facebook推出了M2M-100模型,支持100种语言的直接互译,无需依赖英语作为中介语言,这在机器翻译领域是一个重大突破。
- 谷歌公开了多语言模型MT5,该模型基于101种语言训练,使用了750GB的文本数据,拥有高达130亿个参数。在多种多语言自然语言处理任务的基准测试中,MT5表现出色,涵盖了机器翻译、阅读理解等领域。
多模态预训练大模型
- OpenAI开发了包括DALL·E和CLIP在内的多模态模型,这些模型具有120亿参数,特别在图像生成等任务上展现出优异的性能。
多任务预训练大模型
- 在2022年的IO大会上,谷歌介绍了多任务统一模型(MUM)的进展。MUM模型基于大量网页数据进行预训练,能够理解75种语言,并擅长处理复杂的决策问题,通过分析跨语言多模态网页数据来寻找信息。
视觉预训练大模型
- 如ViTransformer等模型展现了视觉通用能力,这在视觉任务中非常关键,尤其是在自动驾驶等视觉处理密集的应用领域,视觉大模型的应用潜力巨大。
1.3、深度学习范式正在发生变革
AI的研发和应用范式可能将经历巨大变革。许多行业领袖投身于大模型赛道,可能是因为他们预见到了深度学习2.0时代的到来。
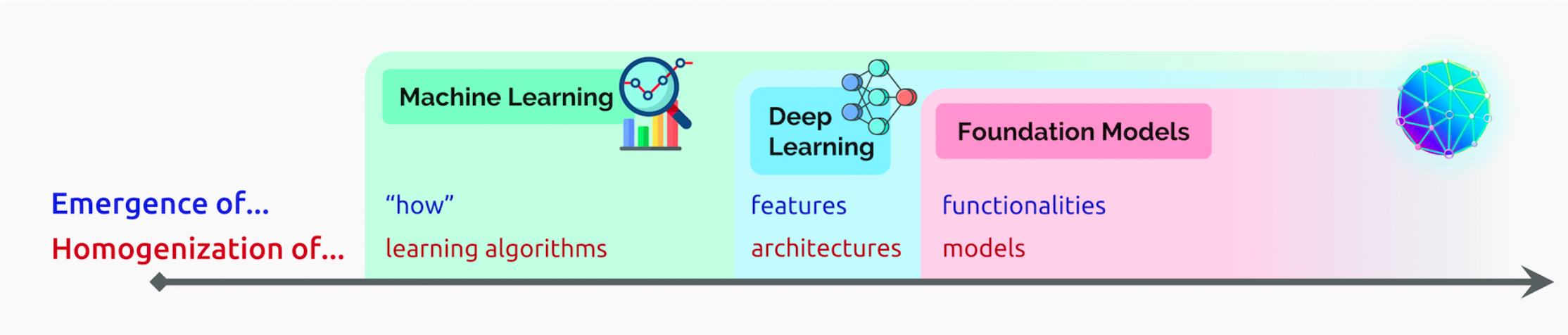
machine learning homogenizes learning algorithms (e.g., logistic regression), deep learning homogenizes model architectures (e.g., Convolutional Neural Networks), and foundation models homogenizes the model itself (e.g., GPT-3)
正如文章中提到的,机器学习中的同质化学习算法(如逻辑回归)、深度学习中的同质化模型结构(如CNN),基础模型则是对模型本身的同质化(例如GPT-3)。

人工智能的发展已经从“大炼模型”逐步迈向了“炼大模型”的阶段。ChatGPT仅是一个开始,其背后的基础模型(Foundation Module)的长远价值更加值得期待。
1.4、大模型是厚积薄发的
大模型不是一蹴而就的,发展的早期阶段被称为预训练模型阶段,其核心技术是迁移学习。当目标应用场景的数据不足时,模型首先在大规模的公开数据集上进行训练,然后迁移到特定场景中,并通过少量的目标场景数据进行微调,以达到所需的性能。这种在公开数据集上训练的深度网络模型,被称为“预训练模型”。使用预训练模型可以显著减少下游任务对标注数据的依赖,有效处理数据标注困难的新场景。
2018年,大规模自监督神经网络的出现标志着一次真正的革命。这类模型的核心在于通过自然语言句子创造预测任务,例如预测下一个词或预测被掩码的词或短语。这使得大量高质量的文本语料成为自动获取的海量标注数据源。通过从自身预测错误中学习超过10亿次,模型逐渐积累了丰富的语言和世界知识,从而在问答、文本分类等更有意义的任务中展现出优异的性能。这正是BERT和GPT-3等大规模预训练语言模型的精髓,也是所谓的“大模型”。
1.5、大模型的革命性意义
突破现有模型结构的精度局限
在2020年1月,OpenAI发布了一篇论文,研究了模型性能与模型规模之间的关系。结论表明,模型的表现与其规模之间遵循幂律关系,即模型规模的指数级增长会带来模型性能的线性提升。
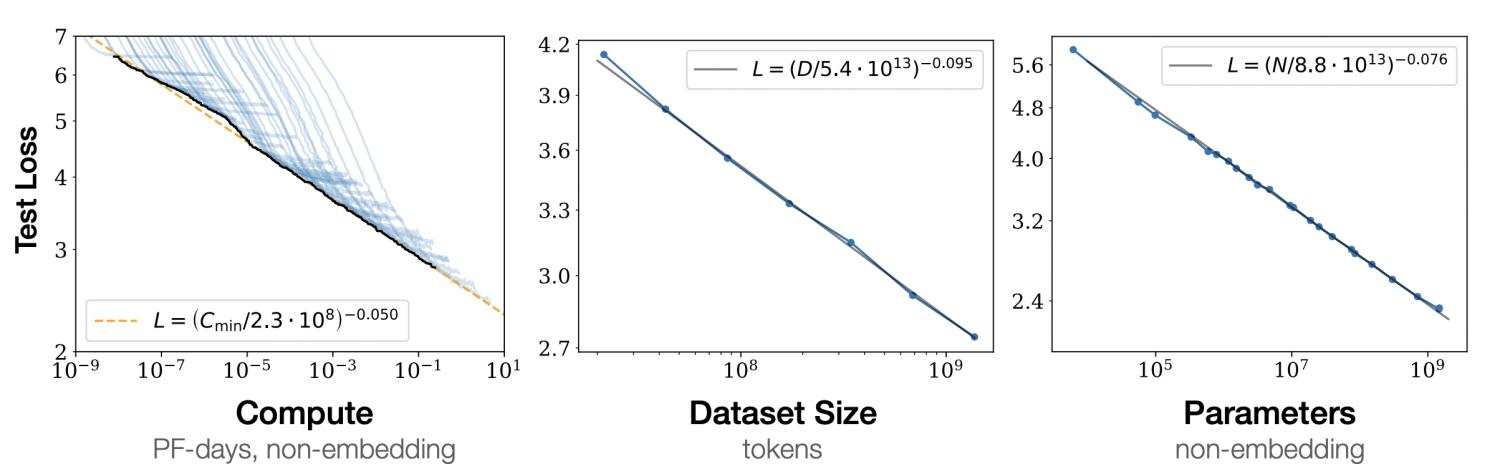
在2022年8月,Google发布了一篇论文,重新审视了模型性能与模型规模之间的关系。研究发现,当模型规模达到一定的阈值后,模型在处理某些问题上的性能会出现快速增长。研究者们将这种现象称为“涌现能力”(Emergent Abilities)。

预训练大模型与场景微调:长尾应用优化
根据斯坦福大学著名NLP学者Chris Manning教授的观点,通过在未标注的海量语料上训练大模型可以:
Produce one large pretrained model that can be very easily adapted, via fine-tuning or prompting, to give strong results on all sorts of natural language understanding and generation tasks.
通过微调或使用提示,大规模预训练模型能够轻松适应各种自然语言理解和生成任务,并能产生出色的结果。
大模型的“大道至简”
基于简单的Transformer结构之所以展现出强大的能力,关键在于其通用性。预测下一个单词这样的任务既简单又通用,几乎所有类型的语言学和世界知识,包括句子结构、词义引申、基本事实等,都能助力这一任务的成功执行。在训练过程中,大模型也学习到了这些信息,使得单一模型在接受少量指令后便能解决多种不同的NLP问题。这或许是“大道至简”理念的最佳体现。
在2018年之前,基于大模型完成多种NLP任务主要依靠微调(fine-tuning),即在少量专门为任务构建的有监督数据上继续训练模型。而后来出现了提示学习(prompting)的方法,这种方式仅需用语言描述任务或给出几个示例,模型便能有效执行之前未经训练的任务。
1.6、大模型真的理解了人类语言吗?
要深入讨论这个问题,我们需要探讨“语义”的定义以及语言理解的本质。在语言学和计算机科学领域,主流的理论认为一个单词、短语或句子的语义(denotational semantics),是指它所代表的客观世界中的对象。与此形成对比的是深度学习NLP所遵循的分布式语义(distributional semantics):单词的语义由其出现的上下文环境决定。
更通俗的说,以“你吃饭了吗”?“我吃过了”为例,“吃饭”的语义是什么呢?
主流理论:“吃饭”(短语)表示的是“端着一碗饭,用筷子扒拉到嘴里吃掉”或者“手里拿着面包总到嘴里吃掉”这些行为过程(客观世界中的对象)。
分布式语义:“吃饭”这个词,从概率统计的角度,它有很大的可能出现在“你____了吗?我吃过了。”这个句子里面,是语言在形式上的一种连接,仅此而已。模型并不知道“往嘴里塞东西吃”这个客观世界里可以听见或看见的过程叫“吃饭”。
Meaning arises from understanding the network of connections between a linguistic form and other things, whether they be objects in the world or other linguistic forms.
意义来源于理解语言形式与其他事物之间的连接,无论它们是语言形式还是世界上其他的物体。
引用NLP领域权威Chris Manning的话,如果用语言形式之间的联系来衡量语义,当前的大模型已经在语言理解方面做得相当出色。然而,这种理解的局限性在于它仍然缺乏对客观世界知识的深入把握,并且需要通过其他模态的感知来进行增强。毕竟,用语言来描述图像和声音等,远不如直接接收这些信号来得直观和有效。
2、多模态大模型的蓬勃发展
本文专注于图像-文本领域近年来一些经典的视觉语言预训练模型(Vision-and-Language Pre-training,VLP)以及当前的一些多模态大语言模型(Multimodal Large Language Models,MLLM)。
目前业界尚无一个严格定义的多模态“大”模型。为了明确本文的讨论范围,我们将基于transformer或其变体为主要结构,能够输入/输出并处理除了人类语言/代码之外的其他非结构化或半结构化模态数据的算法模型,定义为多模态模型。
尽管像dense caption这类模型也能从图像生成文本描述,但由于它们主要基于R-CNN和LSTM而非transformer结构,并且这些模型较早在2019年就已提出,因此本文不将其作为主要讨论对象。

2.1、基础模型MoCo(2019)
Highlight: 在众多经典的多模态预训练算法(如ALBEF、MPLUG等)中,动量蒸馏技术被广泛应用,而这一技术的思想源自于MoCo(Momentum Contrast)算法。

主要创新是提出了动态队列的概念,利用momentum encoder通过队列提供负例。 在对比学习中,模型的性能与负样本的数量成正比,即负样本越多,模型的效果越好。负样本的采样方式主要包括以下几种:
end2end:传统的对比学习方法可以分为两种输入方式。第一种是输入三元组 (x, y, 1/0),在数据集准备阶段完成正负样本的采样;第二种是模型仅输入正例 (x, y),并将batch内其余的sample作为负例,负样本的数量为 batch size - 1,当batch size较小时,负样本较少。
memory bank:使用memory bank来存储和采样负样本。memory bank中存储的是Encoder编码的特征,并在其中采样负样本。由于memory bank的容量远大于batch size,这种方式可以显著增加负样本的数量。然而,由于memory bank中存储的特征来自不同阶段的Encoder,这可能导致采样的特征具有不一致性。
MoCo:提出使用一个队列来存储和采样负样本。在memory bank的基础上,MoCo引入了一个动量编码器(Momentum Encoder),该编码器以Encoder的参数为初始化,但以较慢的速度更新梯度。队列采用动态更新方式,新的batch的特征会替换队列中旧的batch特征,以此缓解队列中的特征不一致性问题。
2.2、图像表征模型
图像表征模型的主要功能是将非结构化的图像转换为结构化或半结构化的数据,这种数据包含了图像的各种特征信息,用于支持下游模型的进一步处理和理解。图像表征模型构成了所有视觉多模态模型的基础。
从定义上看,类似于2019年提出的dense caption这类将图像转换为文本描述的模型,也可以被视为一种广义上的图像表征模型。尽管在学术界使用这种模型的情况较少,它们主要用于生成多模态的图文对齐训练数据。更常见的图像表征模型如经典的R-CNN模型ResNet,通常需要移除最后的全连接层以适用于多模态应用。
在当前新兴的多模态大模型中,图像表征模型趋向于使用如ViT这样的模型。尽管ResNet和ViT本质上仍是单模态的表征模型,它们却构成了绝大多数多模态模型的基础。
2.2.1、Vision Transformer (ViT, 2020)
Highlight:Transformer结构被引入到图像领域后,成为了一个里程碑式的经典。在此之前,图像特征提取主要依赖于ResNet模型。伺候,大多数经典的图像模型都开始采用ViT(Vision Transformer)框架作为图像编码器。

谷歌在2020年首次将Transformer结构引入到视觉处理领域,提出了这一创新模型。该模型的核心在于将输入的图像转换成一个扁平化的数据序列,然后进行Patch Embedding和位置编码,之后这些数据被送入一个几乎是标准的Transformer Encoder结构中进行处理。处理后的输出即为图像的表征,这些表征可以直接连接到一个多层感知机(MLP)上,用于分类等下游任务。
技术细节不是我们的主要关注点,重要的是要了解ViT(Vision Transformer)首次证明了基于Transformer结构处理图像在许多任务上能够超越传统的CNN算法,如Yolo、ResNet。特别值得注意的是,在训练数据集较小的情况下,ViT的性能可能不如ResNet;然而,一旦训练数据集足够大,ViT则展现出更强的识别能力。
基于ViT的发展,后续衍生出了如Swin Transformer等模型,这些模型甚至被用于自动驾驶车辆的感知模型。严格来说,这些都是处理传统图像识别、检测、分割任务的单模态“大模型”,并不能单独用于处理VQA(视觉问答)、多模态图文检索等典型的多模态任务。然而,它们为大多数多模态模型提供了基础参考。
2.2.2、Masked Autoencoders (MAE, 2021)
Highlight:类似于NLP领域的MLM(Masked Language Model)任务,可以将一张图片按比例进行遮盖(Mask),通过未被遮盖的区域来预测被遮盖掉的部分,从而使模型学习到图像的特征。
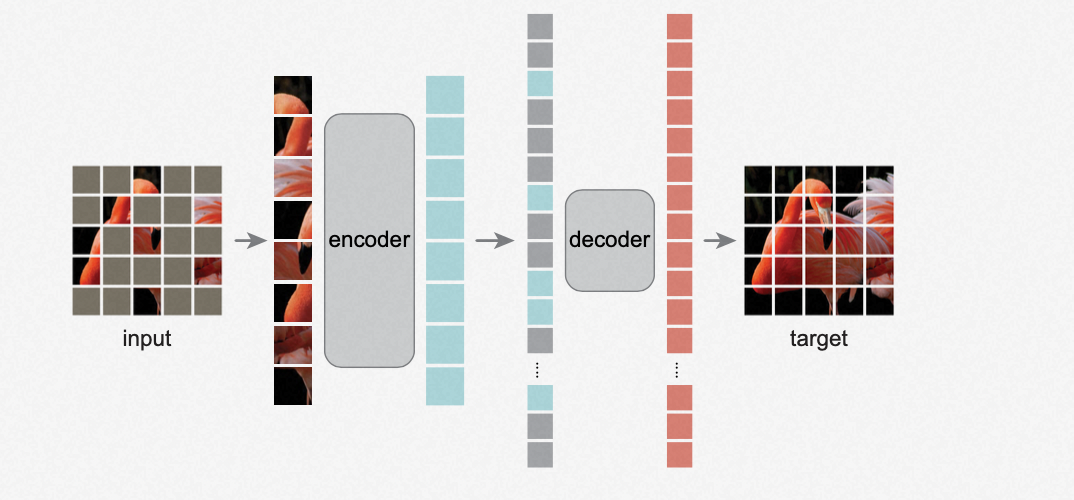
主要创新包括模型结构和训练过程:
模型结构(非对称的encoder、decoder)
- Encoder部分:采用VIT结构。
- Decoder部分:采用轻量级的Transformer结构,具体为8层,隐藏层大小为512的Transformer。
训练过程
- 将图片分割成多个patch。
- 对图片中的patch按照一定比例随机进行遮盖(Mask)。
- 将未被Mask的patch输入到encoder中。
- 在decoder前拼接被Mask的位置信息。
- 使用decoder解码每个patch的结果,通过比较复原的图片和原图,训练模型以学习图像的表示。
部分复原效果展示:

论文中对各种Mask比例进行了实验,最终得出最佳的Mask比例为75%:

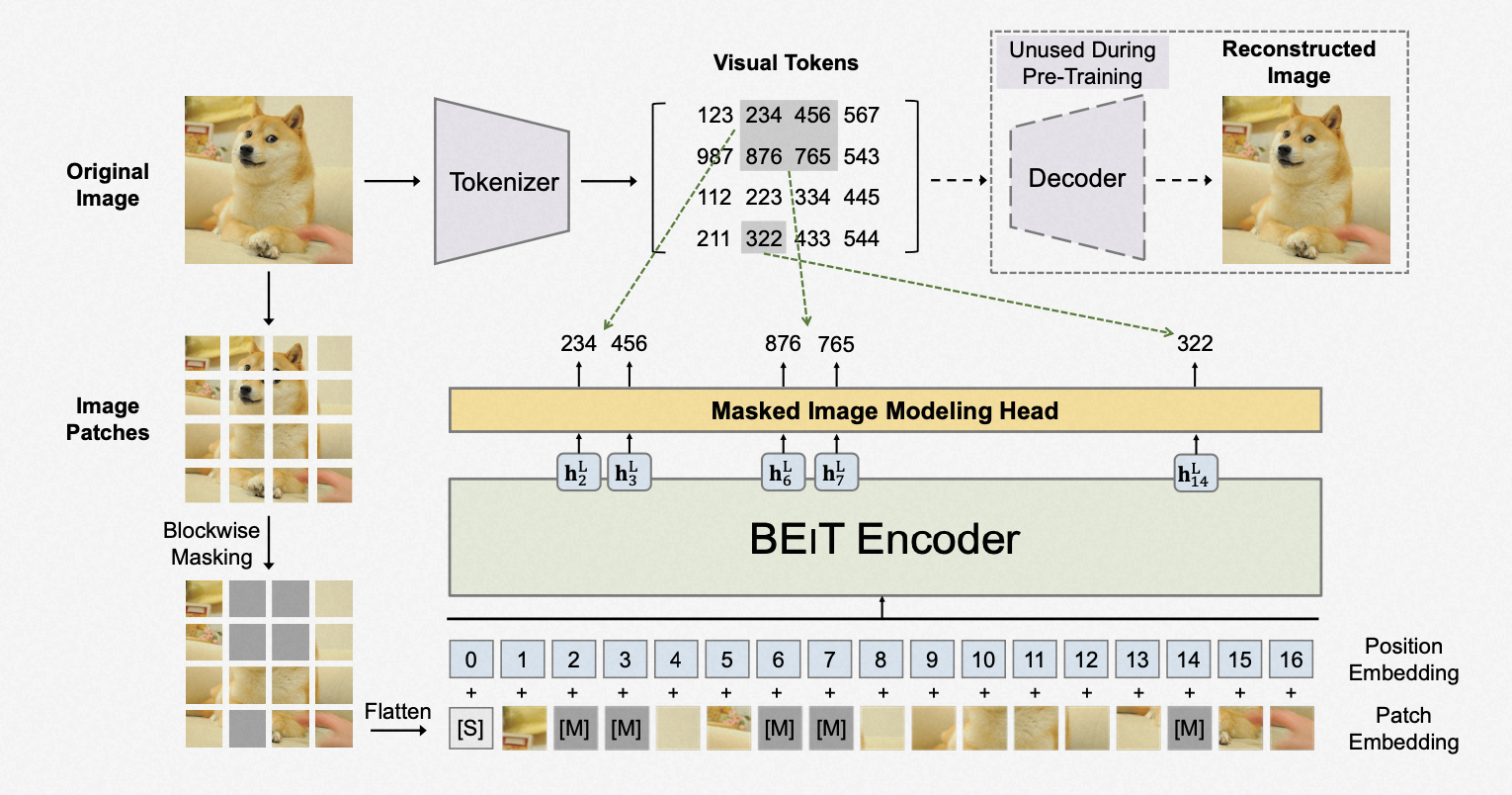
2.2.3、BeiT (2021)
Highlight:主要创新点是模型结构是BEIT Encoder + dVAE。
2.3、图文对齐模型
在处理多模态数据时,常用的方法包括对齐和桥接两种策略:
对齐:这一策略涉及将不同模态的表征编码器模型(例如图像的ViT和语言的Bert)通过特定的训练方法,使它们的输出向量映射到同一个低维空间中。这通常需要同时训练所有模态的表征编码器。
桥接:这种方法使用转换器(Adaptor)模型,将一种模态的表征输出转换成另一种模态的处理模型的输入。这种方法将在文中的3.3部分进一步讨论。
2.3.1、Contrastive Language-Image Pre-Training (CLIP, 2021)
CLIP(Contrastive Language-Image Pre-Training)模型是OpenAI在2021年初发布的,用于匹配图像和文本的预训练神经网络模型,被认为是近年来多模态研究领域的经典之作。该模型利用大量的互联网数据进行预训练,在多种任务上达到了目前最佳的表现(SOTA)。
CLIP目前仍然是图文对齐模型中的佼佼者之一,其结构由一个ResNet构成的图像表征编码器和一个基于Bert结构的文本编码器组成,这些编码器可以替换为不同版本,包括ViT版本。在训练过程中,CLIP通过其特有的ITC Loss损失函数,同时输入图文对进行训练,采用对比学习方法,最终将两个编码器的输出映射到同一个向量空间中。
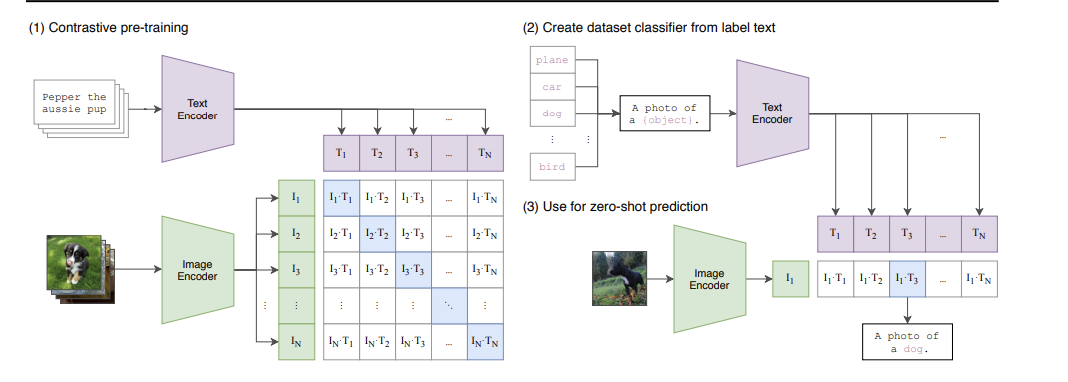
CLIP具有许多显著的优势:
结构简单:进行微调时所需的算力相对较小,尽管全量训练需要处理4亿图文对,耗时较长。 高效的相似度计算:输出的特征向量通过点乘方法进行相似度计算,这使得在向量数据库中进行跨模态检索变得非常方便。
多任务适用性:可以用于执行图片分类、图文检索等多种任务。两个编码器也可以作为单模态编码器单独使用,有时候能产生一些意想不到的效果,例如在图-图相似度检索中,利用CLIP训练好的图像编码器可以检索出语义相似而非像素相似的图片。
高性价比:已经展示出Zero-shot和Few-shot的学习能力。目前许多新模型在处理图文匹配任务上的表现仍然不如CLIP。
尽管CLIP的结构简单带来了许多优势,它也存在一些局限性,例如无法直接基于CLIP进行图片生成文本(讲故事)以及VQA(视觉问答)相关任务。BLIP模型的出现部分弥补了这些缺陷。
2.3.2、Align (2021)
Highlight:与CLIP类似的结构中,Align模型采用了超过10亿的带噪数据集进行训练,而且没有进行数据清洗。这种“大力出奇迹”的策略表明,通过扩大语料库规模可以弥补数据内部的噪声问题,即使是最简单的模型,也能达到最佳的状态(SOTA效果)。这种方法强调了在大规模数据训练中,数量往往能够弥补质量的不足。

训练出来的embedding有“图像数学”的搜索特性

2.3.3、Data efficient CLIP (DeClip, 2022)
Highlight:Data efficient CLIP在原CLIP模型基础上增加了监督任务,以提高数据利用效率并减少对大量数据的需求。这种改进使模型在使用较少数据时也能达到较好的性能。
在CLIP的图文对比学习基础上增加的监督任务包括:
各模态的自监督(self-supervision)

跨模态的监督(multi-view supervision):从一次InfoNCE扩展到四次InfoNCE
相似pair的邻居监督(nearest-neighbor (NN) supervision)

2.3.4、ALBEF (2021)
Highlight:这部经典之作引入了多模态编码器和ITM损失,将多模态预训练模型框架从单流模型提升为单流和双流模型结合的框架。
主要创新体现在模型结构、训练目标和优化点上。
模型结构结合单流模型和双流模型
-
单模态编码器:处理各模态信息
- 图像编码器:采用 𝑉𝐼𝑇(ViT),初始化参数使用 𝐶𝑙𝑖𝑝−𝑉𝑖𝑡(Clip-ViT)参数
- 文本编码器:采用 𝑇𝑟𝑎𝑛𝑠𝑓𝑟𝑜𝑚𝑒𝑟(Transformer),初始化参数使用 𝐵𝑒𝑟𝑡(Bert)的前六层参数
-
多模态编码器:进行模态交互
- 采用 𝑇𝑟𝑎𝑛𝑠𝑓𝑟𝑜𝑚𝑒𝑟(Transformer)结构,增加 𝐶𝑟𝑜𝑠𝑠 𝐴𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛(Cross-Attention)层进行图文交互,图片作为 𝑄𝑢𝑒𝑟𝑦(Query),文本作为 𝑘𝑒𝑦(Key)和 𝑉𝑎𝑙𝑢𝑒(Value),初始化参数使用 𝐵𝑒𝑟𝑡(Bert)的后六层参数。

训练目标:ITC、ITM、MLM
-
ITC:图文对比学习,将单模态编码器输出的单模态向量映射到相同的低维空间中,通过对比损失对其单模态表示进行优化。
-
ITM:图文匹配学习
-
MLM:在下游应用中,图文检索:单独模态编码器检索 topK(粗排)+ 多模态编码器排序(精排)
优化点:hard negatives、Momentum Distillation
-
Hard Negatives
-
Momentum Distillation(去除文本中的噪声):用动量模型生成多个伪标签(动态更新的,每次可能都不一样,不同视角的伪标签),用伪标签监督对比学习和 MLM。

2.3.5、BLIP (2022)
Highlight:首次提出了一种既支持多模态理解又支持多模态写作的模型,并引入了一种名为 𝐶𝑎𝑝𝐹𝑖𝑙𝑡(CapFilt)的新方法。
Blip 和 ALBEF 有很多相似之处,这里主要讨论 Blip1.0,因为从 Blip2.0 开始,在处理跨模态时已经从对齐变为桥接,因此后文将讨论 Blip 的 2.0 版本。
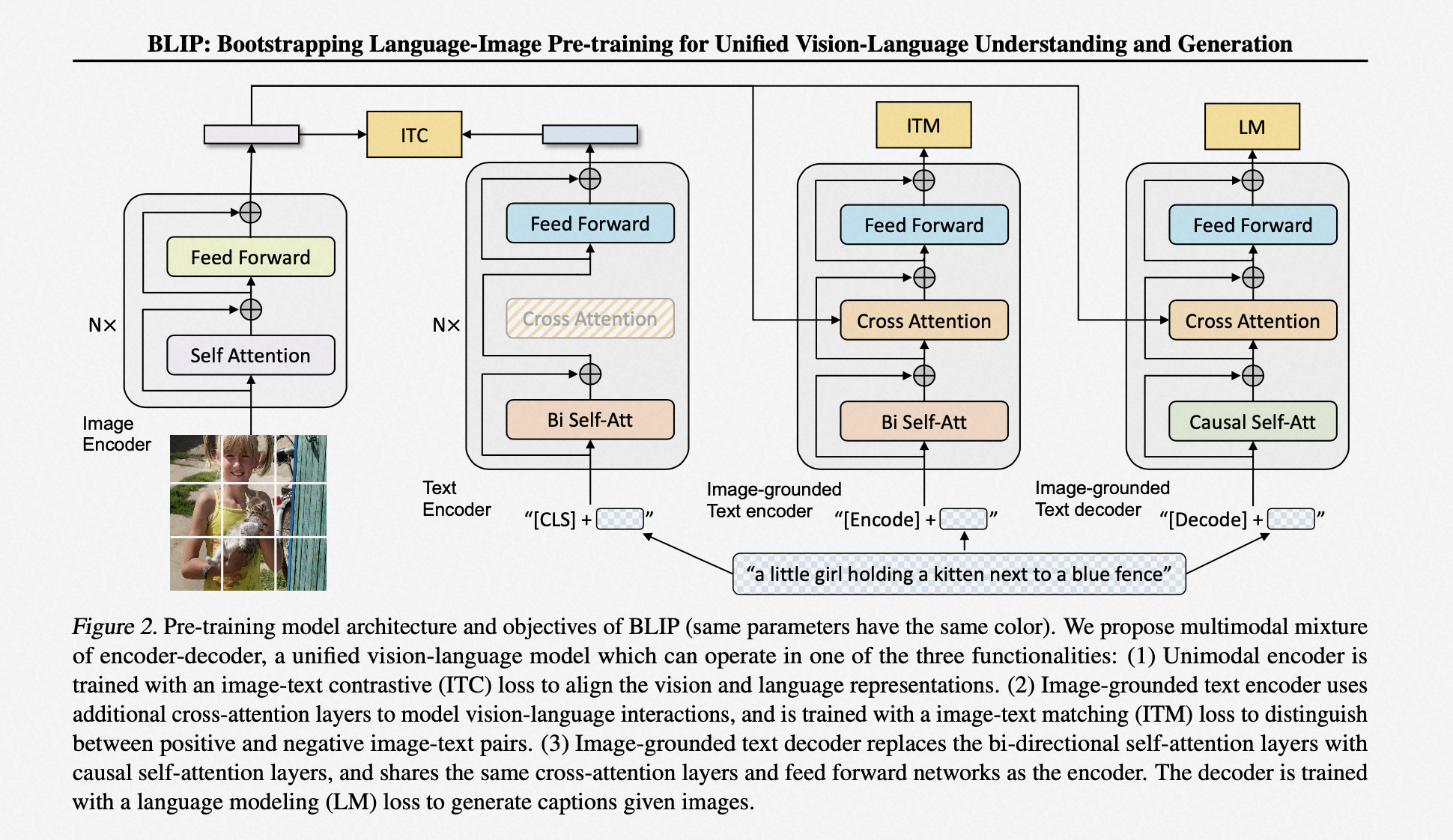
BLIP 由四个部分组成:一个视觉编码器(官方版本为 ViT)、一个文本编码器(基于 BERT 架构)、一个视觉-文本编码器和一个视觉-文本解码器。在训练过程中,BLIP 采用了类似对齐的方法,共同训练图像模态和语言模态。然而,与 CLIP 不同的是,BLIP 不仅使用 ITC Loss 来进行文本和图像的编码对齐,还通过一个名为 Cross Attention 的结构,实现了在同一个模型中视觉模态与文本模态的融合。通过图文匹配目标函数 ITM 和语言模型目标函数 LM 两个 Loss 目标进行训练,使得 BLIP 能够根据给定的图像以自回归方式生成关于文本的描述。
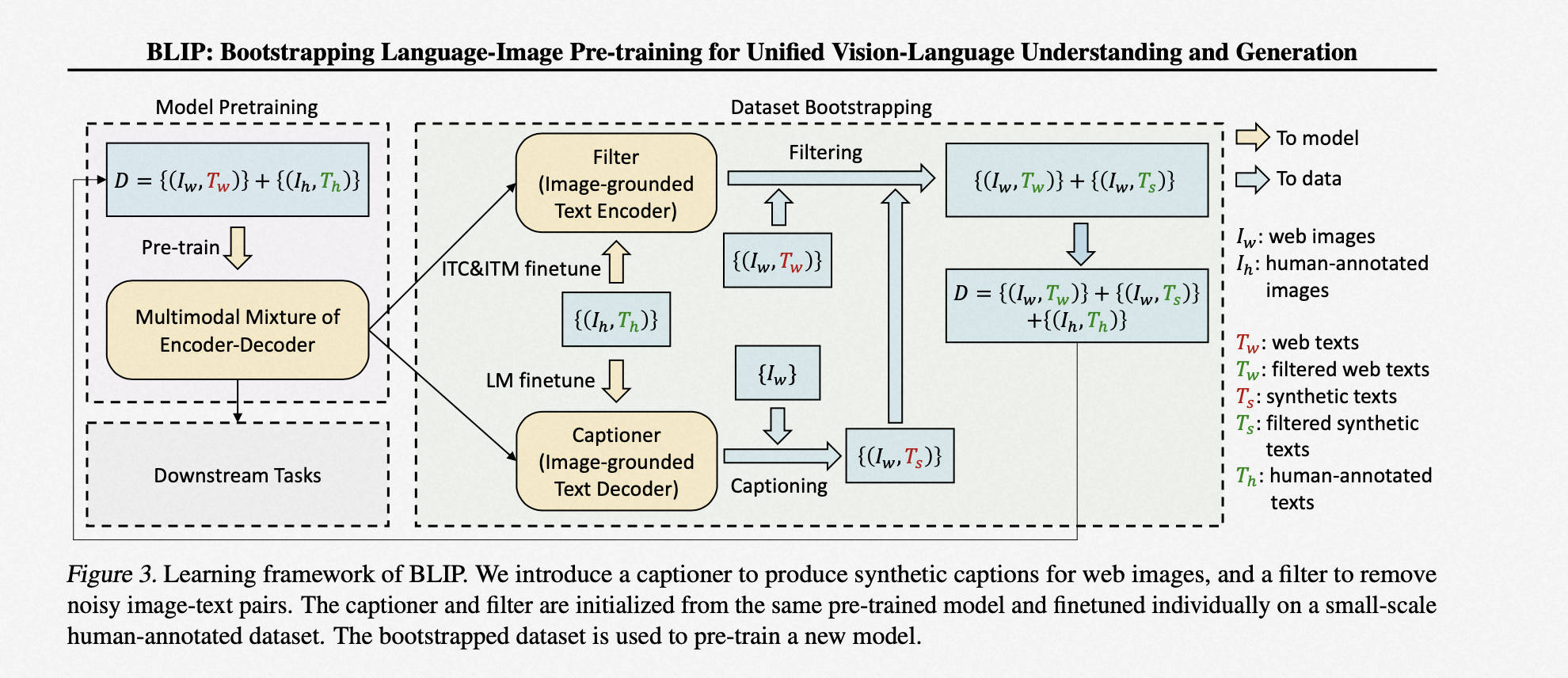
CapFilt 方法通过提取更干净的训练数据(知识蒸馏)来提升模型效果,具体步骤如下:
Step 1:使用大规模数据集预训练一个 BLIP 模型。
Step 2:通过人工少量标注,分别 finetune 两个子任务的高精度模型:
(1) Filter 模型:仅使用 ITC 和 ITM 损失进行训练
(2) Captioner 模型:仅使用 LM 损失进行训练
Step 3:使用 Filter 模型对数据集进行清洗,过滤掉其中的噪声。
Step 4:使用 Captioner 模型生成图像文本,再用 Filter 模型对生成的结果进行清洗。
Step 5:使用 Step 3 和 Step 4 得到的新数据集重新训练 BLIP 模型。
BLIP 同样具备 CLIP 的一些基本能力和优势(在单独联合使用视觉编码器和文本编码器时),同时基于其新的视觉-文本编码器和解码器,BLIP 可以实现图片生成文本和 VQA 的相关任务。
整体而言,BLIP 是一个多模态大语言模型和图文对齐模型的中间态。在单纯的语言理解能力上,BLIP 比大语言模型和后续的 BLIP2.0 要弱很多,而如果只是用基本的图文对齐能力,BLIP 又显得非常笨重,因此在工业界,BLIP1.0 的使用并不多。然而,Cross Attention 的成功应用和其训练过程中的一些独特技巧,使得后续相关模型受益匪浅。
2.4、跨模态桥接模型与多模态大语言模型
随着大语言模型(LLM)的广泛应用,人们开始相信基于大语言模型的路线可以催生出所谓的万用模型(OFA)。大语言模型的强大能力使得各类智能体(agent)开始以 LLM 为核心。因此,除了对齐方法之外,处理跨模态数据的另一种方法是将其他模态的数据表征转换后接入大语言模型,这种方法被称为桥接。
在使用桥接方法处理跨模态数据时,处理语言模态的 LLM、处理其他模态的表征编码器以及在两者之间起转换作用的桥接器通常不会同时进行训练,而是在不同训练阶段冻结其中某一个或一些部分,只训练其中一部分。根据桥接器的不同设计,这类模型可以分为两类:
基于可学习接口(Learnable Interface)进行桥接:这种方法在其他模态的输出和 LLM 的输入之间设置一个可训练的深度学习转换器,将其他模态编码器输出的向量转换为大语言模型可以接收的输入。目前大部分多模态大语言模型(MLLM)都采用这种方法,最早由 BLIP2 提出。
基于自然语言文本进行桥接:这种方法也被称为专家模型桥接器。它引入一个专家模型,将视觉等其他模态输入转换为自然语言或其他结构化文本描述,再输入 LLM。这种方式减少了可学习接口的成本开销和训练复杂性。然而,人类语言在描述许多内容时会出现信息丢失的问题,因此这种方法一般不用于图片生成文本描述的任务。不过,如果需要利用 LLM 的思维链(CoT)能力对图像内容进行推理,基于自然语言进行桥接就更加常用。
2.4.1、BLIP2 (2023)
BLIP2 由 Salesforce 于 2023 年 1 月发布。与 BLIP1.0 不同,BLIP2 在处理跨模态时采用了桥接的方式,将图像输出的表征信息传递给大语言模型。BLIP2 使用了一种名为 Q-Former 的可学习接口(Learnable Interface)类型的桥接器,这个桥接器同时输入文本和图像表征信息,并使用 Cross Attention 作为图文融合编码器的基本结构。
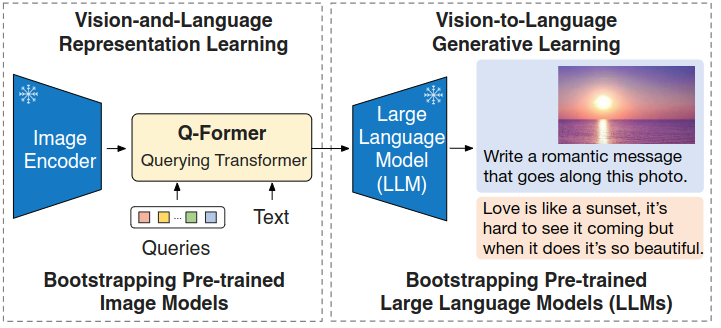
Q-Former 桥接器整合了图像和文本两个模态的输入信息后,最终会输出一个向量 Z。然后,经过一个全连接层对齐下游 LLM 的 token 窗口大小后,将 Z 和输入的文本信息一同交给 LLM。这样,LLM 就能够理解图像的内容特征与文本之间的对应关系,从而实现 VQA 等基于图像和文本的多模态联合推理任务。
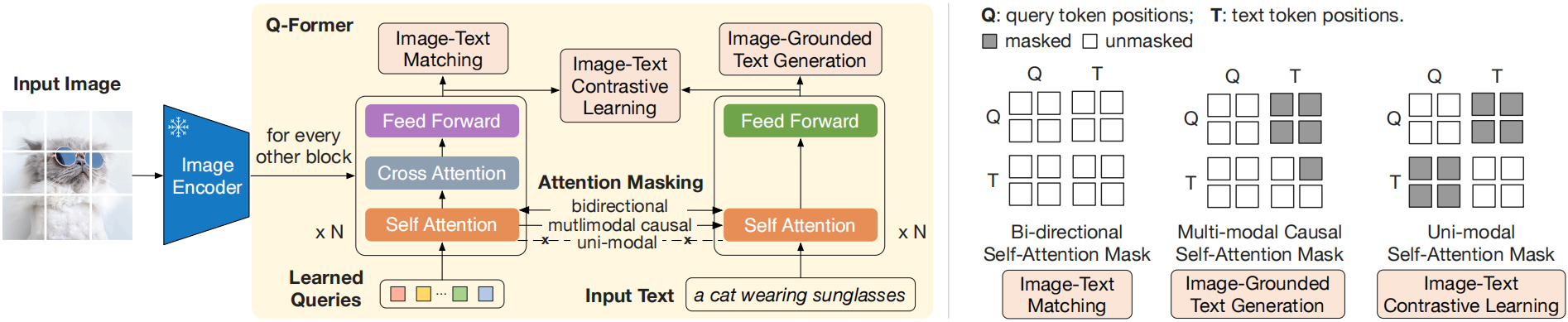
左侧展示了 Q-Former 和 BLIP-2 在第一阶段的视觉-语言表示学习目标的模型架构。右侧展示了每个目标的自注意力掩码策略,用于控制查询与文本的交互。优化了三个目标,这些目标强制一组可学习的查询嵌入提取与文本最相关的视觉表示。
Q-Former 包含两个关键子模块:图像变换器(Image Transformer)和文本变换器(Text Transformer):
图像变换器:与冻结的图像编码器进行交互,负责提取视觉特征。
文本变换器:既能充当文本编码器,也能充当文本解码器,处理文本信息。
在表示学习阶段,我们将 Q-Former 连接到一个冻结的图像编码器,并使用图像-文本对进行预训练。目标是使 Q-Former 学会通过查询提取与文本最相关的视觉表示。受到 BLIP(Li 等人,2022年)的启发,我们联合优化了三个预训练目标,这些目标共享相同的输入格式和模型参数。每个目标采用不同的注意力掩码策略来控制查询和文本之间的交互。
针对 Q-Former 的三个训练任务分别是 Image-Text Contrastive Learning(ITC),Image-grounded Text Generation(ITG),Image-Text Matching(ITM)。
Image-Text Contrastive Learning(ITC):图像-文本对比学习(ITC)旨在通过最大化图像表示和文本表示之间的交互信息来实现它们的对齐。这一过程通过比较正样本对(匹配的图像和文本)与负样本对(不匹配的图像和文本)之间的相似度来完成。
Image-grounded Text Generation(ITG):图像引导的文本生成(ITG)通过训练Q-Former模型,在给定图像作为条件的情况下生成相关文本。
Image-Text Matching(ITM):图像-文本匹配(ITM)的目标是精确地对齐图像与文本的表示。这一任务被视为一个二分类问题,其中模型需要判断给定的图像和文本是否相匹配(正样本)或不匹配(负样本)。
BLIP2.0继承了BLIP1.0的部分训练技术和优势,例如在使用图像表征编码器和Q-Former进行单独操作时,它也能有效执行多模态检索任务,并展现出良好的性能。此外,在视觉问答(VQA)、图像文本描述等任务中,BLIP2.0通过整合大型语言模型(LLM),在基于视觉输入的语言联合推理方面表现更加出色。因此,在多个领域,BLIP2.0常被用来为图像生成全面描述,例如在使用Stable diffusion进行Lora训练时,经常利用BLIP2.0对输入图像进行标注,生成图文对。
2.4.2、InstructBLIP (2023)
Highlight:把指令加到Q-Former中去,让图片也能看到指令。
InstructBLIP致力于解决视觉语言指令微调的挑战,并通过对Blip2模型进行微调及将指令集成到Q-Former中,不仅提升了指令微调效果,还增强了模型对图像内容的解读能力,同时系统研究了模型对未见数据和新任务的泛化能力,以提高其广泛应用的效率和效果。

-
视觉编码器首先提取输入图片的特征,并喂入Q-Former中,其中Q-Former的输入还包括BLIP-2采用的可学习的Queries和指令(Instruction)。
-
在Q-Former的内部结构中,如黄色部分所示,可学习的Queries通过Self-Attention与指令交互,并通过Cross-Attention与输入图片的特征交互,从而鼓励提取与任务相关的图像特征。
2.4.3、mPLUG (2022)
Highlight:mPLUG结构通过cross-model skip-connection解决图文不对称性,提升训练速度。

训练任务:ITC、ITM、MLM、PrefixLM
预训练数据(1400万):
- 域内数据集:MS COCO、Visual Genome
- 网络数据集:Conceptual Captions、Conceptual 12M、SBU Captions
训练GPU:16个A100、30 epochs
初始化配置:
- ViT:Clip-VIT
- Text-Encoder:Bert_base前6层
- Cross Skip Connection:Bert_base后6层
2.4.4、LLaVA
LLaVa是一种基于Learnable Interface的MLLM,用于实现图像-文本桥接。与BLIP2不同的是,LLaVa使用的桥接器是一个简单的投影层,它将视觉编码器的编码结果投影到LLM的token embeddings空间中。因此,LLaVa无需使用BLIP2中那样复杂的Q-Former来处理多模态融合表征。

这种多模态LLM通常被称为Projection Based Adaptor MLLM,例如minigpt4也采用了类似的架构。这类模型具有多模态层适配训练简单、图像信息保留全面等优点。然而,它们的缺点在于,仅适用于视觉问答(VQA)等生成式任务,不能用于多模态图文检索等任务。
2.4.5、minigbt-4 (2023)
冻结:Vicuna + VIT(Blip2) + Q-Former(Blip2)
训练:Linear Layer
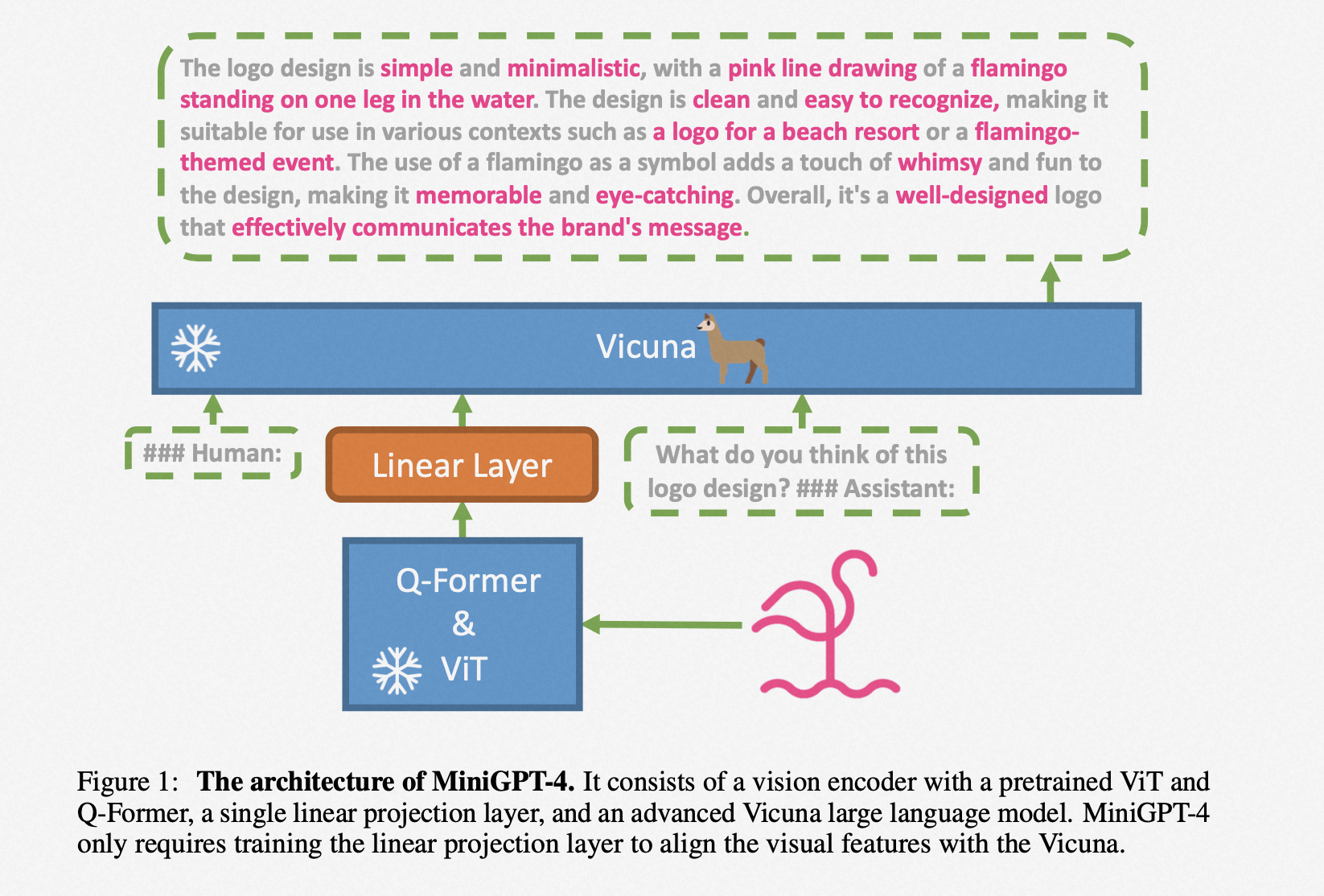
训练分为两个阶段:
| 描述 | 第一阶段 | 第二阶段 |
|---|---|---|
| 数据量 | 500万 | 3500个高质量对话数据 |
| GPU配置 | 4张A100 | 1张A100 |
| 训练时长 | 10小时 | 7分钟 |
| 批处理大小 | batch_size=256 | batch_size=12 |
在第一阶段中使用的大量数据可能包含脏数据,这对大模型可能造成损伤。为了获得高质量的模型,必须使用高质量数据集进行微调(finetune)。
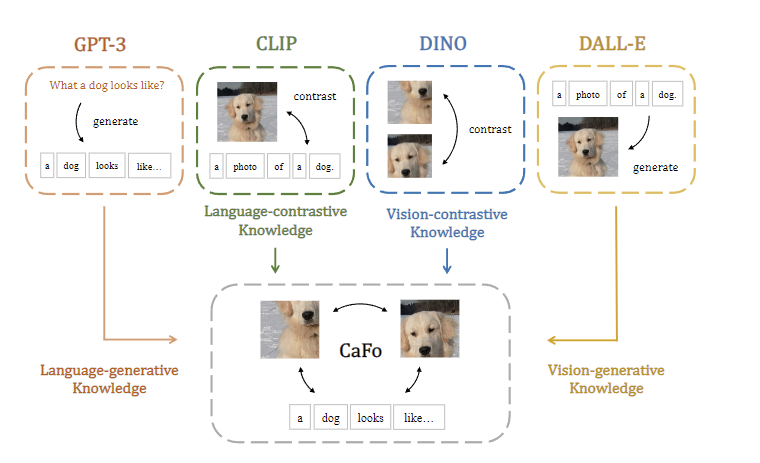
2.4.6、CaFo
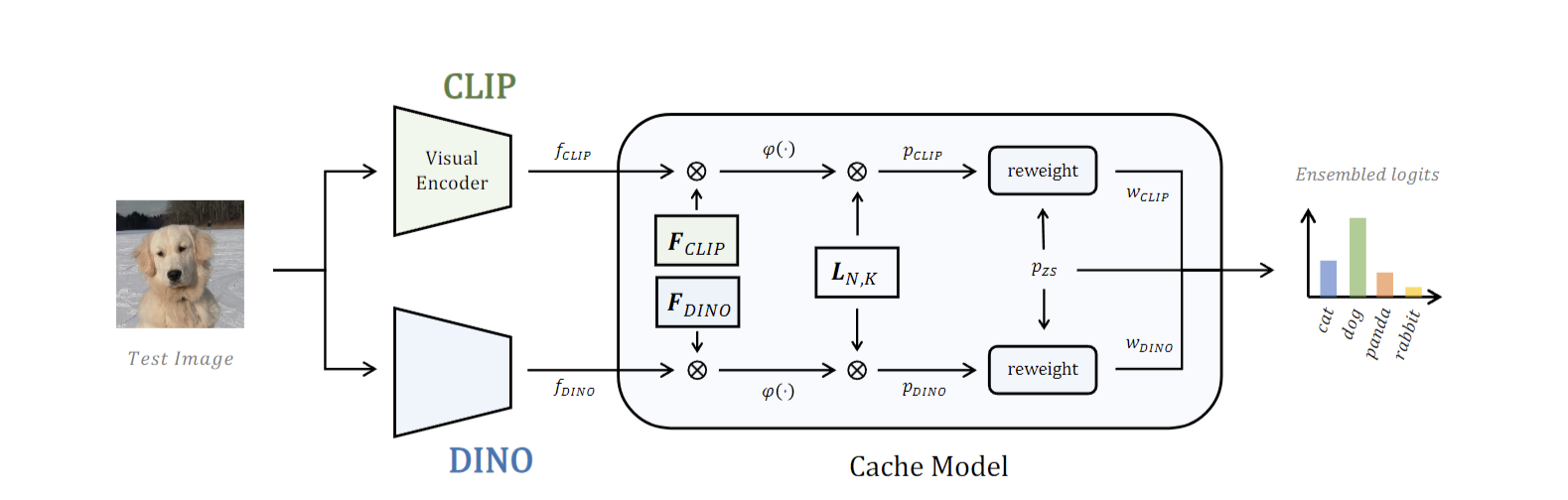
CaFO是由上海AI Lab提出的一个多模态大语言模型(MLLM)任务框架。该模型融合了CLIP、DINO、DALL-E和GPT-3等多个模型的特点,旨在通过自然语言输入的方式构建MLLM。CaFO利用了CLIP的语言对比知识、DINO的视觉对比知识、DALL-E的视觉生成能力和GPT-3的语言生成能力。通过“Prompt、Generate、then Cache”的策略,CaFO能够实现卓越的few-shot性能。
CaFo模型的一个显著特点是,它通过一个缓存模型(Cache Model)来记录CLIP和DINO的输出。这个缓存模型将CLIP和DINO的预测结果各自转换为两个向量,并计算这些向量与两个键(keys)的相似度。缓存模型采用一个可学习的权重参数,自适应地融合这两个键的相似度,从而得到最终的预测结果。
2.4.7、Qwen-VL (2023)
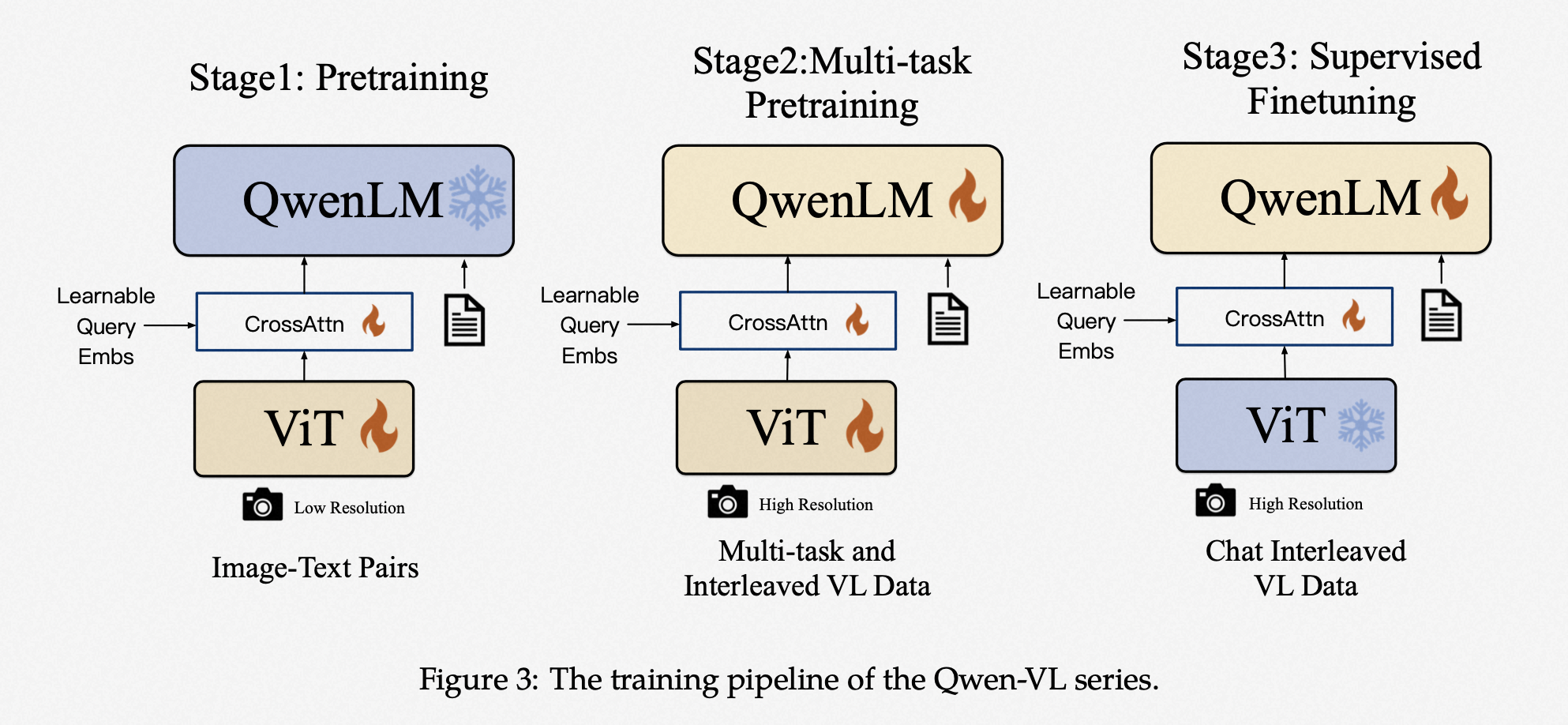
模型分为三个部分:
- LLM(7.7B):采用预训练的Qwen-7B。
- Visual Encoder(1.9B):使用Openclip的Vit-bigG。
- Position-aware Vision-Language Adapter(0.08B):结合可学习的Query-emb和位置信息。
模型训练分为三个阶段:
| 训练阶段 | 训练模块 | 数据集 | 大小 | 训练步数 |
|---|---|---|---|---|
| 第一阶段(预训练) | 冻住QwenLM,训练ViT、Vision-Language Adapter | 清洗后的大规模网络数据+内部数据,77%英文数据,22.7%中文数据 | 1.4B | 50000 step |
| 第二阶段(多任务训练) | 训练ViT、Vision-Language Adapter、QwenLM | 高质量、细粒度数据 | 76.8M | 19000 step |
| 第三阶段(监督微调) | Qwen-VL -> Qwen-VL-chat | 冻住VIT,训练Vision-Language Adapter、QwenLM | 35万 | 3000 step |
3、多模态大模型让AIGC更给力
视觉大模型提高AIGC感知能力
视觉数据,包括图像和视频,是当代信息传递的主要载体之一,它们实时记录着物理世界的状态,反映人类的思想、观念和价值观。在深度学习的背景下,传统的基于深度神经网络的模型,如深度残差网络(ResNet),通常针对单一的感知任务设计,难以同时处理多种视觉任务。相比之下,大模型能够帮助AIGC技术在不同场景、环境和条件下解决视觉感知问题,实现鲁棒、准确和高效的视觉理解。近年来,基于Transformer的大模型,如Swin Transformer和ViTAE Transformer,通过无监督预训练和微调策略,在多个视觉任务上展现出优越的性能,有望成为基础视觉模型(Foundation Vision Model),显著提升感知能力,推动AIGC领域的发展。
语言大模型增强AIGC认知能力
语言和文字是记录人类文明的重要方式,它们记录了人类社会的历史变迁、科学文化和知识。基于语言的认知智能有助于加速通用人工智能(AGI)的发展。在当前信息复杂的环境中,数据质量不一、任务种类繁多,存在数据孤岛和模型孤岛问题,传统深度学习在自然语言处理方面存在明显不足。谷歌和OpenAI提出的大规模预训练模型BERT和GPT,在多个自然语言理解和生成任务上取得了突破性进展,这已经为大家所熟知。
多模态大模型升级AIGC内容创作能力
在日常生活中,视觉和语言是两种最常见且重要的模态。视觉大模型可以构建出更强大的环境感知能力,而语言大模型则能学习到人类文明的抽象概念和认知能力。如果AIGC技术只能生成单一模态的内容,其应用场景将非常有限,不足以推动内容生产方式的革新。多模态大模型的出现使得融合性创新成为可能,极大地丰富了AIGC技术的应用广度。多模态大模型通过将不同模态的数据映射到统一或相似的语义空间中,实现不同模态信号之间的相互理解和对齐。基于多模态大模型,AIGC才能具备更接近人类的创作能力,并真正开始展示出替代人类进行内容创作、进一步解放生产力的潜力。
4、大模型不是谁都玩得起的
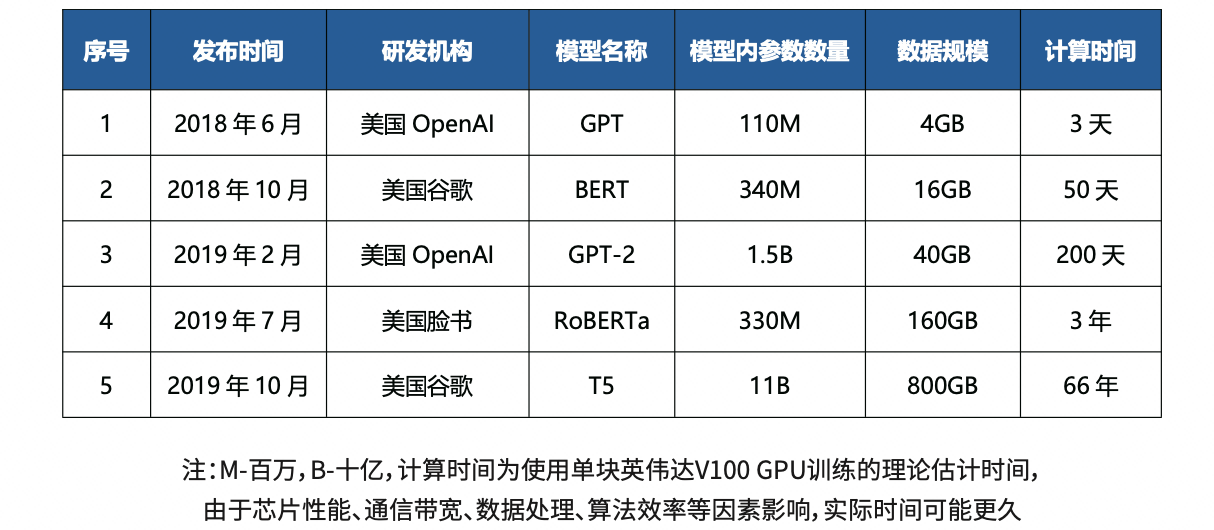
大模型的门槛较高,主要体现在参数量大、数据需求大和算力需求高三个方面:
参数: 语言大模型的参数规模从亿级到万亿级(以BERT为基准),而图像大模型的参数规模则在亿级到百亿级之间。模型参数越多,所需的存储空间也越大,相应的成本也随之增加。
在机器学习中,模型参数是定义模型功能的关键元素。以方程 aX1 + bX2 = Y 为例,X1 和 X2 是输入变量,Y 是输出结果,a 和 b 是模型的参数。这些参数是模型在训练过程中学习的值,用于调整模型的行为,使其预测结果尽可能接近实际数据。在更复杂的模型如神经网络中,参数的数量和复杂度会大幅增加,但基本概念相同:参数是通过训练数据调整的,以优化模型性能。
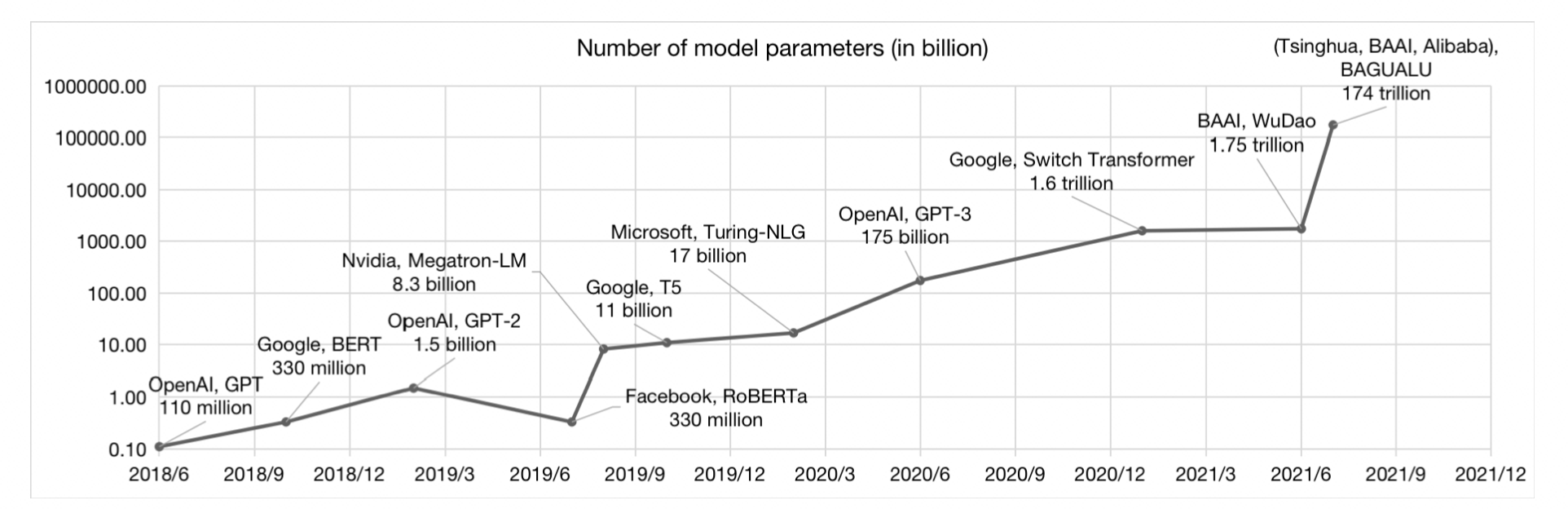
数据:随着模型参数的大幅增长,为了避免过拟合,需要更大量的数据来进行训练。传统的有监督学习方法由于标注成本高和训练周期长的限制,变得不太现实。因此,越来越多地采用自监督学习方法来挖掘数据中的信息。从2018年BERT的33亿词符,到2019年XLNet的330亿词符,再到2020年GPT-3的6800亿词符,数据量呈现出十倍的增长速度。到2022年,PaLM模型使用了7800亿词符进行训练。
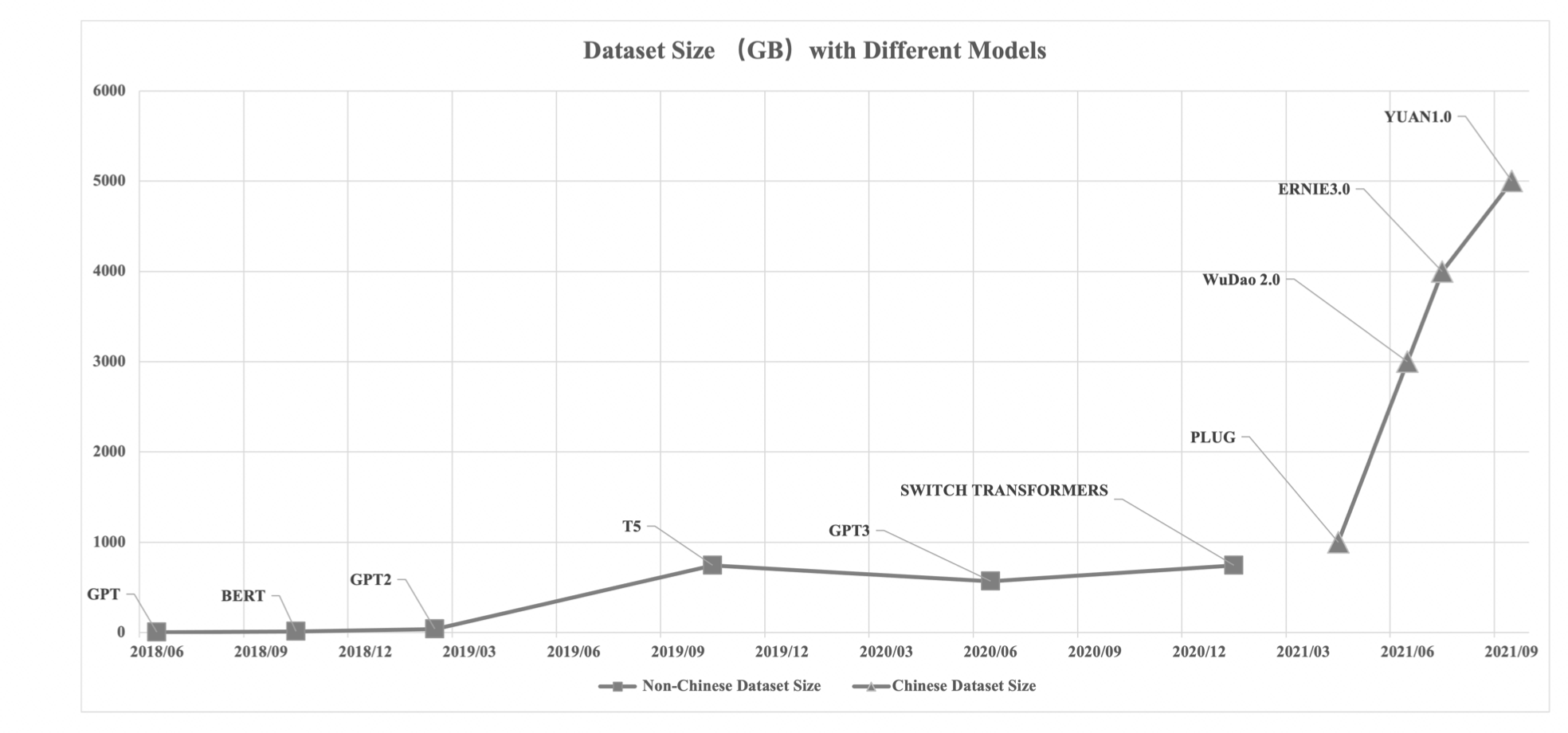
算力:在“小模型”阶段,尽管对算力的需求已经在增长,但使用一张GPU卡通常足以应对,这使得许多个人和小企业也能参与其中。然而,随着超大规模预训练模型的出现,巨大的参数和数据量对算力的需求已经远远超出了普通用户的能力范围。即使一个人构建了网络结构并获取了必要的数据,如果没有足够的计算资源,也无法进行有效的训练。
从算力需求的角度看,GPT的需求是18k petaFLOPs,GPT-3的需求增至310M petaFLOPs,而PaLM更是高达2.5B petaFLOPs。从成本角度来看,GPT-3的训练使用了数千块英伟达V100 GPU,总成本高达2760万美元。个人如果想要训练一个类似PaLM的模型,成本预计在900万到1700万美元之间,这显然是一笔巨大的投资,对于大多数个人和小企业来说是难以承担的。
5、未来的多模态发展畅想
5.1、当下:检索重构
随着大型语言模型(LLM)如GPT-4的发展,加入多模态信息成为了一种趋势。未来,大模型将会整合更多模态的信息,使得不同模态的数据能够映射到同一个向量空间中。这将带来一种“All you need is embedding”的新现象,即通过统一的嵌入表示来处理和理解多种类型的信息。这种方法预示着信息处理和机器学习领域的一大进步。
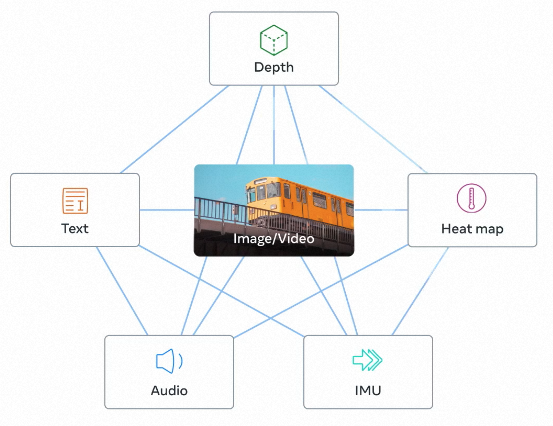
一个明显的趋势证明是在2023年5月10日,Meta开源了一款多模态大模型ImageBind。ImageBind能够将文本、音频、视觉、热量(红外)以及IMU数据整合嵌入到同一个向量空间中。这一技术的最大颠覆性创新首先体现在搜索领域,跨模态检索不再仅限于文本输入,而是支持多种模式的组合输入。随后,这还将极大地提升生成式检索的能力,能够生成包含多种信息维度的全方位内容。

ImageBind 通过将六种模态的嵌入对齐到一个公共向量空间中,支持跨模态检索不同类型的内容,并能自然地组合来自不同模态的嵌入以形成统一的语义。此外,它还可以利用音频嵌入和预训练的DALLE-2解码器处理CLIP文本嵌入,从而生成音频和图像。
“All you need is embedding”这一理念允许之前难以结构化的数据之间建立联系,实现万物向量化。这种特性使得不同数据之间可以进行计算、聚类、拓扑分析和检索。
想象以下几种场景:
- 你可以将一个音乐家敲击架子鼓的声音录入到淘宝中,然后搜索到相同款式的架子鼓。
- 你可以使用一张包含烟、酒和卷发的照片,在搜索引擎中找到郭德纲与于谦的经典相声。
- 你可以用脑海中对小时候和奶奶玩耍的记忆进行文字描述,最终在海量视频中找到那短短10秒的录像场景。
- 你可以用AI生成一幅美丽的风景画,然后将温度传感器放入冰水中,风景随之变为冬天的景象。
这些应用展示了多模态大模型如ImageBind在实际生活中的潜在用途,它们不仅增强了内容的创造和检索能力,还为人机交互提供了新的可能性。
5.2、未来:模态大一统
多模态不仅包括图像、视频和声音,还涵盖了多种感官体验,如触觉、味觉等。这些多样的感觉模态为我们提供了更全面的世界理解和交互方式。
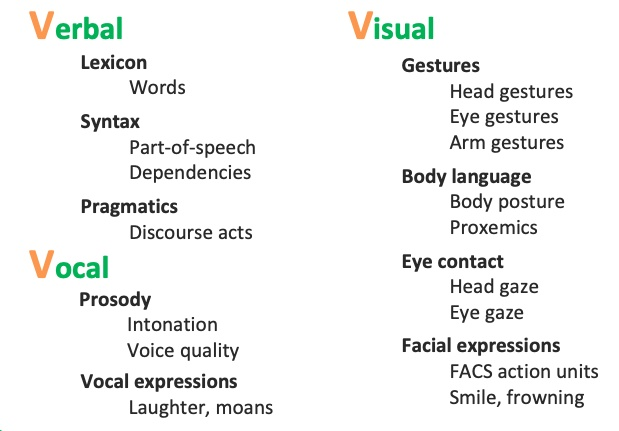
即使是人与人交流中主要研究的"3V"模态——Verbal(文本)、Vocal(语音)、Visual(视觉),其中也蕴含了极其丰富的细节。这些细节不仅包括信息的直接表达,还涉及到非言语的交流元素,如语调、表情和肢体语言,这些都极大地丰富了交流的深度和广度。
这些额外的模态和细节,目前还因缺乏适配的输入输出设备而难以全面实现。如果存在一种设备能够整合不同模态的输入输出,那将真正地颠覆现实。这也许解释了为什么公司如Meta不遗余力地发展多模态技术,可能是为了构建那个被广泛讨论的元宇宙。
想象以下场景:
- 你通过脑电波输入设备,利用脑海中的想象构建出了属于自己的“我的世界”。在这个世界里,你可以以上帝视角操控一切,也可以身临其境地进入某个NPC的意识,体验他的一天。
- 你通过长时间的文字输入和语音对话,构建了一个专属于你的虚拟朋友。这个朋友在各方面都完美地符合你的喜好,并且能够在与你相处的过程中进一步学习和适应。在这个设备中,你与他的互动就像与现实生活中的人无异:能感受到他手掌的温度,与他共进晚餐,感受他的情绪变化,甚至在你遇到困难时给予你倾听和实际的建议。面对这样的虚拟与现实的选择,你会倾向于哪一个? 这些技术的发展不仅推动了人类交互方式的革新,也引发了关于现实与虚拟界限的深刻思考。
1946年诞生了第一台计算机,到现在还不到百年时间。
2000年的NNLM到ChatGPT,不过23年。
距离“未来”的实现,还会遥远吗?
Reference
[1] He, Kaiming, et al. “Momentum contrast for unsupervised visual representation learning.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[2] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arxiv preprint arxiv:2010.11929 (2020).
[3] He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[4] Bao, Hangbo, et al. “Beit: Bert pre-training of image transformers.” arv preprint arv:2106.08254 (2021).
[5] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International conference on machine learning. PMLR, 2021.
[6] Jia, Chao, et al. “Scaling up visual and vision-language representation learning with noisy text supervision.” International conference on machine learning. PMLR, 2021.
[7] Li Y, Liang F, Zhao L, et al. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm[J]. arv preprint arv:2110.05208, 2021.
[8] Li, Junnan, et al. “Align before fuse: Vision and language representation learning with momentum distillation.” Advances in neural information processing systems 34 (2021): 9694-9705.
[9] Li J, Li D, ** language-image pre-training for unified vision-language understanding and generation[C]//International Conference on Machine Learning. PMLR, 2022: 12888-12900.
[10] Li, Chenliang, et al. “mplug: Effective and efficient vision-language learning by cross-modal skip-connections.” arv preprint arv:2205.12005 (2022).
[11] https://arxiv.org/pdf/2010.11929.pdf
[12]https://browse.arxiv.org/pdf/2103.00020.pdf
[13] https://arxiv.org/pdf/2304.08485.pdf
[14] https://www.listendata.com/2023/03/complete-guide-to-visual-chatgpt.html
[15] https://arxiv.org/pdf/2306.02858v2.pdf
[16] Geo-Tile2Vec: A Multi-Modal and Multi-Stage Embedding Framework for Urban Analytics
[17] Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
[18] VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
[19] https://browse.arxiv.org/pdf/2303.05499v4.pdf
[20] ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
[21] On the Opportunities and Risks of Foundation Models
[22] Human-Language-Understanding-amp-Reasoning
[23] Scaling Laws for Neural Language Models
[24] Emergent Abilities of Large Language Models
[25] Improving Language Understanding by Generative Pre-Training
[26] Language Models are Few-Shot Learners
[27] Language Models are Unsupervised Multitask Learners
[28] Training language models to follow instructions with human feedback
[29] Deep double descent: where bigger models and more data hurt
[30] https://arxiv.org/pdf/2109.01134.pdf
[31] https://arxiv.org/abs/2204.09331
[32]https://browse.arxiv.org/pdf/2306.00890v1.pdf