Text-2-SQL:从Prompt到Finetune
1、LLM技术在Text-to-SQL上的现状
Text-to-SQL解决方案在大型语言模型(LLM)的支持下得到了广泛应用,但是现有的提示工程方法缺乏系统性,阻碍了该领域的发展。
为了更深入地探讨基于LLM的Text-to-SQL解决方案的提示工程系统化研究,我们需要全面理解和实践,覆盖了不同的LLM、问题表示、示例选择和组织策略,以探索如何与LLM良好配合。具体而言,提示工程分为zero-shot和few-shot场景,在zero-shot场景中,需要研究如何有效地表示自然语言问题,包括融入相关信息如相应数据库模式。在few-shot场景中,有限的示例可供使用,因此需要研究如何选择最有帮助的示例,并恰当地组织到提示中。
本文还探讨了LLM的上下文学习过程,并研究了zero-shot和few-shot场景中LLM的表现,同时也展示了有监督微调方法的利与弊。本文为基于大型语言模型的Text-to-SQL解决方案的系统化研究提供了有益的参考和指导。
2、问题表示
这里的问题表示是指针对Text-to-SQL任务,设计一个高效的Prompt去激发LLM的Text-to-SQL能力,本质上就是Prompt工程。在zero-shot场景中有五花八门的Prompt模版,这里展示现有文献中四个最具代表性的。此外,再展示一个在 Alpaca中使用的Prompt模板,因为它在监督式微调中非常受欢迎。下表总结了这五种方法:
| 问题表示 | INS | RI | FK | LLMs | EM |
|---|---|---|---|---|---|
| $\text{BS}_P$ | x | x | x | - | - |
| $\text{TR}_P$ | $\checkmark$ | x | x | Code-Davinci-002 | 69.0 |
| $\text{OD}_P$ | $\checkmark$ | $\checkmark$ | x | GPT-3.5-Turbo GPT-4 | 70.1 |
| $\text{CR}_P$ | $\checkmark$ | x | $\checkmark$ | Code-Davinci-002 GPT-3.5-Turbo | 75.6 |
| $\text{AS}_P$ | $\checkmark$ | x | x | - |
EX:SQL执行准确率、INS:指令(任务描述)、RI:规则信息(指导性语句,比如“仅输出SQL语句,无需解释”)、FK:外键(数据库的外键信息)
2.1、基本提示
基本提示(Basic Prompt)是一种简单的Prompt模板,它由表模式、以 Q: 为前缀的自然语言问题、以及提示LLM生成SQL的响应前缀 A:SELECT 组成。之所以命名为基本提示,是因为它并未包含任何指令内容。

Table table_name1, columns = [column1, column2, ...]
...
Table table_name2, columns = [column1, column2, ...]
Q: The question
A: SELECT...(目标SQL)
2.2、文本表示法提示
文本表示法提示(Text Representation Prompt)相比于基本提示,它在提示的开头添加了指导LLM的指令。在零样本场景中,它能在 Spider-dev 上实现了69.0%的执行准确率。
The Instruction(e.g. Given the following database schema: )
Table table_name1, columns = [column1, column2, ...]
...
Table table_name2, columns = [column1, column2, ...]
Answer the following: The question...
SELECT...(目标SQL)
2.3、OpenAI 示范提示
OpenAI示范提示(OpenAI Demostration Prompt)首次在OpenAI的官方Text-to-SQL演示中使用,它由指令、表模式和问题组成,其中所有信息都用“#”进行注释。与文本表示提示相比,OpenAI示范提示中的指令更具体,而且还有一条规则约束,“仅完成sqlite SQL查询,无需解释”。

### The Instruction
# SQLite SQL tables, with their properties:
#
# table_name1(column1, column2, ...)
# ...
# table_name2(column1, column2, ...)
#
### The question...
SELECT...(目标SQL)
2.4、代码表示提示
代码表示提示(Code Representation Prompt)是一种基于SQL语法实现Text-to-SQL任务的方式。具体来说,它直接将表创建语句“CREATE TABLE …”放到Prompt中。相较于其他的问题表示方法,代码表示提示的独特之处在于,它能够提供创建数据库所需的全面信息,例如列名、列类型、主键/外键等。在这样的表示方式下, Code-Davinci-002能够正确预测约75.6%的SQL。

/* Given the following database schema: */
CREATE TABLE table_name1(
column1 type primary key,
column2 type,
foreign key(column3) references table_name2(xxx)
);
CREATE TABLE table_name2(
column1 thpe primary key,
column2 type,
foreign key(column3) references table_name1(xxx)
);
/* Answer the following: The question...
SELECT...(目标SQL)
2.5、Alpace指令微调提示
Alpace指令微调提示(Alpaca SFT Prompt)是一种用于监督微调的提示方式,它指导LLM按照指示并根据Markdown格式上下文来完成任务。后面在检验监督微调场景中的效果时就采用的是此提示模板。

The description of the Text-to-SQL Task
### Instruction:
Write a sql to answer the question "The question"
### Input:
table_name1(column1, column2, ...)
...
table_name2(column1, column2, ...)
### Response:
SELECT...(目标SQL)
以上问题表示方法使大型语言模型(LLM)能够通过zero-shot学习直接输出所需的SQL。然而,在Test-to-SQL任务中,LLM通过上下文学习可以表现更出色,而这只需要在问题表示中提供了少量示例即可。
3、Text-to-SQL的上下文学习
在上下文学习中,Text-to-SQL 涉及两个子任务:选择最有帮助的示例、将这些选定的示例组织到问题表示里面去,分别称作“示例选择(Example Selection)”和“示例组织(Example Organization)”。
3.1、示例选择
示例选择(Example Selection)在先前的研究中主要有以下几种策略:
-
随机选择(Random):此策略随机采样$k$个可用候选的示例$Q$,现有的工作已经将其作为示例选择的基准方案。
-
问题相似性选择(Question Similarity Selection):此方案选择与目标问题$q$最相似的$k$个示例。具体来说,使用预训练的语言模型(比如BERT等)将示例问题$Q$和目标问题$q$嵌入到同一个向量空间。然后,计算每个<示例问题, 目标问题>对应用预定义的距离度量,如欧氏距离或负余弦相似度。最后,利用𝑘近邻(KNN)算法从$Q$中选择$k$个与目标问题$q$相近的示例。
-
遮蔽问题相似性选择(Masked Question Similarity Selection):对于跨领域Text-to-SQL,遮蔽问题相似性选择通过使用掩码标记(MASK)替换所有问题中的表名、列名和值,从而消除领域的特定信息,然后使用最近邻算法计算其嵌入向量的相似性。
-
查询相似性选择(Query Similarity Selection):此方案不是计算文本问题之间相似度,而是选择与目标SQL查询最相似的𝑘个示例。具体来说,首先初步使用模型将目标问题$q$转换成SQL语句,然后选择与此SQL最相似的$k$个示例。
上述策略重点是仅使用目标问题或目标SQL来选择示例。然而,上下文学习本质上是通过类比进行学习。在Text-to-SQL的情况下,目标是生成与给定问题匹配的查询,因此大型语言模型应该学习从问题到SQL查询的映射,所以在示例选择过程中,同时考虑目标问题和目标SQL可能更有助Text2SQL任务。
3.2、示例组织
示例组织(Example Organization)在决定上述选定的示例有哪些信息将被组织到问题表示中发挥了关键作用。目前已有的研究中示例组织策略可以总结为两个类别,即完整信息组织和仅SQL组织。在下面的例子中,DATABASE_SCHEMA表示数据库模式,TARGET_QUESTION表示目标问题表示。
-
完整信息组织(Full-Information Organization):此策略将示例组织成与目标问题相同的表示形式。如下图示,给出了两个示例问题及其SQL语句,示例的结构与目标问题表示完全相同,唯一的区别是,给定的示例在“SELECT”后有完整的SQL查询,而目标问题在最后只有“SELECT”标记。

-
仅SQL组织(SQL-Only Organization):在提示中仅包括选定示例的SQL语句,并在前缀中附加指示信息。这种组织方式旨在最大程度地利用有限的Token长度来包括示例数量。然而,它去除了问题和SQL语句之间的映射信息,而这些信息可能很有用,后面的实验也可以证明。

总之, 完整信息组织包含了示例的全部信息,以确保质量;而仅SQL组织仅保留 SQL 查询以便选择更多示例,侧重于数量。那么是否在示例组织中存在一种更好的质量与数量的权衡呢,这可以进一步优化Text-to-SQL任务。
4、一个新的Text-to-SQL方案:DAIL-SQL
为了解决上述的问题:仅使用目标问题或目标SQL的相似度来选择示例,一个新的Text-to-SQL方案DAIL-SQL被提出。对于示例选择,受到遮蔽问题相似性选择和查询相似性选择的启发,DAIL同时考虑了问题和查询来选择候选示例。具体来说,DAIL选择首先屏蔽了问题的领域特定词。然后,它根据问题之间的欧几里得距离对候选示例进行排名。同时,它计算了预目标SQL与候选示例SQL之间的相似度,并要求相似度大于预定的阈值。通过这种方式,选择的$k$个示例在问题和SQL上都具有很好的相似性。
除此之外,为了保留问题和SQL语句之间的映射信息并且提高Token效率,DAIL提出了一种新的示例组织策略:DAIL组织(DAIL Organization),以在质量和数量方面进行权衡。具体来说,如下图所示,DAIL组织包含了示例的问题和相应的SQL语句 ,作为完整信息组织和仅SQL组织之间的折中,DAIL组织保留了question-SQL映射,并通过去除数据库模式信息来减少示例的token长度。

在这种提示设计中,LLM 可以更好地应对 Text-to-SQL 任务,而在 Spider 排行榜中,DAIL-SQL 通过 86.2% 的执行准确率刷新了性能。
5、Text-to-SQL的监督微调
为了在zero-shot 场景中提高 LLM 的性能,现有的Text-to-SQL方法普遍采用的策略是上下文学习,这在上述小节中已有讨论。作为一种替代且富有潜力方案:监督微调,至今还鲜有探讨。与各种语言任务的监督微调类似,我们也可以将其应用于Text-to-SQL领域,以提高LLM在这个下游任务上的性能。后面将直接从实验结果展示监督微调的潜力及其利弊。
6、相关实验
6.1、问题表示
下图展示了数据集 Spider-dev 上的不同问题表示的比较。通过比较不同的表示,我们可以观察到 OD 适合所有三种 LLM,并在 GPT-3.5-TURBO 上实现了 75.5% 的执行精度。相比之下,AS 在 GPT-3.5-TURBO 和 TEXT DAVINCI-003 上表现不佳,需要合适的 LLM 才能发挥良好作用。出乎意料的是,GPT-4 对于简单 BS 表现出偏好,这表明强大的 LLM 可以减轻Prompt设计的复杂性。

外键(FK)表示不同关系表之间的关系,这可能有助于Text-to-SQL任务。在评估中,为了检查其效果,可以将外键信息添加到其他表示中,并在下图中对它们进行评估。观察到,外键信息显著提高了LLMs的执行准确性,提高了0.6%到2.9%。这种观察表明,外键对于文本到SQL任务是有帮助的。

规则信息(RI)。CR问题表示模板含有“仅输出SQL语句,无需解释”的规则。为了检查问题表示中“不解释”的规则的影响,下图中将其添加到其他问题表示中。可以观察到添加这一规则始终能够显著提高所有LLMs的效果,其中最显著的改进分别超过了6%和2%。

6.2、Text-to-SQL的上下文学习
-
示例选择:为了验证问题和SQL语句在示例选择中的重要性,我们计算了所选示例的问题和SQL与目标问题和SQL的 Jaccard 相似度。通过比较不同的选择策略,证明了DAIL通常优于其他策略。在 5-shot场景中,基于GPT-4的DAIL实现了 82.4% 的执行准确性。
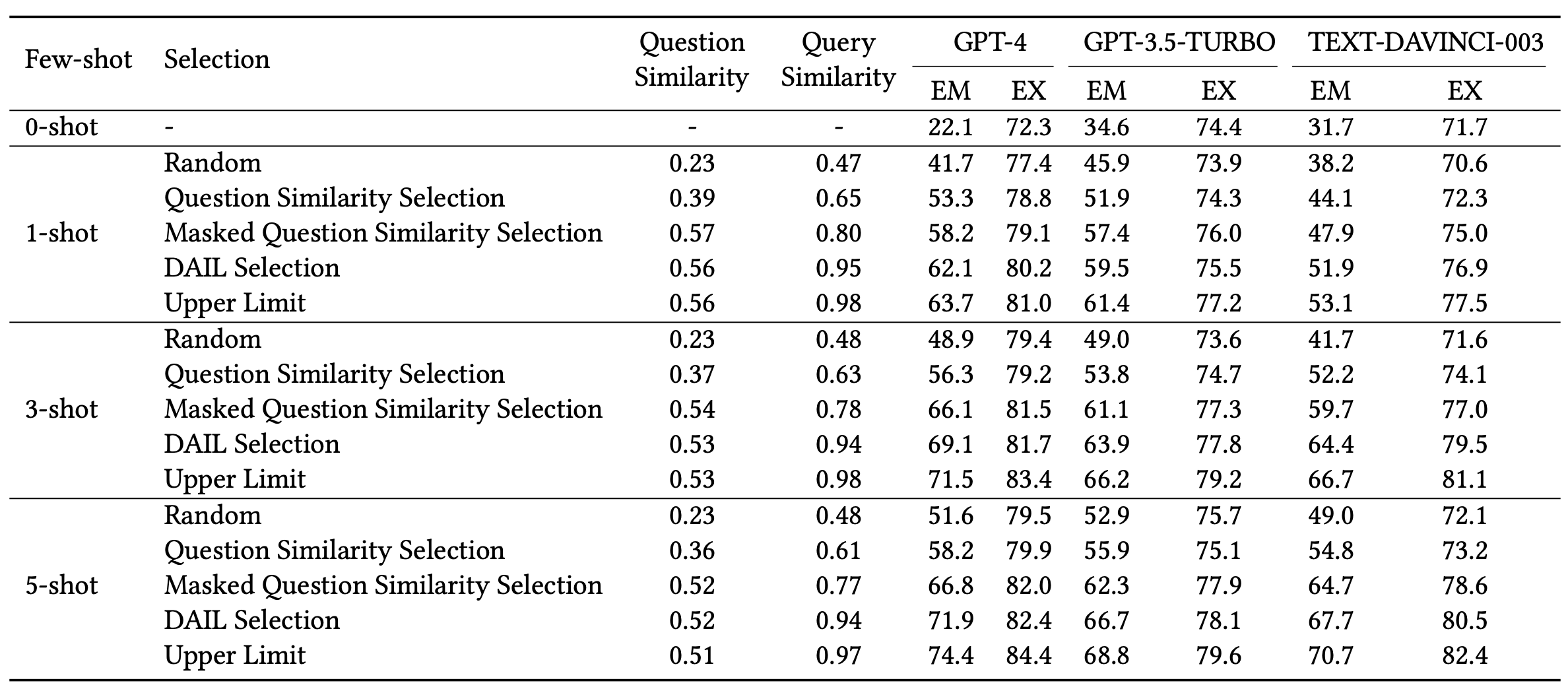
-
示例组织。为了比较不同的示例组织策略,在 Spider-dev 和 Spider-Realistic 上的少量示例场景中评估了全信息组织、仅 SQL 组织和 DAIL 组织。下图展示了比较结果,可以观察到使用 DAIL 组织,其在 Spider-dev 上的执行准确率从 72.3% 提高到 83.5%,在 Spider-Realistic 上的执行准确率从 66.5% 提高到 76.0%。
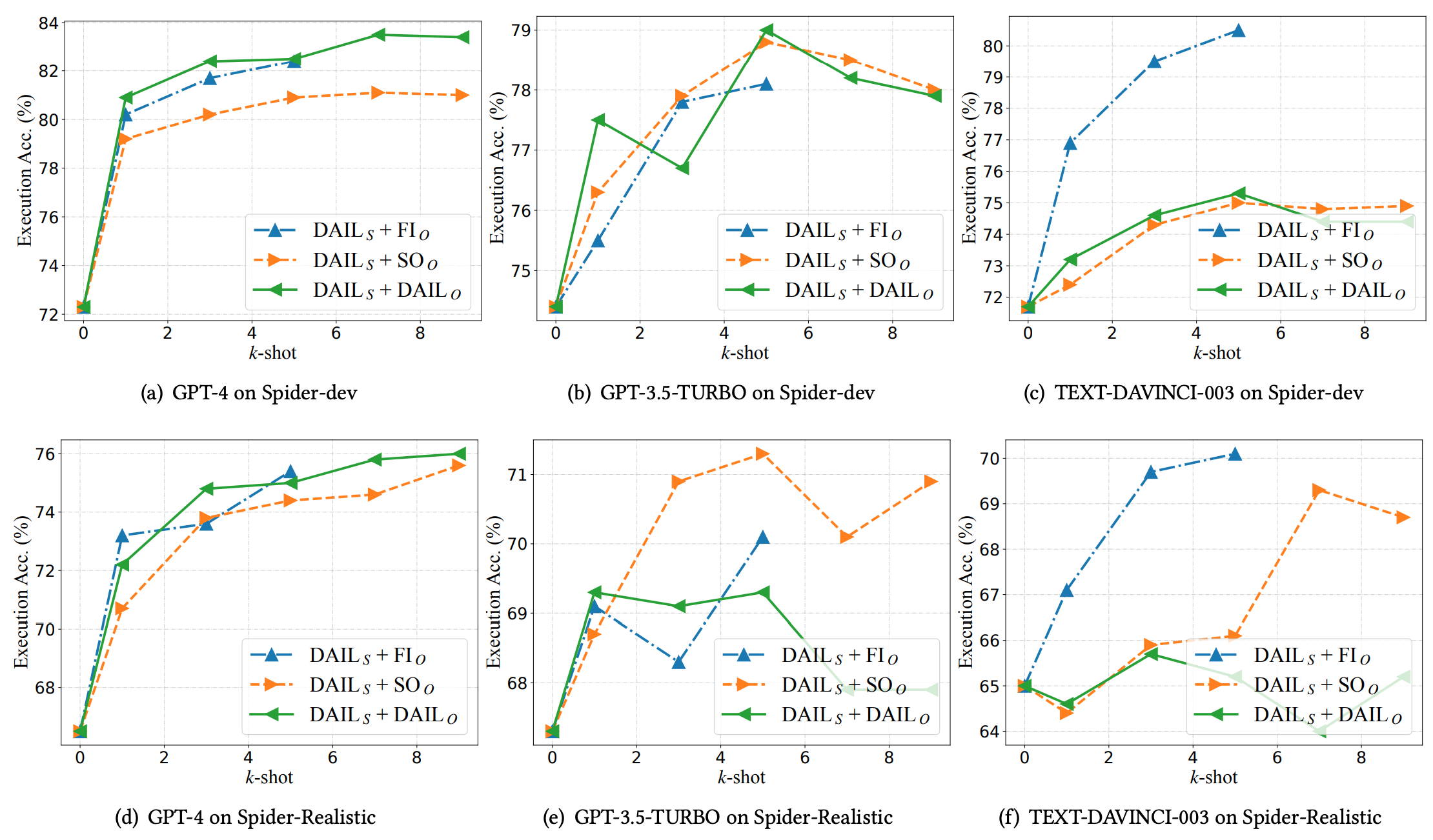
6.3、Text-to-SQL的监督微调
- Zero-shot场景:下图展示了在Zero-shot场景中,使用各种 LLM 和问题表示的监督微调性能。与微调前的性能相比,它们的性能得到了显著提升。通过比较不同的表示,可以看出 Alpaca SFT 提示在监督微调中具有明显优势,因为它是为这种场景设计的。

- Few-shot 场景:经过监督微调后,一个重要问题是:我们能否通过添加上下文示例继续提高开源 LLM 的性能?为了回答这个问题,下表用 0、1、3 和 5 样本提示评估微调后的 LLaMA-7B 和 13B,以便进行清晰比较。出乎意料的是,微调后的 LLM 无法从示例中学习。具体来说,在测试提示中添加上下文示例会导致准确率突然下降,并且添加再多示例也无济于事。可能的原因是 LLM 对Prompt提示过拟合,使得示例变得无用。
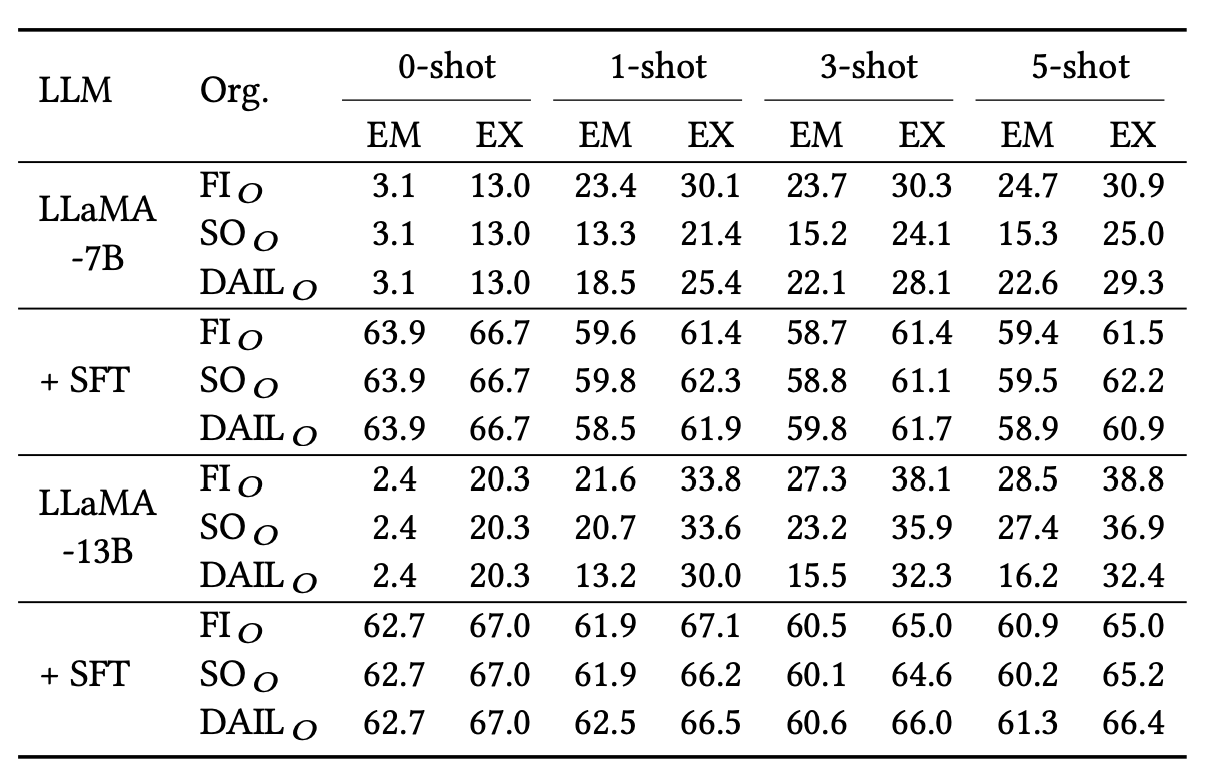
总之,开源 LLM 在文本到 SQL 任务中显示出巨大的潜力,尤其是在监督微调方面。具体来说,经过微调后,它们的性能在zero-shot场景中可与 TEXT-DAVINCI-003 相媲美。然而,与 OpenAI 的 LLM 不同,微调后的 LLM 无法从上下文示例中学习。在微调后如何保持上下文学习能力的问题还有待于未来的研究探索。